
まずはMulti-media Efficiency。グラフ68~70がBest Pair(少ないLatencyのコア同士の通信)、グラフ71~73がWorst Caseとなる。
Best Case
Best Caseはグラフ68がOverallである。一番コアの少ないRyzen 7 2700XがBandwidthも少ないが、Latencyも一番少ない。逆にコアが一番多いRyzen Threadripper 2990WXが、BandwidthもLatencyも大きいのはまぁわかる。興味深いのは、Ryzen Threadripper 1950X vs 2950Xで、2950XのほうがわずかにBandwidthが増え、Latencyが30nsほど減っているのは、やはりZen+コアに切り替えたことによるものだろう。
-
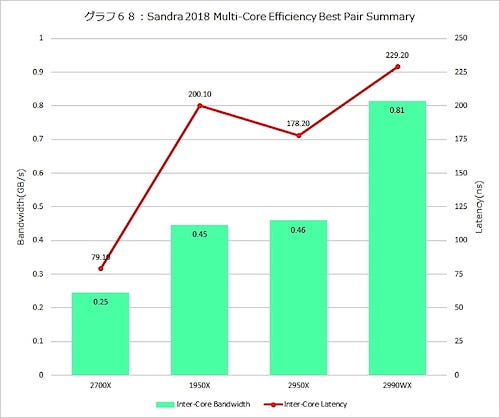
グラフ68

実際のBandwidthの変化を転送サイズ別に見たのがグラフ69。Ryzen Threadripper 1950X vs 2950Xの差は、おもにL1~L2の範囲で、L3以上になると誤差の範囲という感じになってくるのは興味深い。
-
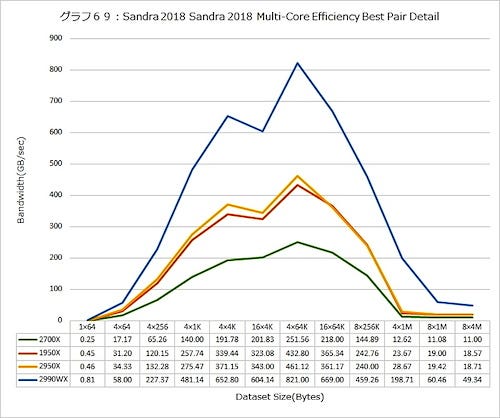
グラフ69

グラフ70はLatencyの分布である。L1の範囲(12~16ns)は大きく変わらず。L2の範囲(36~52ns)でいうと、まずRyzen Threadripper 2950Xは1950Xに比べてピークが8nsほど少ないほうにシフトしており、L3の範囲(152ns~284ns)でもこれが顕著である。一方、Ryzen Threadripper 2990WXは、そもそも一番ピークが高いのが260nsあたり、ということからもわかる通り、想像以上にLatencyが増えている。このあたりはMulti-Die構成で、しかも4 Dieを搭載している宿命といえそうだ。
-
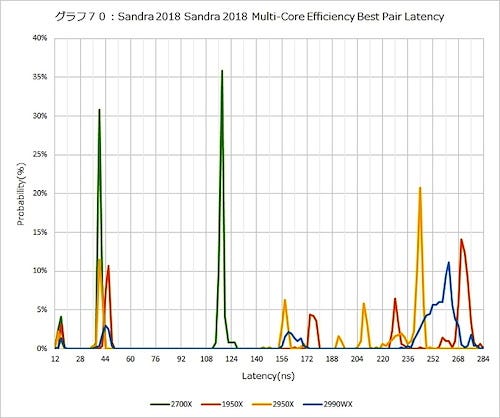
グラフ70

Worst Case
Worst Caseでは、さらに数字がばらつく。Overall(グラフ71)そのものは先のグラフ68と大差ないのだが、Bandwidth(グラフ72)では結果が一桁小さくなっている。Latency(グラフ73)自身も、グラフ70と比較してそれぞれのピークの高さが下がり、その代わり特にL3の範囲(156ns~284ns)に広がっているのがわかる。
-
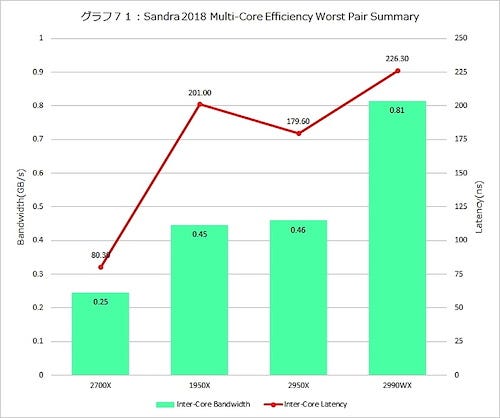
グラフ71

-
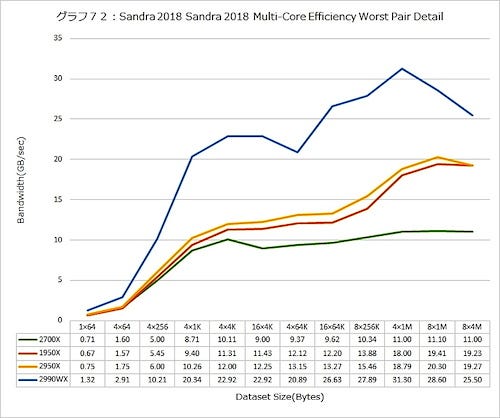
グラフ72

-
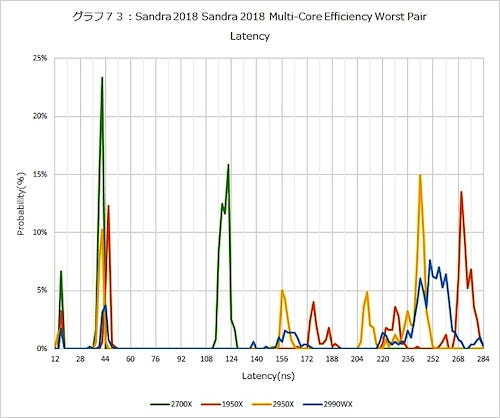
グラフ73

こちらでも、Ryzen Threadripper 2950Xが1950Xよりも確実にLatencyそのものが減っているのは明白。これはこれで問題ないのだが、それとは別にRyzen Threadripper 2990WXは相変わらず252nsあたりにピークが見て取れるあたりが、このプロセッサにおける使い方の難しさを示しているといえよう。








