
さて、Sandraに行く前に恒例のRMMTを。『Ryzen 7 2700X/Ryzen 5 2600Xレビュー - 第2世代RyzenでIntelに追いつくことができたのか?』でも説明したように、関係性の設定を利用してコアの割り当てを変更しているが、今回は以下のようにしている。
- Ryzen 7 2700X:CPU 0/2/4/6/8/10/12/14を有効に
- Ryzen Threadripper 1950X/2950X:CPU 0/4/8/12/16/20/24/28を有効に
- Ryzen Threadripper 2990WX:CPU 0/4/8/12/16/20/24/28を有効に(0/2)
- Ryzen Threadripper 2990WX:CPU 32/36/40/44/48/52/56/60を有効に(1/3)
Ryzen Threadripper 2990WXに関して、「(0/2)」というのはDie 0とDie 2のコアを有効にしたケース、「(1/3)」はDie 1とDie 3を有効にしたケースである。要するに、ローカルのメモリがある場合とない場合でどの程度の差があるのか、を確認してみた。
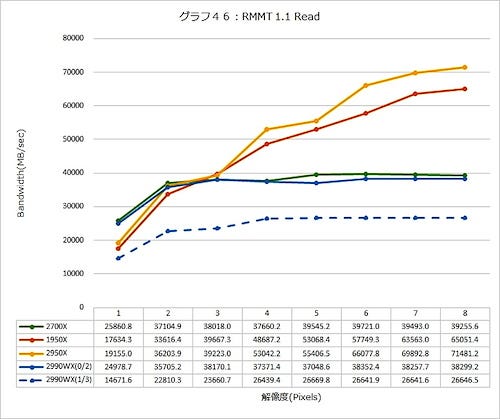
まずはRead(グラフ46)。Ryzen ThreadRipper 1950X/2950Xはセオリー通りに性能が伸びており、特に8Threadでは71GB/sec超えで、Ryzen 7 2700Xの8割増に達している。対してRyzen Threadripper 2990WXでは、Die 0とDie 2を使った場合でもRyzen 7 2700X並み、Die 1とDie 3の場合はさらに低下して、30GB/secにすら達していない。
-
グラフ46

やはり4 Die構成の場合は、Die 1とDie 3を使っていなくても相当に(Infinity Fabric経由での)オーバーヘッドがあるものと思われる。Infinity Fabric経由だと確実にLatencyが増えるため(Photo02の説明が正しければFar Memoryだと40nsほど余分にLatencyがかかる)、これが低いReadのスループットにつながる、ということらしい。メモリアクセスが多発するようなアプリケーションは、Ryzen Threadripper 2990WX(というかWシリーズ)には向かない、ということだろう。
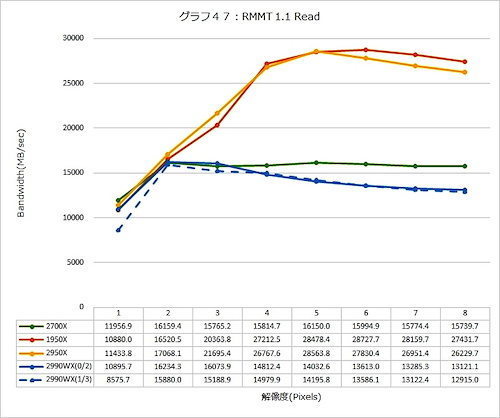
Write(グラフ47)だと少し様相が変わってくる。Ryzen Threadripper 1950X/2950Xが相変わらず飛びぬけて帯域が大きいのはともかく、Ryzen Threadripper 2990WXでDie 0とDie 2の場合、およびDie 1とDie 3の場合で帯域がほぼ同じになっている。Infinity Fabric経由でのオーバーヘッドよりも、Writeのオーバーヘッドのほうが大きいということではないかと思われる(その傍証が1 Threadの場合で、ここだと明確に性能差が出ている)。
-
グラフ47

それにしてもここまで性能が大きく違うと、最初に説明したInfinity Fabricの帯域がメモリの速度にマッチしているという話がそもそも怪しい感じだ。もともとInfinity Fabricの速度はDDR4の1ch分とマッチしている訳だが、実際には2chまとめてアクセスだったりするから、帯域が足りなくなりやすい。
Ryzen Threadripper 1950X/2950Xでは、2つのDieを2本のInfinity Fabricでつないでいるからちょうどマッチする。しかし、これが1本に減らされたRyzen Threadripper 2990WXでは、帯域そのものが足りないということかもしれない。Ryzen Threadripper 2990WXを使う場合は、メモリをUnganged Mode(2本のメモリチャネルが独立に動作)に設定して使うのが妥当なのかもしれない(ただしアプリケーション性能に影響は大きそうだが)。








