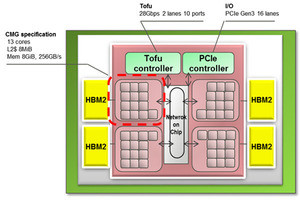
A64FXのマルチコアアーキテクチャ
A64FXは、52コアを集積するメニーコアプロセサであるが、13コアとL2キャッシュ、そして1個のHBM2コントローラがCore Memory Group(CMG)という単位を構成する。そして、チップには4つのCMGがあり、それらの間ではオンチップのディレクトリを用いてキャッシュコヒーレンシが維持されている。
1つのCMGの13個のコアと8MBのL2キャッシュの間はクロスバで接続されている。一方、他のCMGのL2キャッシュをアクセスする場合はリングバス構造のNetwork on Chip(NoC)を経由する必要がある。また、TofuインタコネクトやPCIe経由のI/Oアクセスなどもリングバス構造のNoCを経由する。
-
A64FXは52コアを集積するが、13コアと8MBのL2キャッシュと1個のメモリコントローラからなる4個のCMGに分かれている。そして、CMGとTofuコントローラやPCIeコントローラはリングバスのNoCで接続されている

L1データキャッシュの読み出しバンド幅は230GB/s超、書き込みバンド幅は115GB/sである。48コアへのデータ供給のバンド幅は11.0TB/sであり、演算とメモリバンド幅の比は、ほぼ4Byte/Flopsとなっている。
コアとL2キャッシュを接続するクロスバのバンド幅はL1データキャッシュの半分のバス幅となっている。しかし、バンド幅が半分ではなく、3.6TB/s超となっているのは、L2キャッシュが16Wayのキャッシュであり、バンクコンフリクトで実効的なバンド幅が制約されることを考慮にいれた値になっているからではないかと思われる。
また、CMG間を繋ぐリングバスは115GB/s超×2と書かれており、回転方向が逆になる2つの115GB/sのリングバスとなっていると思われる。そして、これはA64FXの特徴であるが、3次キャッシュやLLC(Last Level Cache)のようなキャッシュを置かず、L2キャッシュから直接、8GBのHBM2メモリにつながっている。短い配線で直結されるHBM2は、比較的、高速のアクセスができるので、L3キャッシュを置くよりも、HBM2を直結して構造を簡単にした方が良いという判断であろう。
CMGとHBM2の間のピークバンド幅は256GB/sであり、4個合計では1024GB/sとなる。ピーク演算性能は2.7TFlopsでありB/Fは約0.37Byte/Flopsとなる。これは約0.5Byte/Flopsであった京コンピュータには及ばないが、最近のスパコンとしてはかなり高い値であり、メモリヘビーなアプリケーションで高い実効性能が期待できると思われる。
-
コアとL1データキャッシュ間のデータパスはロードが230GB/s超、ストアが115GB/s超でB/Fは約4である。HBM2メモリのバンド幅は1024GB/sで、B/Fは0.37である。これは最近の大規模スパコンでは非常にメモリバンド幅リッチな設計となっている

SPARC64 XIfxとA64FXの性能比較
次の図の棒グラフは、現在の富士通のスパコンに使われているSPARC64 XIfxプロセサの性能を1.0としたA64FXプロセサの性能を示している。左端のDGEMMは行列の掛け算で、おおよそ、Top500の性能に近い。このDGEMMの性能は2.5TFlopsとのことで、ピークの2.7TFlopsの90%を超える値をマークしている。
その右のStreamはメモリの読み出しバンド幅を図るベンチマークで、このスコアは830GB/sとなっており、ピークの80%を超える値をマークしている。
その右の3本の棒グラフは流体、気象、地震波伝搬のアプリケーションの性能で、A64FXはSPARC64 XIfxの2.8倍から3.4倍の性能となっている。そして、性能向上の大きな要因が棒グラフに書き込まれている。流体のアプリではCombined Gatherが大きく貢献し、気象アプリではL1キャッシュのバンド幅と512bitSIMD、地震波伝搬アプリではL2キャシュバンド幅と512bit SIMDというように、アプリケーションによって効いている部分が異なっている。
右端の2つの棒グラフはAI関係の演算の性能比較で、32bitFPでの畳み込み演算では2.5倍、8bitINTでの内積計算では9.4倍という性能向上になっている。
-
現在の富士通スパコンで使用しているSPARC64 XIfx CPUを1.0としたA64FXプロセサの性能と性能改善要因。流体、気象、地震波伝搬の3つのアプリの性能向上は2.8~3.4倍となっている。主要な性能改善要因はアプリごとに異なる

A64FXの電力管理機能
スパコンは大規模で消費電力も大きいので、電力管理は重要である。A64FXを使用するスパコンでは、チップ単位でノードやCMGの平均電力を測定するエネルギーモニタとコア単位でPAPIインタフェースを使ってチップ上の性能カウンタなどを読み取る機能を備えている。この性能カウンタの値からプロセサコアの消費エネルギーを分析することができる。なお、これらは消費電力を直接測定するものではなく、各部の動作状態から消費電力を推定している。
-
A64FXにはチップ単位での電力を測るエネルギーモニタとPAPIインタフェースで高速に細粒度でチップ上のカウンタを読み取る機能があり、この結果から、消費電力を求めるエネルギーアナライザがある

そして、A64FXプロセサは「Power knob」と呼ぶ電力管理機能をもっている。Power knobは、コア全体のクロック周波数を変えたり、命令のデコード幅、演算パイプラインのスループットなどを変えてコアの消費電力を調整することができる。また、HBM2のメモリバンド幅を調整して消費電力を変えることができる。これらのPower knobをうまく使えば、性能インパクトが少ない消費電力低減ができる可能性がある。
-
A64FXはコアのクロックを変えたり、命令デコードの幅、演算パイプラインのスループットなどを変えたりして消費電力を調整することができる。また、HBM2のバンド幅を変えることもできる。このような調整で、性能インパクトが小さく、消費電力の低減効果が大きい状態を探す

(次回は9月3日に掲載します)