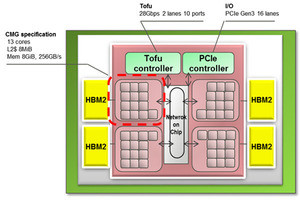
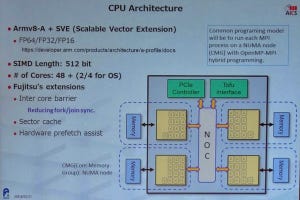
A64FXコアのパイプラインダイヤグラム
次の図にA64FXと富士通のFX100スパコン、京コンピュータの諸機能の一覧を示す。この表を見ると、京コンピュータでは128ビット幅であったSIMD演算が、FX100では256ビット幅に拡張され、さらにA64FXでは512ビット幅と演算性能が強化されていることが分かる。
それに加えて、飛び飛びのメモリアドレスをまとめてアクセスするScatter/Gatherなどの機能が強化されたり、AI用にFP16やINT16/8などの低精度演算のサポートなどが追加されてきていることが分かる。
-
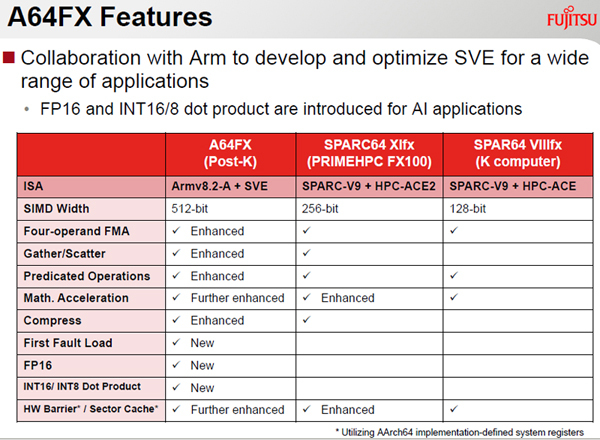
A64FXの機能一覧と富士通のFX100スパコン、京コンピュータとの比較。A64FXではAI向けにFP16とINT16/8の内積演算が追加された

次の図はA64FXコアのパイプラインダイヤグラムである。基本的には京コンピュータで開発したSPARC64のパイプライン構造をキープし、512bit幅のSIMD FMA演算や512bit幅のロード、ストア、そしてプレディケート演算などの機能を強化している。
-
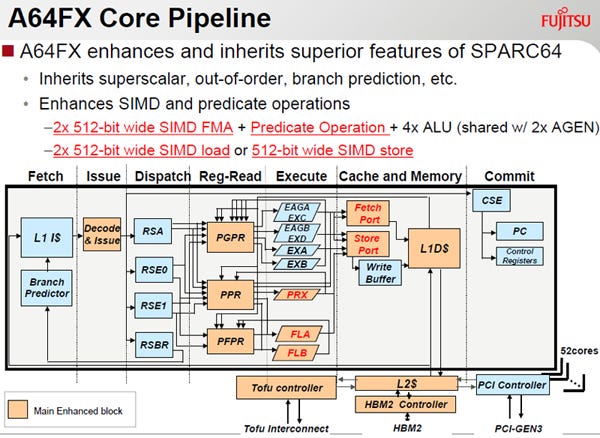
A64FXコアのパイプライン。基本的にはSPARC64のパイプライン構造をキープして、512bit SIMD演算、ロードストアの追加とプレディケート演算機能を強化している

Armの命令フォーマットではD=A*B+Cという3つの入力レジスタと1つの出力レジスタを指定するには命令のビット数が不足である。このため、MOVPRFXという命令を追加して、この命令で次に続くFMA3命令のZ0というレジスタ指定の部分を書き変えるというやり方を取っている。
しかし、この2つの連続する命令はプレデコードのステージで1つの命令にまとめられて処理されるので、2命令を実行するというオーバヘッドは発生しないようになっている。
なお、4オペランド命令では、命令のビット数が足りないのはSPARCでも同じで、類似の方法が使われていたし、Intelのx86でも前置の命令で直後の命令を補足するという方法が使われている。
-
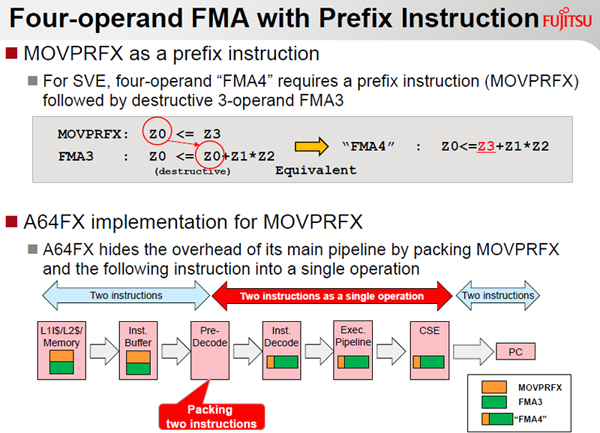
D=A*B+Cを計算する演算では,命令語のビット数が足りず、4つのレジスタを指定できない。このため、MOVPRFX命令で入力のZ0をZ3に置き換える。PreDecodeステージで、1命令にまとめられるので、実行命令の数は増えない

512bit幅のベクタ演算器を2つ持つA64FXコア
A64FXの各コアは、512bit幅のベクタ演算器を2つ持っている。この512bitは、8個の64bit浮動小数点数、16個の32bit浮動小数点数、32個の16bit浮動小数点数として扱うことができ、整数の場合は8bitから64bitの各種サイズの数値の集まりとして扱うことができる。そのため、A64FXは、64bitの倍精度浮動小数点数の場合は2.7TFlops超、32bit単精度浮動小数点数の場合は5.4TFlops超、16bitの半精度浮動小数点数や16bit整数の場合は10.8Tops超、8bit整数の内積を計算する場合は21.6Tops超のピーク演算性能となる。
8bit整数での内積計算であるが、図の右側に書かれたように、対応する位置の8bit整数同士を掛け算し、それらすべての積を加算するオペレーションを行う。この図では32bit分の演算が書かれており、実際には、この演算が16個並列に実行されると考えられる。
行列積を計算するGEMMやINT16、INT8の内積計算ではピーク演算性能の90%以上の効率が得られるという。
-
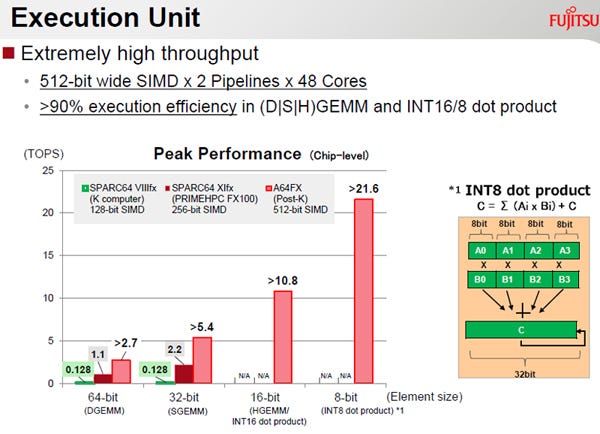
A64FXの各コアは512bit幅のSIMD演算器を2組持っている。行列積を計算するGEMMやInt16/8の内積の計算では、ピーク演算性能の90%以上の実行効率が得られる。チップ全体では48個の計算コアがあり、48倍の性能となる

512bit長のベクタが512の整数倍のアドレスから格納されている場合は、1度のアクセスで512bit長のベクタレジスタにデータを格納することができるが、半端なアドレスから格納されている場合(UnAligned)は、通常、1回のアクセスでは読み出せない。
これに対して、A64FXではUnAlignedなアクセスの場合でも、キャッシュから前半と後半のデータを読み出して、つないでくれる。そして、その場合もAlignedの場合と変わらないスループットが得られるようになっている。
Gatherの2倍のスループットが得られるCombined Gather
ベクタ演算では連続したメモリ領域に入っているデータを並列に演算し、それにより演算性能を高めている。しかし、常にデータが連続したメモリ領域に入っているとは限らない。行列のデータは行方向のデータが連続したメモリ領域の入っている場合、列方向のデータは飛び飛びのメモリアドレスになってしまい、ベクタ演算は使えない。
このため、ベクタスパコンでは飛び飛びのアドレスから読み出してベクタレジスタに順に詰め込むGatherというロード命令があるが、A64FXでは、128バイトのAlignされた領域から2つのデータを取り出して詰め込むCombined Gatherという機能を実装した。このCombined Gatherが使えるケースでは通常のGatherの2倍のスループットが得られる。
これらは比較的目立たない性能改善点であるが、これらの積み重ねがベクタコアの性能に効いてくる富士通のノウハウであると言える。
-
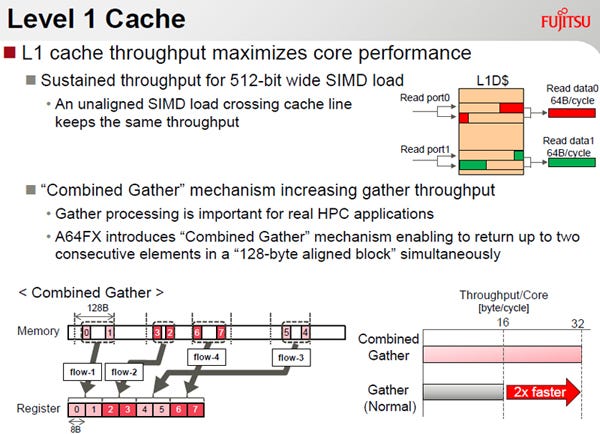
A64FXでは、128バイト境界に揃っていない場合でも、同じスループットでL1キャッシュアクセスができる。また、128バイトの範囲内に2つのデータがある場合は、同時にロードができるCombined Gatherをサポートしている

(次回は8月31日に掲載します)