



東京大学(東大)と科学技術振興機構(JST)の両者は6月9日、35種の音声コマンド認識AIを題材に、既存のAIプロセッサと比較して3桁以上低電力化できる新方式の布線論理型AIプロセッサを開発したと共同で発表した。
-
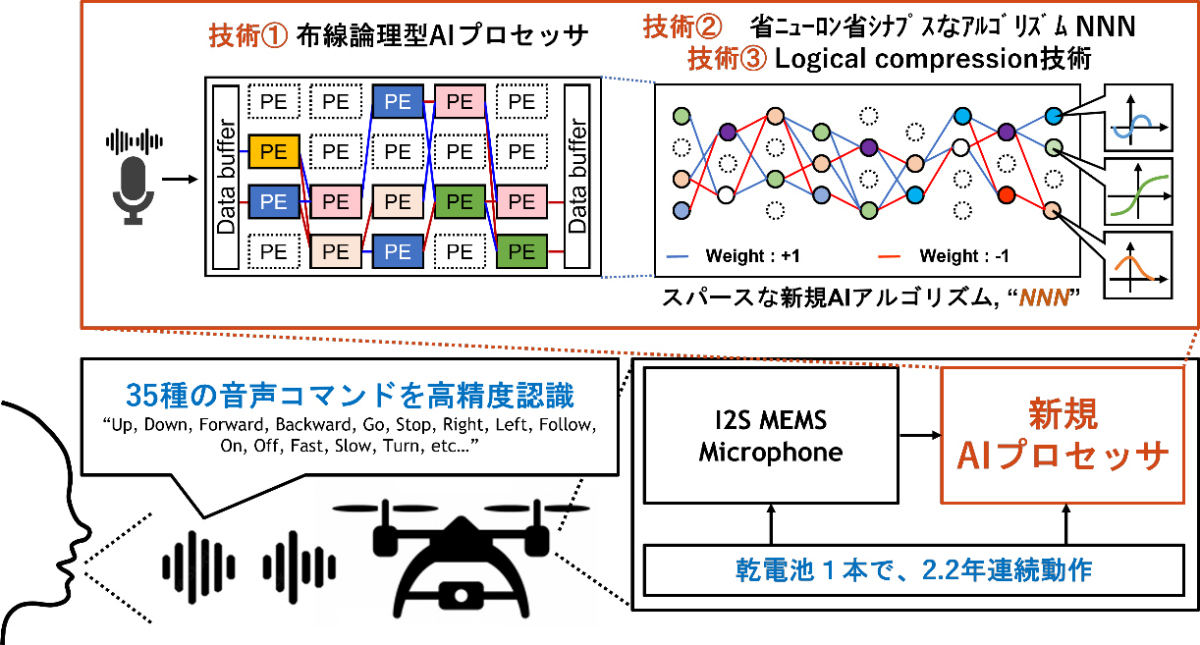
開発された新規AIプロセッサの概要。35種の音声コマンドを高精度認識可能なAIを、152.8μWの電力で連続動作可能。乾電池1本で2.2年間の連続動作できる計算になる。(出所:共同プレスリリースPDF)

同成果は、東大大学院 工学系研究科附属システムデザイン研究センターの小菅敦丈講師、同・濱田基嗣特任教授、同・黒田忠広教授、同・澄川玲維大学院生、同・柴康太大学院生(研究当時)、同・許耀中大学院生(研究当時)らの研究チームによるもの。また今回の研究は、JST戦略的創造研究推進事業の助成のもと行われた。詳細は、国際会議「2023 Symposium on VLSI Technology and Circuits」で発行された「Technical Digest」に掲載された。
音声コマンド認識AIは、新たなマシンインタフェースとして急速に発展しているが、認識可能なコマンド数が増えてAIモデルが複雑化するほど、消費電力が急増するという課題を抱えている。これは、深層ニューラルネットワーク(NN)の処理量が飛躍的に増えてしまうことが理由だ。識別可能なコマンド数が4種程度であれば0.1mW未満での推論が可能である一方、コマンド数が35種にもなると390mW程度の電力が必要だという。
人間の大脳を模倣した布線論理型AIプロセッサは、NNを構成するニューロンとシナプスすべてがチップ上に並列実装されており、頻繁なデータ移動やメモリとの通信をなくすことで、低消費電力化を実現している。しかし、16層もの深層NNを布線論理型AIプロセッサとして実装しようとすると、大きな実装面積が必要となる。特に音声コマンド認識AI用途では長いビット幅が必要であり、個々の回路規模は大きくなるため、試算では30チップ以上にも上る実装面積が必要だったという。そのため、チップ間通信の電力消費が大きいことに加え、チップ枚数も多いことから、実装にかかる巨額のコストと巨大な面積が課題だったとする。
研究チームはこれまで、布線論理型AIプロセッサの実装面積を削減するため、深層NNを簡素化し、必要なニューロンとシナプス数を大幅に削減する「非線形NN」技術を提案してきた。ニューロンの非線形関数を個々に最適化することでNNの表現能力を高め、従来の深層NNに比べて2桁少ないニューロン数とシナプス数で、複雑なAIタスクを実現する技術である。
そこで今回の研究では、音声コマンド認識向けにさらにビット幅を削減し、ニューロンを省面積な回路として実装しやすい形に変換する「Logical Compression」技術も新たに開発したという。また認識精度の劣化を抑えるため、ニューロン回路をAIのモデルとして再度取り込みAIモデルを再度最適化する「Logical Compression Aware Re-Training」技術も併せて開発目標とされた。その結果、音声コマンド認識の精度を保ったまま、回路面積を1/497に削減することに成功したとする。
-

音声コマンド認識に向けた布線論理型AIプロセッサ。チップ実装面積削減のためのLogical Compression技術が開発された。さらに、開発された再学習アルゴリズムと組み合わせることで、認識精度を保ちながら面積を1/497に削減。(出所:共同プレスリリースPDF)

今回の研究では、16層もの深層NNを40nmプロセスで製造した3mm×3mmの1チップに、布線論理型AIプロセッサとして実装することに成功したという。これにより、152.8μW消費電力での推論が可能になったとしている。
-

試作した音声コマンド認識向け布線論理型AIプロセッサ。40nmプロセスで開発。16層の深層ニューラルネットワークが1チップに実装されている。(出所:共同プレスリリースPDF)

研究チームによると、半導体回路設計分野で権威ある学会である「International Solid-State Circuits Conference」(ISSCC)、「Symposium on VLSI Technology and Circuits」(VLSIシンポジウム)にて2019年以降に発表された論文との比較が行われ、同程度の消費電力で3.5倍以上のコマンド数を認識できることが確認されたという。コマンド数が増えると深層NNの規模が増え、一般には電力が大幅に増大するが、同程度の100μW台の消費電力に抑えることに成功したとする。また従来AIプロセッサ(ISSCC'22)と比較しても、1/2552もの消費電力削減を実現しているとしている。
-

これまでの音声コマンド認識プロセッサとの性能比較。従来のAIプロセッサ(ISSCC’22)と比較し、1/2552以下に電力消費が削減された。(出所:共同プレスリリースPDF)

今回開発された布線論理型AIプロセッサはすべてデジタル回路で構成され、Pythonなどの高位プログラミング言語から、短い設計期間でAIプロセッサの製造図面にまで変換できることが特徴だという。そのため、短期間に機能更新を繰り返すAIアプリケーションに最適といえるとする。さらに今後は音声コマンド認識に限らず、マシンビジョン、設備点検自動化、物流倉庫、無人店舗など、カメラやドローンなどの端末に直接AIを搭載したエッジAIアプリケーションへ展開することを目指しているとした。














