英Armは2月21日(英国時間)、同社のサーバー向けプロセッサである「Neoverse」の第3世代製品にあたる「Neoverse V3/N3/E3」を発表した。これに関し、事前説明会の資料をベースに概略をご紹介したい。
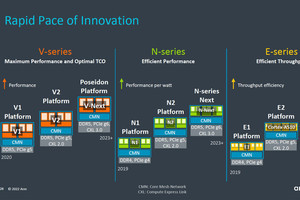
2022年9月にNeoverseの第2世代が発表されたが、そこから1年半弱で次のNeoverseが発表された形になる(Photo01)。
位置づけなどは第2世代とは変わらず、それぞれの目的に合わせてより進化させた構造になっているという話である(Photo01)。
-
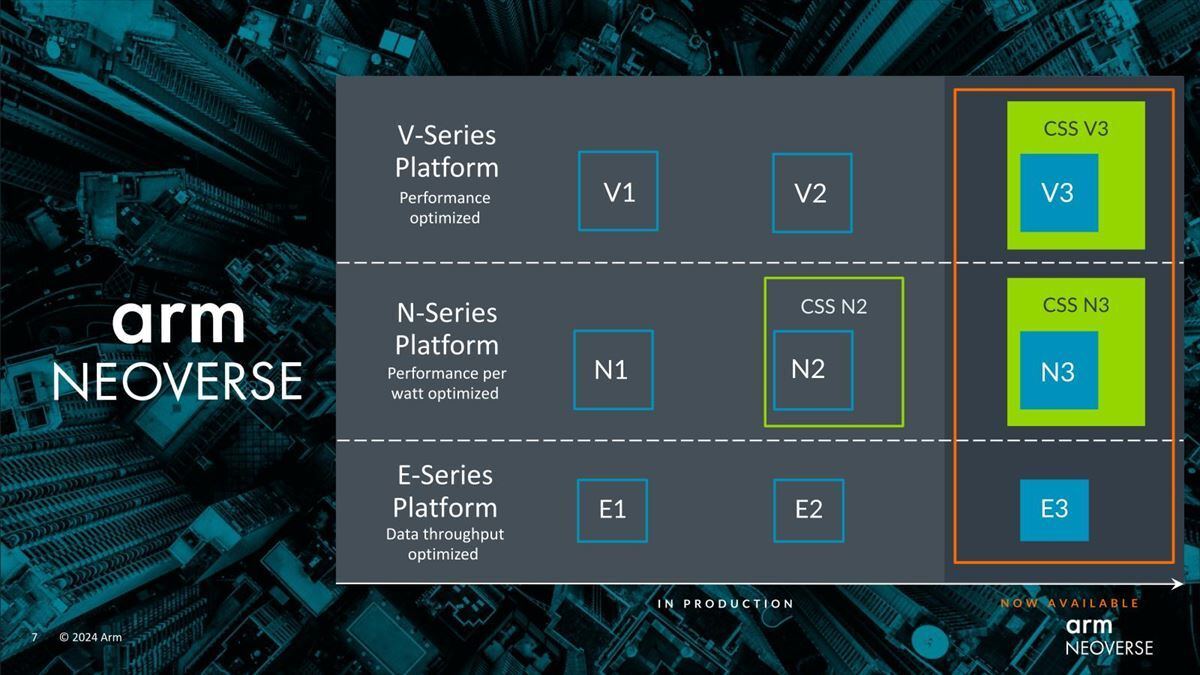
Photo01:Neoverse E3のみ、CSSの提供予定が無い

ちなみにNeoverse V1は以前説明したようにCortex-X1をベースとしてサーバー向けに最適化した構成(Neoverse N1も同様にCortex-A76がベースだった)が、今回発表のNeoverse V3はもうMicroarchitectureのレベルでCortex-Xシリーズとは異なっているという話であり、またNeoverse N3も確かにMobile向けのCortex-Aシリーズ(多分Cortex-A720あたり)とルーツは同じだが、実装は結構異なっているとの説明であった(Neoverse Eシリーズはそもそも独自:最初はCortex-A65AEあたりがベースだったと思うのだが……)。
ここで重要になるのがCSS(Compute SubSystem)である(Photo02)。
-
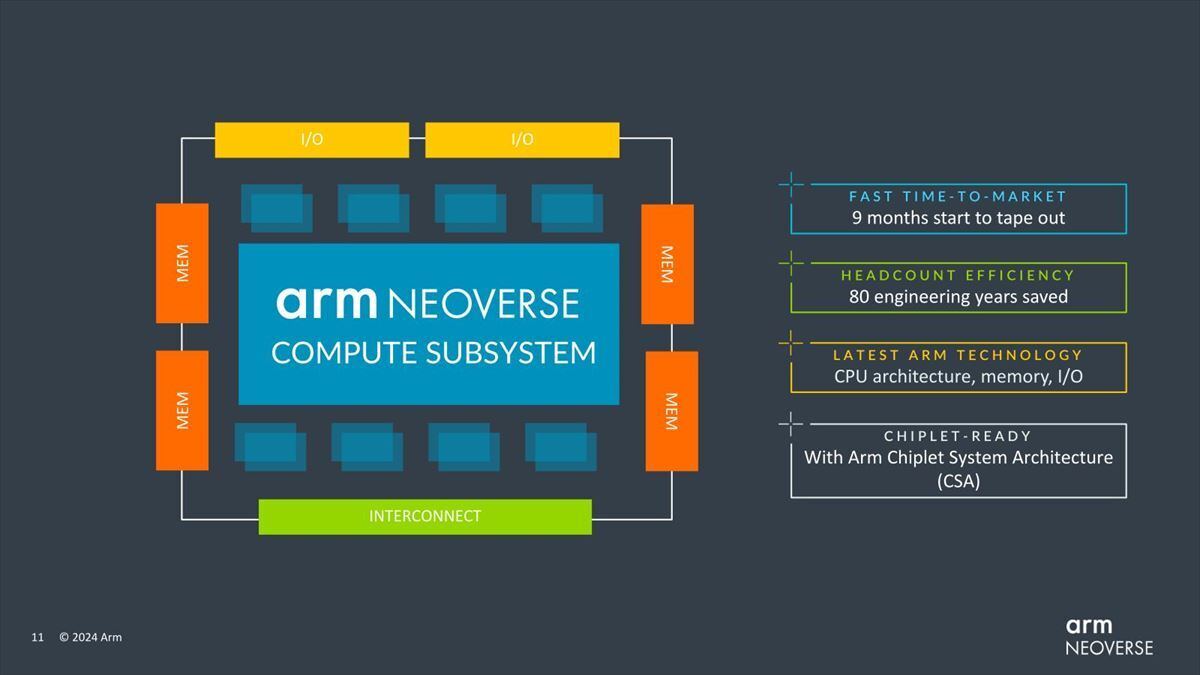
Photo02:まぁこの9か月の中にはCustom Logicの設計は入っていないと思うので、流石にすべてのSoCが9か月でできるとも思えないが

このCSSも以前説明したように、単にCPUコアだけでなく周辺回路まで含めて全体をパッケージ化した形でソリューションを提供する事で、システム開発に要する時間の短縮を可能にするというものだ。
具体的に言えば、Neoverse CSS N3(Photo03)はダイあたり8~32コアの構成を容易に実現可能で、32コアであっても40W程度の消費電力で動作可能とする。
-

Photo03:Neoverse N3はN2比でコアあたり20%の性能電力比の改善が施された、としている

一方Neoverse CSS V3は最大64コアに対応しており、CSS N2と比較してSocketあたりの性能が50%高い、としている(Photo04)。
-
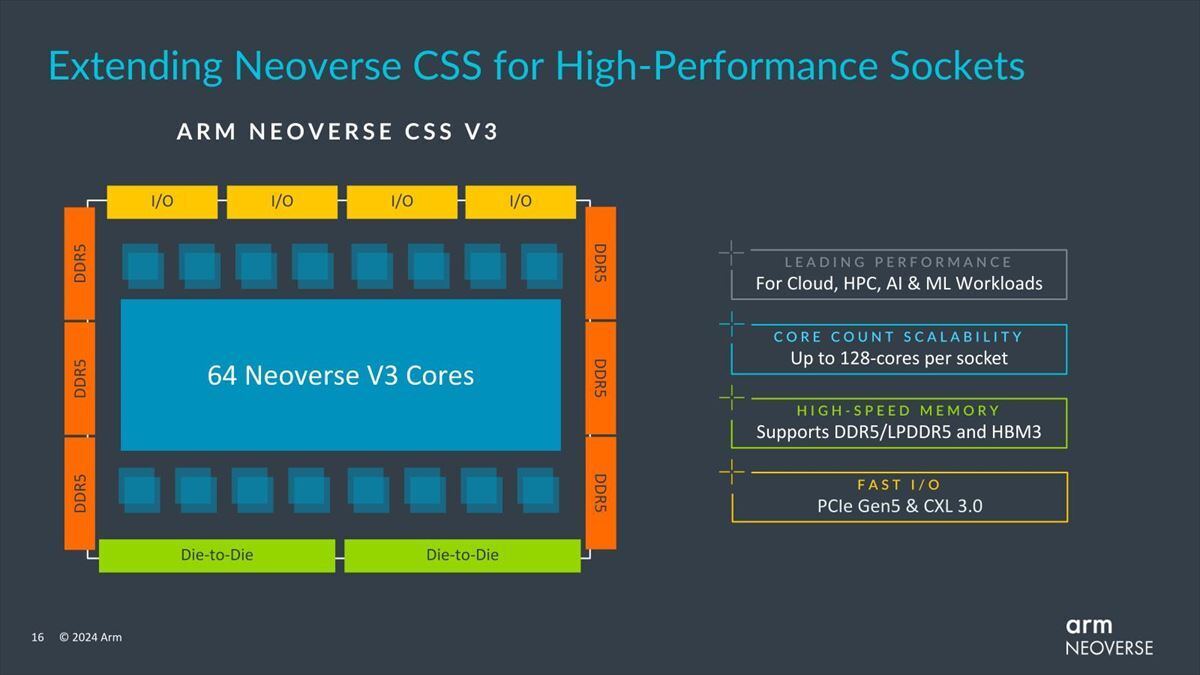
Photo04:128コアというのは、つまり1 socketあたり2 dieを想定しているのかもしれない

ちなみに現状Neoverse V3/N3/E3の内部構造の詳細は明らかにされていないが、性能電力比に関しては簡単に説明があり、Neoverse V3はV2比で10%強、Neoverse N3はN2比で15%前後の改善が示されているとする(Photo05)。
-
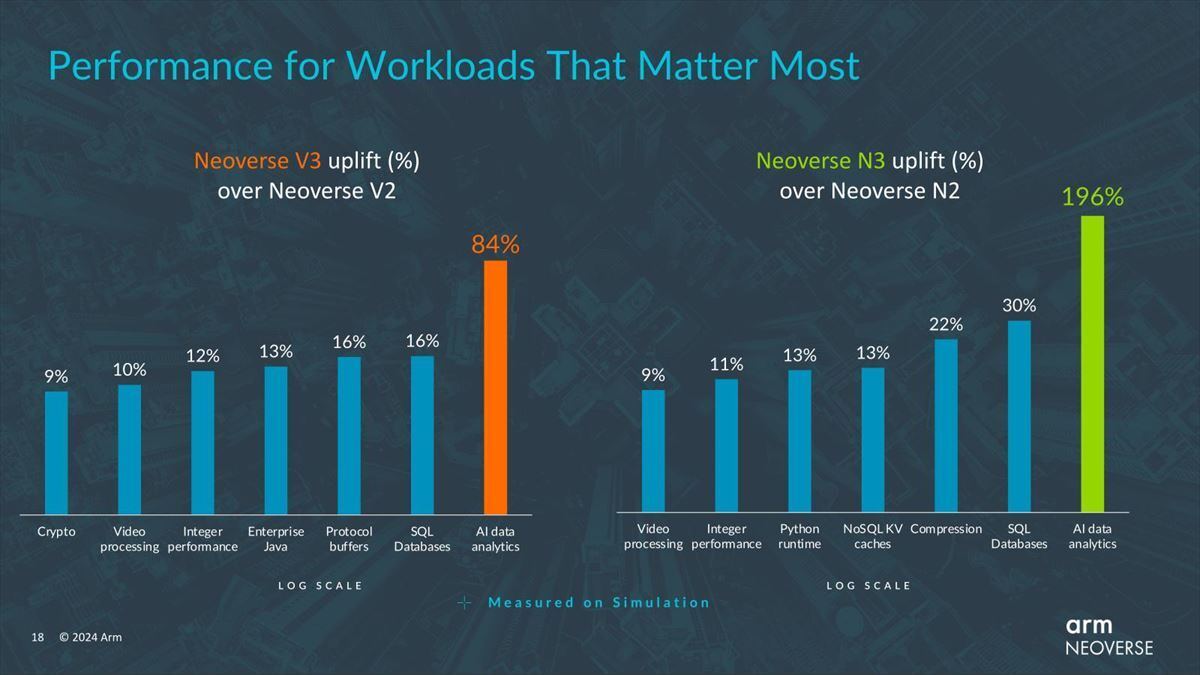
Photo05:これは同一プロセスでのシミュレーションデータだが、実際には製造のプロセスノードが変わってくる(TSMCのN3EとかIntel 18Aなどがターゲットだろう)ので、性能差はもう少し大きくなると思われる

ここで妙にAI data analyticsだけ数字が飛びぬけているのは、実際にこうしたワークロードを動かして、その結果からボトルネックを改善した結果だそうだ。一例として挙げられたのがdmlc xgboostで、これを試しにNeoverse N3で実行してみたところ、Branch PredictorとInstruction Fetch、それとL2 Cache Sizeがボトルネックになっていると判断され、これを改善した結果が196%の改善に繋がったのだそうだ(Photo06)。
-

Photo06:別にxgboostだけに注目して最適化を行った訳ではなく、他にもいろいろなAI workloadで同様に最適化作業を行っているとの事

ちなみにCSSはNeoverse E3では提供されない。これについては、Neoverse V3/N3についてはCPUコアを高密度で実装するニーズが高いため、エンジニアリングコストが高騰するという問題の解決のためにCSSが用意された(Photo01にもあるように、そもそも第2世代ではNeoverse N2のみが対象で、Neoverse V2はCSSが提供されなかった)が、Neoverse E3はそこまで高密度なコアを提供するような使い方をしないので、CSSは不要と判断したとの事。まぁこの辺は顧客のニーズが薄かった、ということだろう。
ところで先にPhoto02の右下に何気なく出て来たのがChiplet System Architecture(CSA)である(Photo07)。
-

Photo07:あくまでもArmはプロトコル層以上しか今のところ提供の予定は無いらしい。まぁPHYまで提供し始めると泥沼になりそうな気もしなくは無いが

これは今年2月14日に発表されたもので、Chipletベースでシステムを簡単に構築できる様に配慮されたものである。ただ確認したところ、ChipletのPHYそのものはCSS/CSAには含まれておらず、また単体IPの形で提供の予定も(少なくとも現時点では)無いとの事。なのでUCIeなり、Synopsysあたりが提供するXSR/USR PHYなりを購入して組み込む必要がある。
ではCSAは何を提供するか? というと、そうしたDie-to-Die I/Fの上でMulti-Dieに跨るSystem InterconnectのProtocol層やManagement層を提供する事になる。
現実問題としてこのChipletのPHYは普通に考えるとCMN-700に接続される形となると思われるが、そうなったときには複数のDie上で動く別々のCMN-700が同期する形でソフトウェアからは1つの巨大なCMN-700として動作する事も可能だし、別々のProcessor Cluster同士が繋がる形にもできる。要するにCache Coherent Protocolを通すか通さないかという話になる訳だが、そのどちらも可能という話であった。2023年5月にArmはAMBA CHI C2C(Coherent Hub Interface Chip to Chip) Extensionを発表しており、これを利用する事でChipletのPHYの上でCHIプロトコルを経由して、複数のCMN-700の接続が可能となる。AMBA CHI C2C Extensionは発表こそ昨年であったが、これがCSAに合わせて利用可能になった形だ。ついでに言えば、AXI C2C SpecificationもこのCSAでサポートされる対象に入る模様だ。
このCSS/CSAを含むソリューションをより確実に開発するためのエコシステムとしてArmは昨年、Arm Total Desingを発表したが、NeoverseというかCSS V3/N3に対応するデザインパートナーも今回アナウンスされた(Photo08)。
-
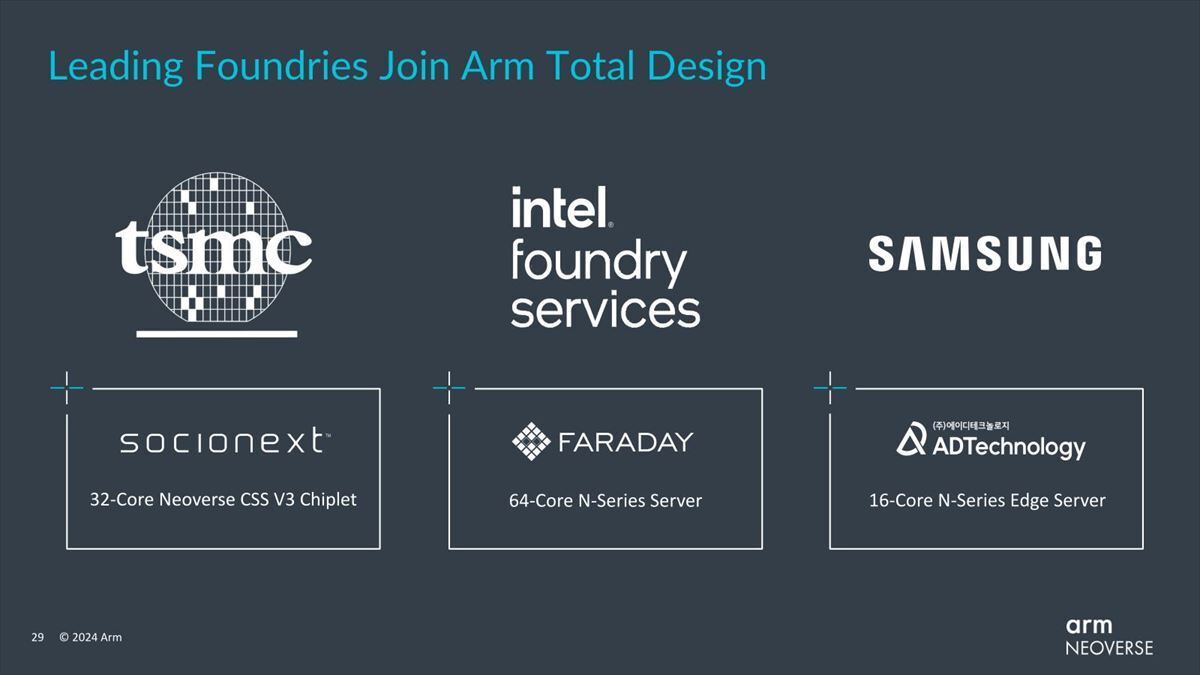
Photo08:TSMCがSocionext、IFSがFaraday、SamsungがADTechnologyとなっているが、これ「だけ」ではなく今後パートナーが増えると思われる

またArmは現在、これに続き第4世代のNeoverseも開発中としている(Photo09)。この第3世代Neoverse 3製品とCSS V3/CSS N3は同日よりライセンス提供を開始しているとの事だ。
-
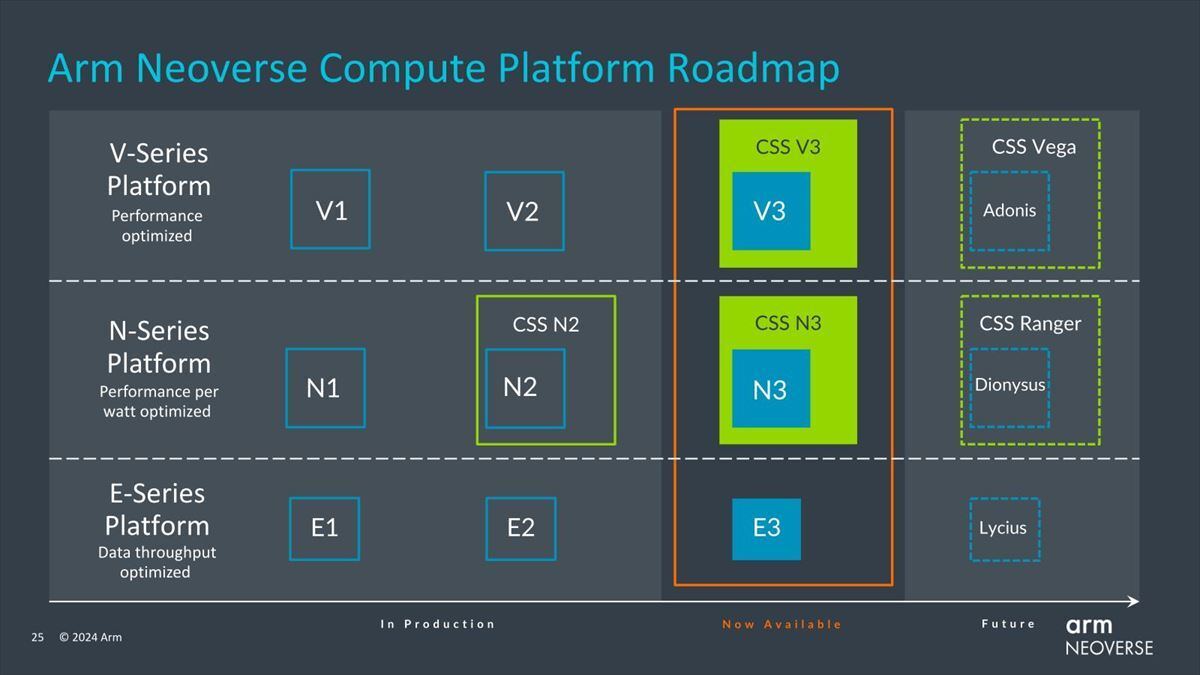
Photo09:平均1年半ごとに新世代が発表されることを考えると、Adonis/Dionysus/LyciusやVega/Rangerが提供されるのは2025年後半だろうか? ターゲットはTSMC N2とかSamsung SF2あたりになりそうだ