



Network & Edge分野の性能
Network向け、最近だとvRANがホットなトピックであるが、もっと広範にSDNのコンポーネントや、あるいはNetwork EdgeのプロセッサはXeonの主戦場の1つでもある。このマーケットにおける第4世代Xeonスケーラブル・プロセッサの性能の優位性をまとめたのがこちら(Photo15)である。
-

Photo15:数値の比較対象はモノによって変わるが、基本は第3世代Xeonスケーラブル・プロセッサベースで、後は消費電力とかワークロードに応じて、Xeon PlatinumだったりGoldだったりする

もうちょっと細かく見てみよう。Networkでは最終的にI/Oスループットがモノをいう事になるが、これに関して第3世代Xeonスケーラブル・プロセッサ比で1.5~2倍の性能を実現する、としている(Photo16)。
-
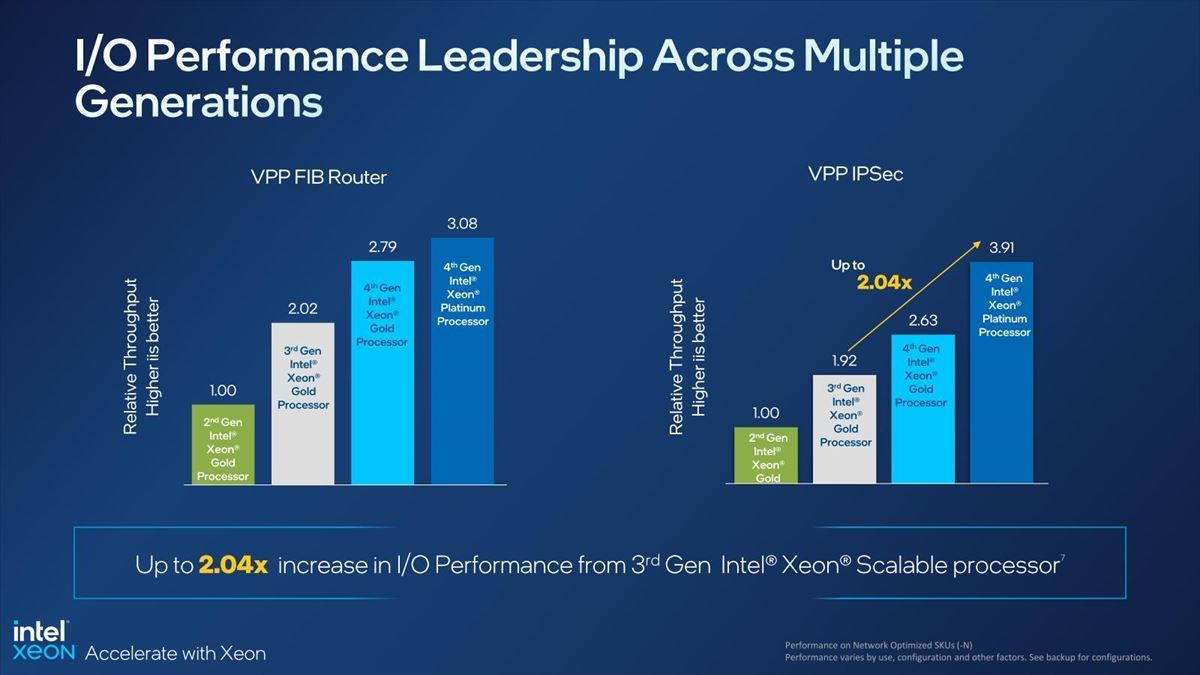
Photo16:VPP(Vector Packet Processing)の性能比較

実アプリケーションとして、5G Core UPF(User Plane Function)のスループットとか、FirewallにおけるText Inspectionなどを比較したのがこちら(Photo17)。
-

Photo17:ただ同じXeon Gold同士だと30%の性能向上、というあたりはちょっと微妙かも

こうした処理で役に立つのがDDIO(Data Direct I/O Technology)で、これを利用する事で最大で4.1倍ものI/Oスループットを実現できるとする(Photo18)。ちなみにDDIOそのものはSandy Bridge世代のXeonから搭載されている機能だ。
-
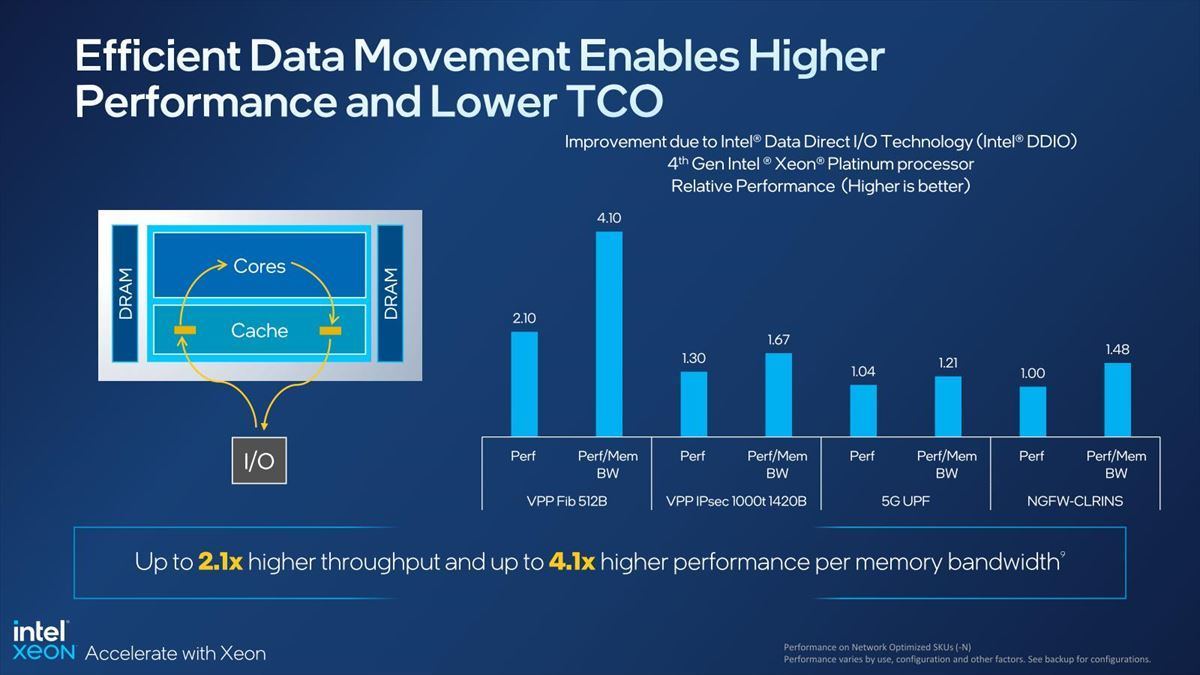
Photo18:要するにMemoryを介さずにI/Oデバイスとキャッシュの間で直接データ交換が可能になる。RDMA(Remote DMA)もこれを利用して高速化可能である

また、3GPPはRelease 17でAIを導入した。現在はNWDAF(Network Data Analytics Function)の一部に留まるが、今後Release 18以降ではさらに広範に適用分野が広がる可能性は高い。それ以外にもNetwork & EdegeでのAIの適用範囲が広がりつつあるが、これに関しては第4世代Xeonスケーラブル・プロセッサで搭載されたAMXが効果的とする(Photo20)。
-
Photo19:左はいつものResNet-50の比較なのでEdge向けではあるがNetworkとはあまり関係ない

-
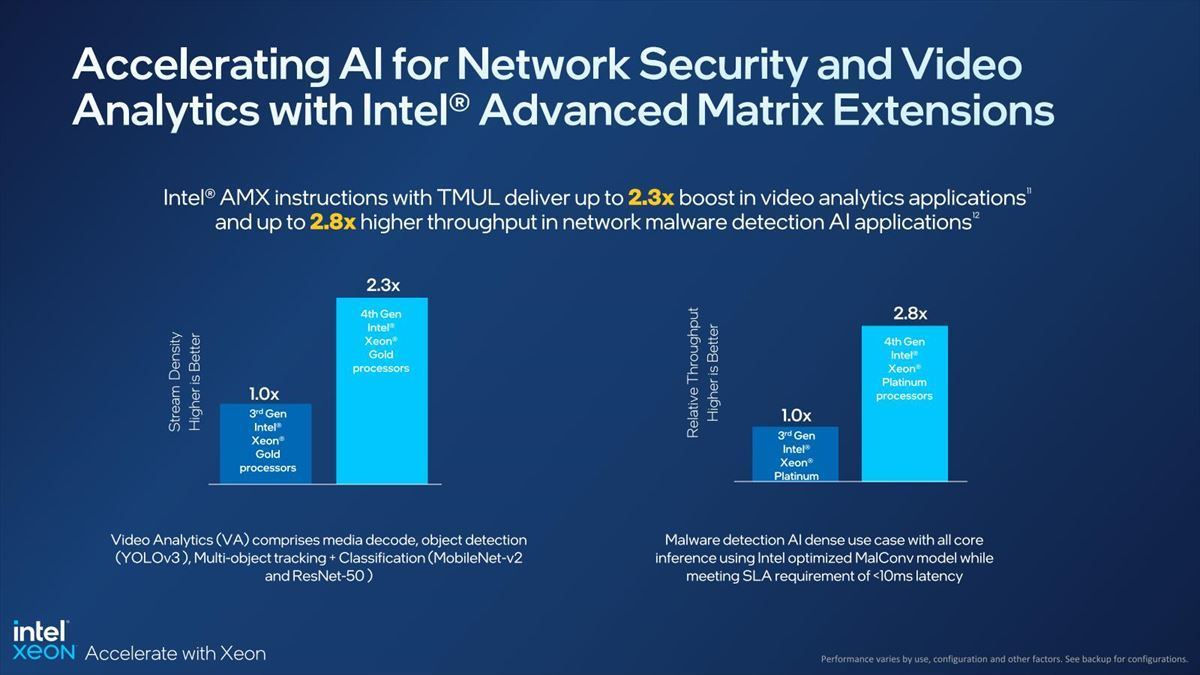
Photo20:AMXも万能ではなく、サイズが小さいと性能が上がり難いので、このあたりのチューニングというか作り込みは今後必要になるのは間違いないのだが

またQATを使う事で圧縮伸長などにCPU時間を費やさずに済むのも、TCO削減の観点からも効果的とする(Photo21)。
-

Photo21:左のグラフの縦軸の意味が今一つ意味不明であるが、要するにL9 Compressionを行う際にCPUを殆ど使わずに済む(L1 CompressionとかDecompressionは、そもそもCPU負荷が低い)という意味合いと思われる














