


Intelは1月10日(米国時間)、第4世代Xeonスケーラブル・プロセッサおよびXeon Maxを正式に発表した。その発表会の模様とかDeep Diveではそもそも性能についての話はスルーさせていただいたが、元々の事前説明でも性能に関してはごく簡単にまとめただけである。そこで、Acceleratorの効果も含めて、もう少し性能についてご紹介してゆきたいと思う。
Cloud & Enterprise分野の性能
IntelによるCloud/Enterprise分野のWorkloadとそのコスト分析がこちら(Photo01)。
-

Photo01:もうクラウドだけでなく通常のEnterprise WorkloadもWebベースに移行しているから、この比率は納得できる。合計のコストはラフに1兆ドル/年、というのも感覚的には納得できる

その中でも特にワークロード負荷を下げるべき分野がこの3つとする(Photo02)。
-

Photo02:Optimizing Productionの32%(作業の32%は無駄)というのはちょっとビックリ

これをどうやって第4世代Xeonスケーラブル・プロセッサで解決するか? ということで、Intelはここにデータ移動、セキュリティ、分析の3つに役立つアクセラレータを用意したとする。
まずデータ移動のコストを下げて効率化を図るのに、DSAとQATが有効とする(Photo03)。
-

Photo03:このData movementはAIの分野でも深刻で、なのでIn-Memory Computingとかが流行する訳だが、流石にEnterprise/Cloudではここまでドラスティックな解決案は無いので、既存のフレームワークの中でどうやって効率化を図るかという話になる

DSA(Photo04)は以前もご紹介したが、要するにCPUが直接メモリをアクセスするのではなく、間に仲介するDSAがメモリアクセスを行ってくれるので、それだけ早くCPUを開放できるし、効率も上がるというものだ。
-
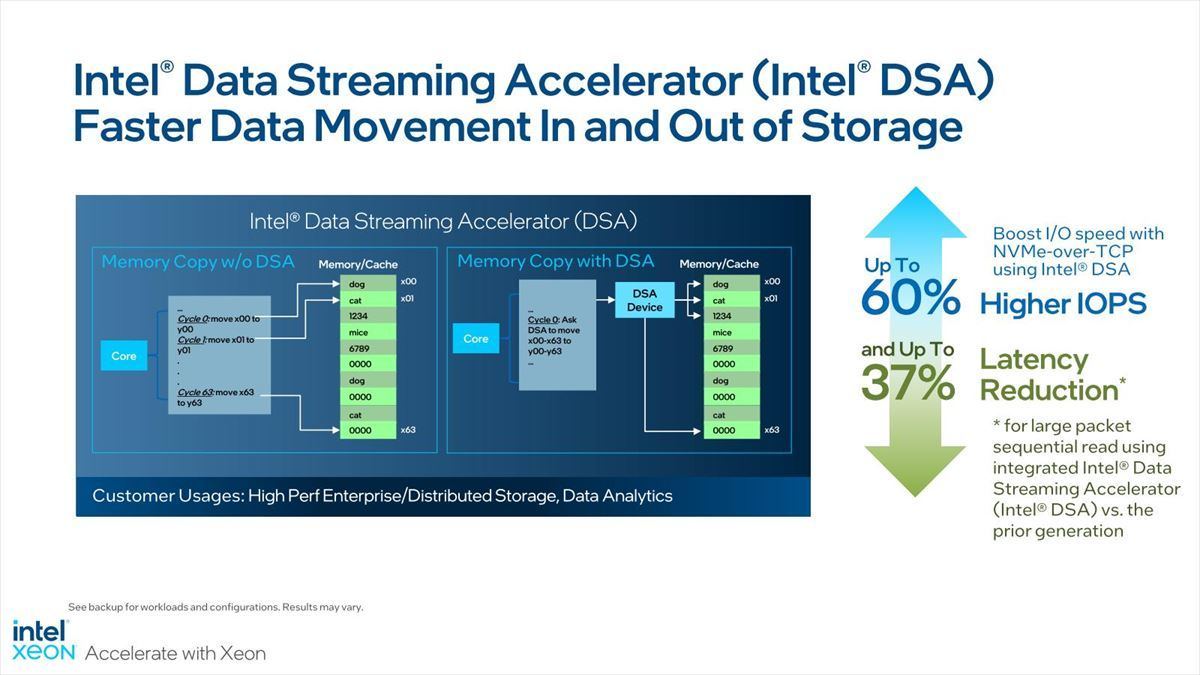
Photo04:Sequential Accessだとそれほど差が出ないかもしれないが、Random Accessでこれは効果的になる

このDSAはSocketあたり最大4インスタンスが利用可能となっている。これと併用可能なのがIntel QAT(Photo05)。QATは要するに圧縮伸長と暗号化/復号化のエンジンであって、これはかなり昔(筆者が記憶している範囲で言えば、2008年に投入されたTolapaiことIntel EP80579にQATが搭載されている)から利用されてきているのでご存じの方も多いだろう。
-

Photo05:要するに可逆圧縮を掛ける事でデータ量そのものを減らす事で高速化を可能にする。Zlib Z9を利用した場合で言えば、ワークロードの負荷を98%削減できる、という数字もある

データの安全性というかセキュリティ対策では、QATによる暗号化/復号化以外に、SGXのSecure Enclaveの対応サイズの倍増とか、新しいIntel TDXなどが搭載されている。このTDXは全く新しいもので、TD(Trusted Domain)と呼ばれる、ハードウェア的にIsolationされたVMを利用できる様にするための仕組みである。
-

Photo06:ちなみにSGXがカバーするEnclaveのサイズは、Gold~Platinumが512GB、Silver/Bronzeが64GBとなっている。第3世代Xeonスケーラブル・プロセッサの場合、Bronzeはなし、Silverで8GB、Gold~Platinumの大半が64GB、Platinumのトップ2~3製品のみ512GBだった

データ分析では、特にIn-Memory Databaseにおける帯域圧縮と検索のオフロードのために、Intel IAAが提供される(Photo07)。
-
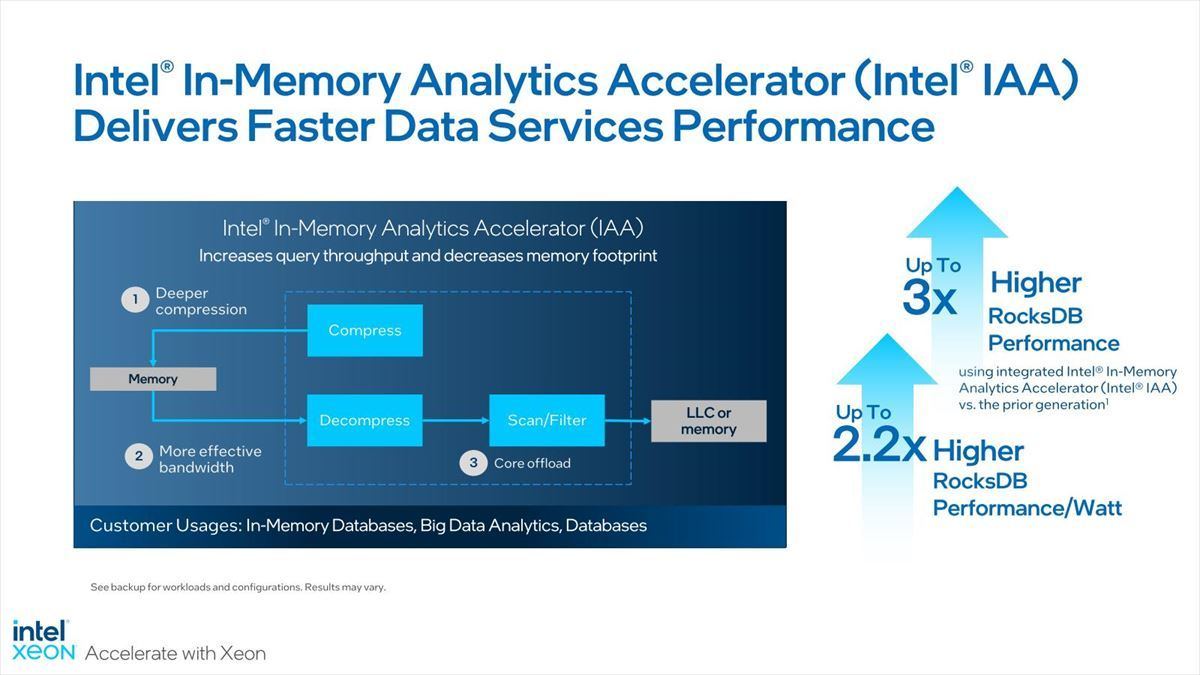
Photo07:In-Memory Databaseだと、当然CPUがひたすらメモリを舐める処理になる。もちろんこれでも従来型のストレージ格納のDatabaseに比べれば圧倒的に高速ではあるのだが

IAAの肝になるのはPhoto08で言う“SQL Filter Functions”であるが、ここではScan(条件を満たすbit-maskの検索)/Extract(必要なデータの抽出)/Select(bit-maskで指定された結果を戻す)/Expand(必要な領域をZero Fillで確保)の4つの処理が行える。要するにSQLのエンジンの一番プリミティブな処理についてCPUをオフロードする形で行えるわけだ。
-
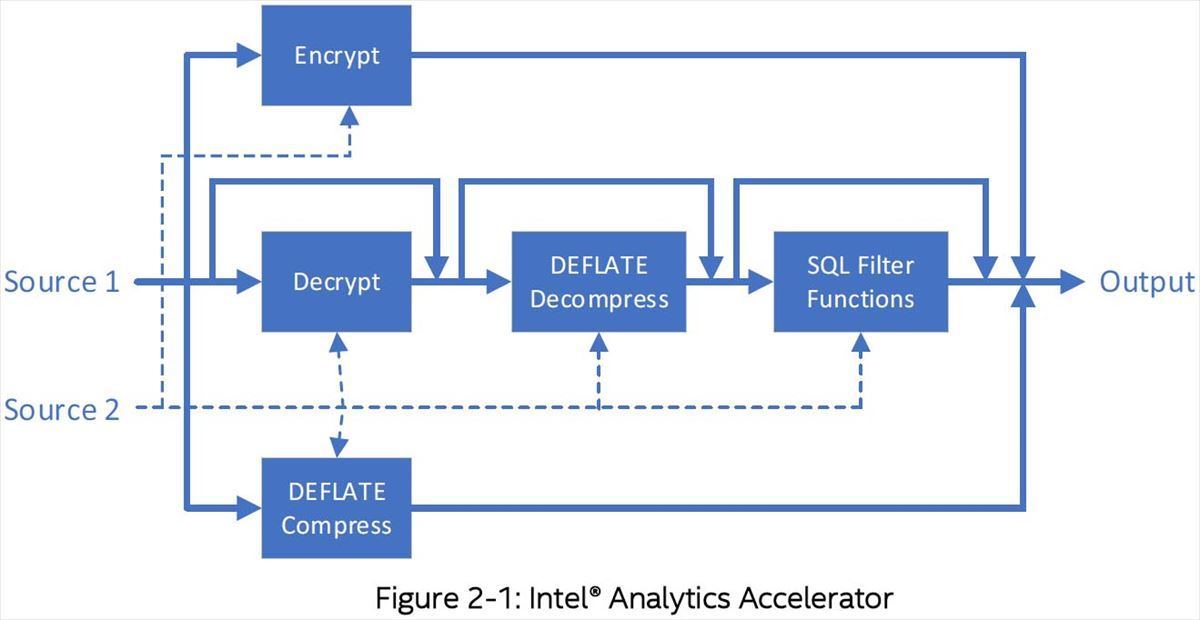
Photo08:こちらはIAAのWhite Paperより抜粋。データは圧縮された形でメモリに格納されており、これの高速な展開とFilter処理が可能

ではトータルでどこまで性能が上がるか? SAP HANAの場合だと処理性能が2.3倍になり、データベース容量はSocketあたり2倍に向上した(Photo09)とする。
-

Photo09:一番右の数字だけ今一つ理解不能。どこから16 Socket構成のシステムの話が出て来たのだろう? ちなみに左の数字は、Cascade Lake(第2世代Xeonスケーラブル・プロセッサ)ベースのシステムとの性能比である

Microservice周りで言えば、アクセラレータを併用する事で様々なコンポーネントの性能が向上するとしており(Photo10)、トータルで60~80%の性能向上が実現(Photo11)。Google Cloudでは25~134%の性能改善(Photo12)、その他の顧客でも大幅な性能改善が可能になった(Photo13)とする。
-
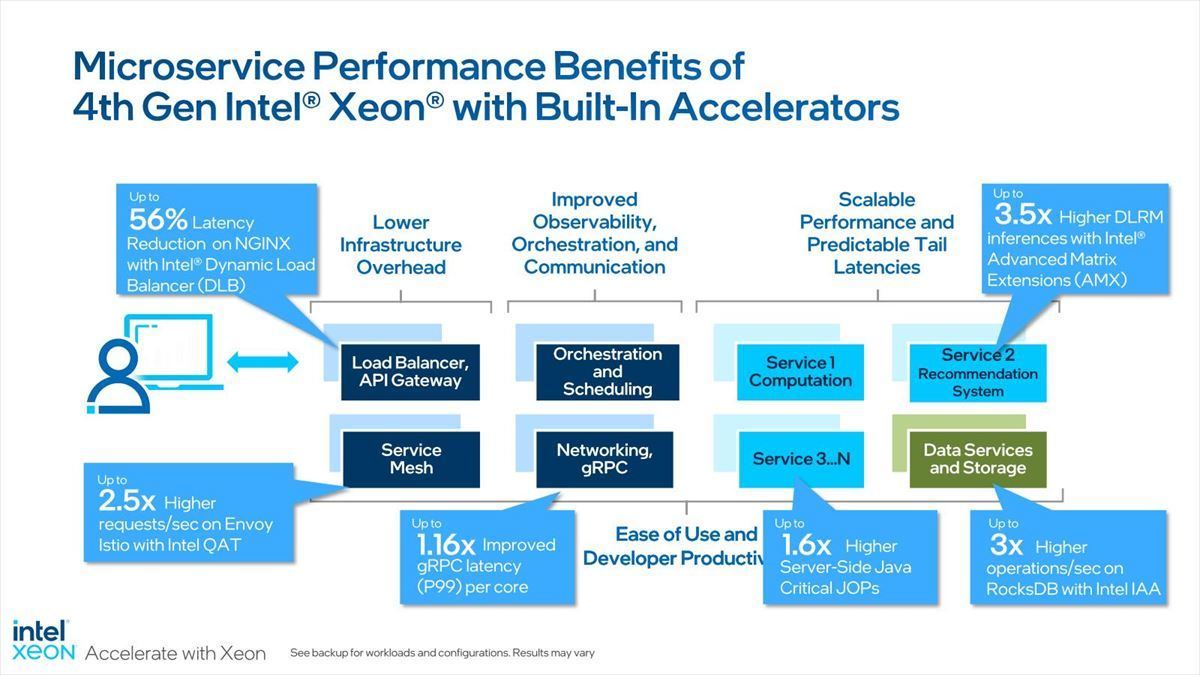
Photo10:DLB(Dynamic Load Balancer)の話は後述

-
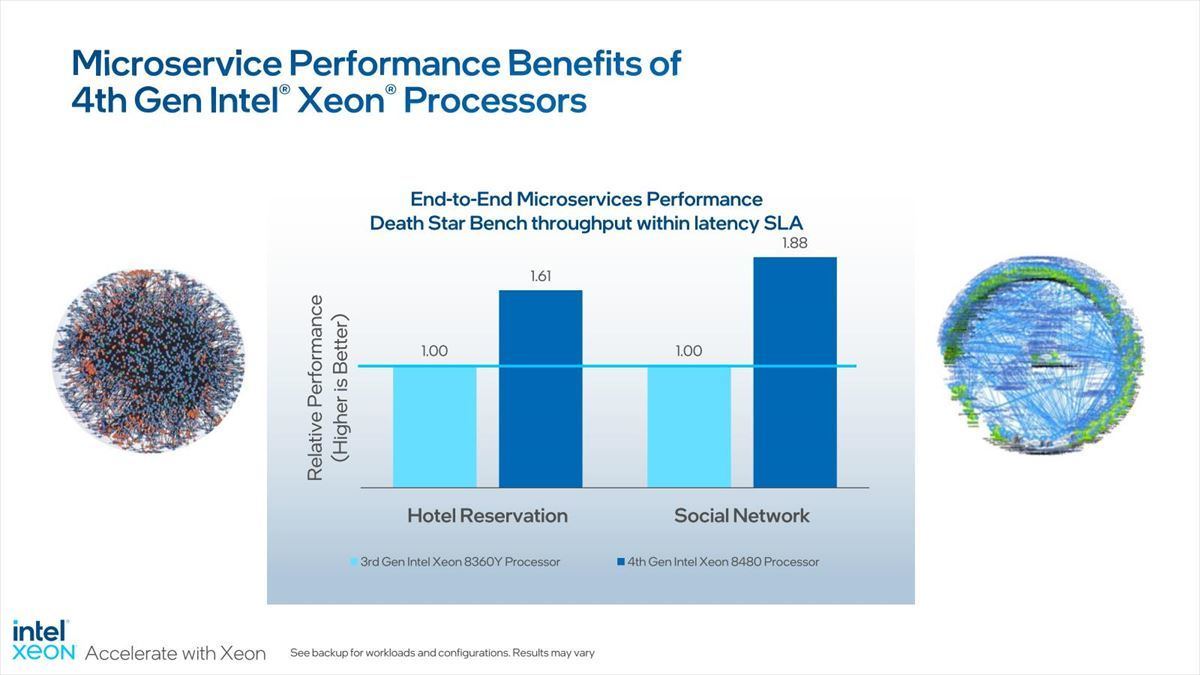
Photo11:こちらは第3世代Xeonスケーラブル・プロセッサとの比較となる

-
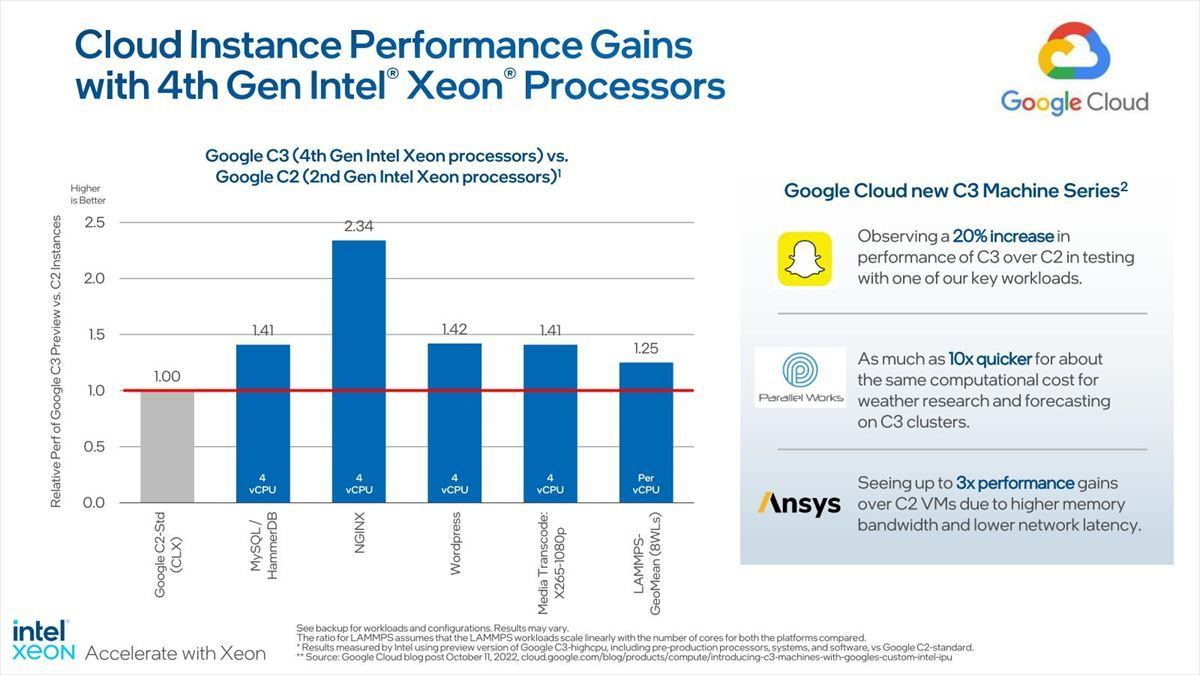
Photo12:こちらは再びCascade Lakeとの比較

-

Photo13:こちらは主にAI向けで、AMXを併用した場合の数字である。ただVMwareがvSANをAMXで高速化できる、というのはちょっと興味深い

ちなみに先ほどもちょっと触れたDLBであるが、これは複数のコアで負荷を均等に保つ仕組みである(Photo14)
-

Photo14:コアの負荷を均等にすることで、例えば動作周波数を下げやすくなる(=消費電力を減らせる)し、処理時間の均等化も図りやすくなる














