



AI & ML分野の性能
AI & MLに関しては特に力を入れている部分でもあり、AMXがフルに活用できる分野でもある。といっても、AI/MLと言われているものが要求する性能は、Networkによって違いがある(Photo22)。
-
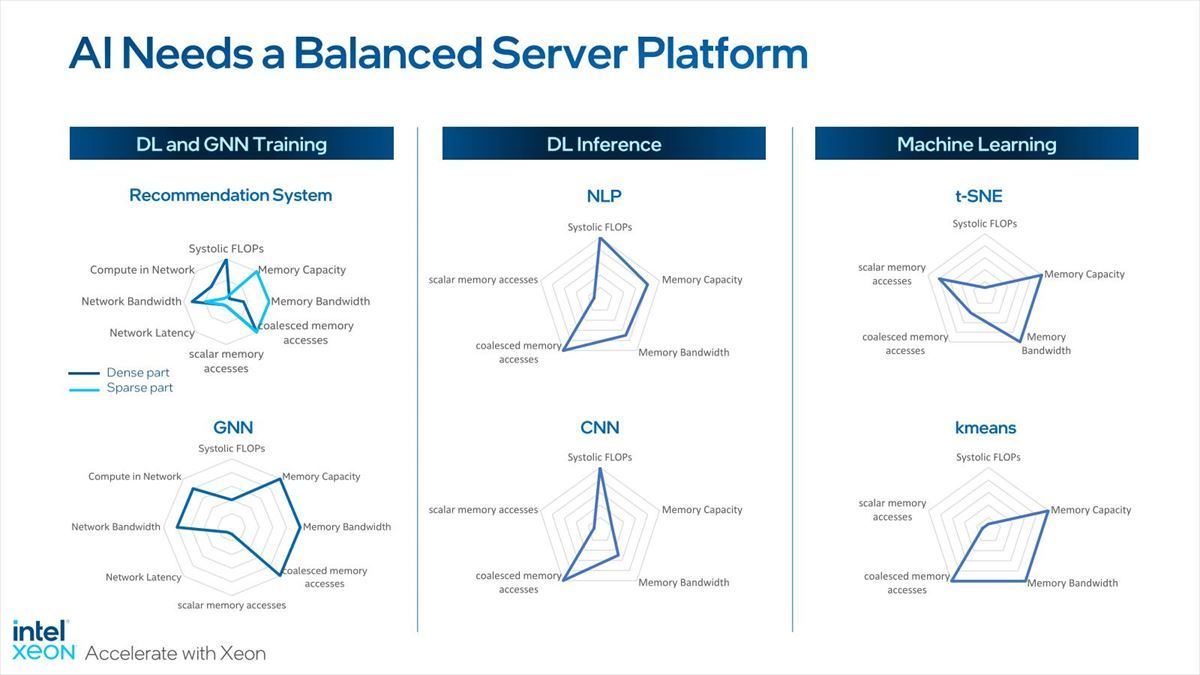
Photo22:まぁこれは当然Inference/Trainingによっても差が出てくる部分でもあるし、Sparse/Denseでも異なったりする

これを踏まえて、そもそもDDR5の採用やXeon MaxではHBM2eの搭載、さらに演算性能の向上など全般的な性能の引き上げを図ったうえでAMXを搭載し、特に畳み込みでの高速化を図るという形のアプローチになっている。
もともとVNNIで従来比3倍程度まで高速化している訳だが、AMXではこれをさらに8倍まで引き上げており(Photo23)、これで専用プロセッサに迫る性能を発揮するとする。
-
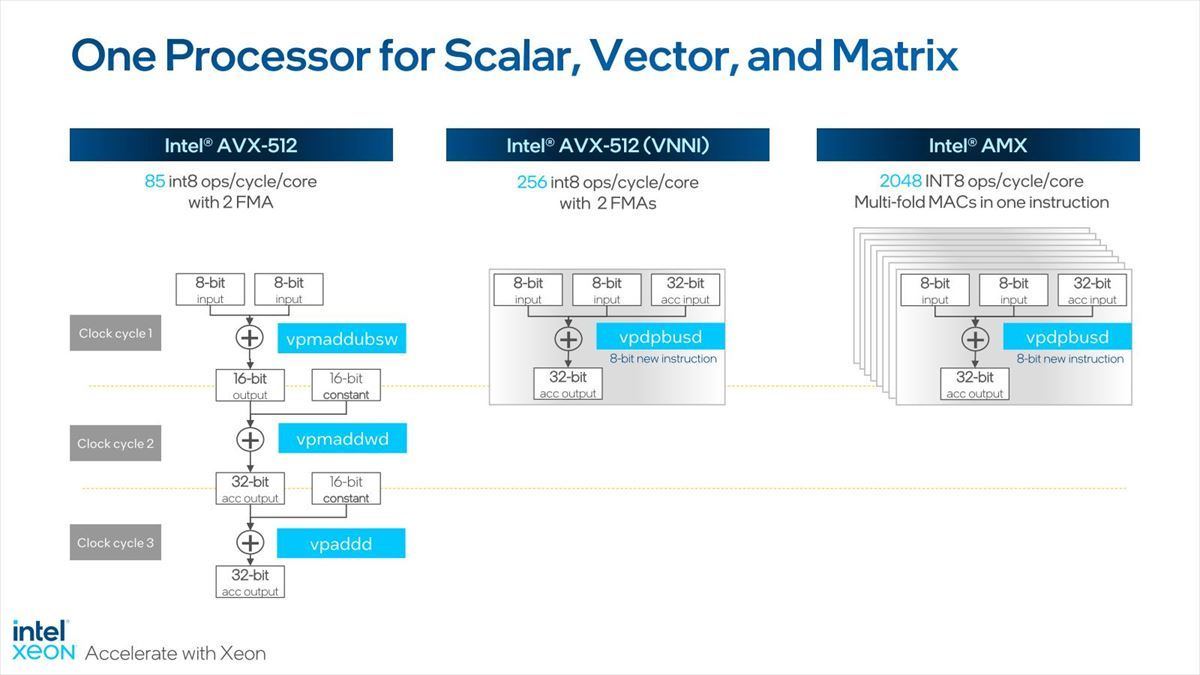
Photo23:ただ先にもちょっと書いたが、同時演算能力が高いがゆえに、小さい規模のネットワークだと逆に効率が上がり難い、というのがAMXの弱点ではある

実際、第3世代Xeonスケーラブル・プロセッサやNVIDIAのA10と比較した結果がこちら(Photo24)。
-
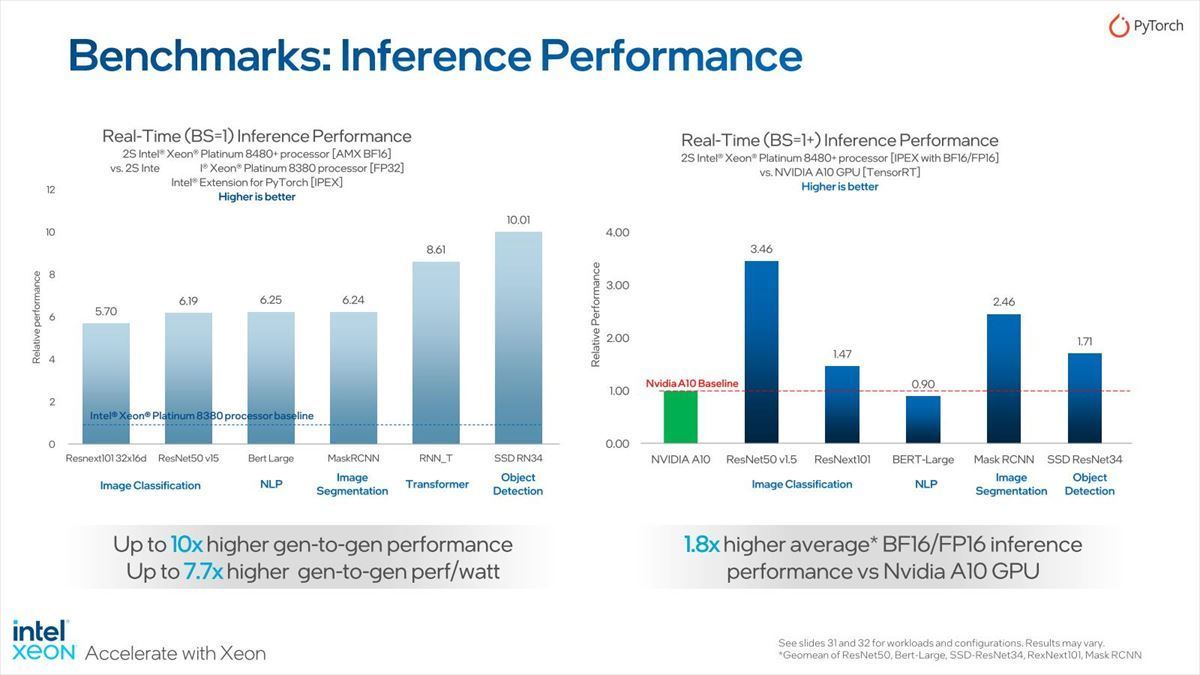
Photo24:ただしこれBatch Size=1なので、A10には非常に不利な条件なのは間違いない

あるいはBroadwell以降のコアと比較した場合、ResNet-50での処理性能と消費電力の関係を示したのがこちら(Photo25)。
-
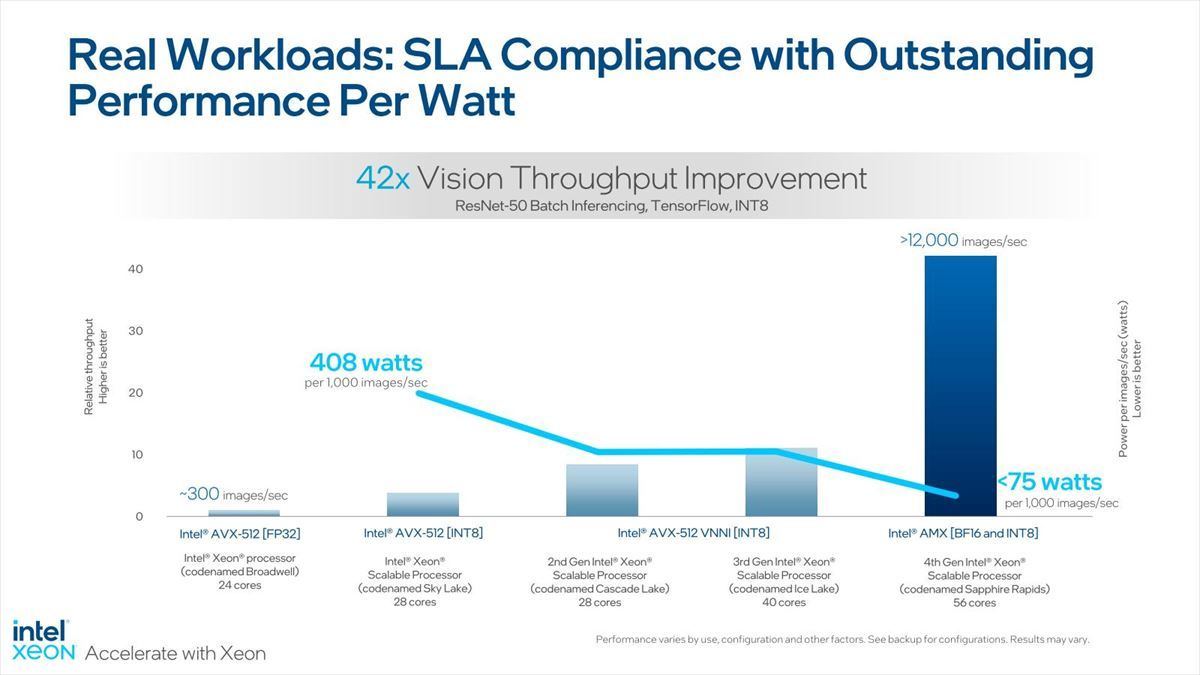
Photo25:BroadwellベースというのはXeon E3/5/7 v4の事

もっとも第4世代Xeonスケーラブル・プロセッサでInferenceをバリバリする、という使い方はどうか? という気もするが、ではTrainingは? というのがこちら(Photo26)。
-
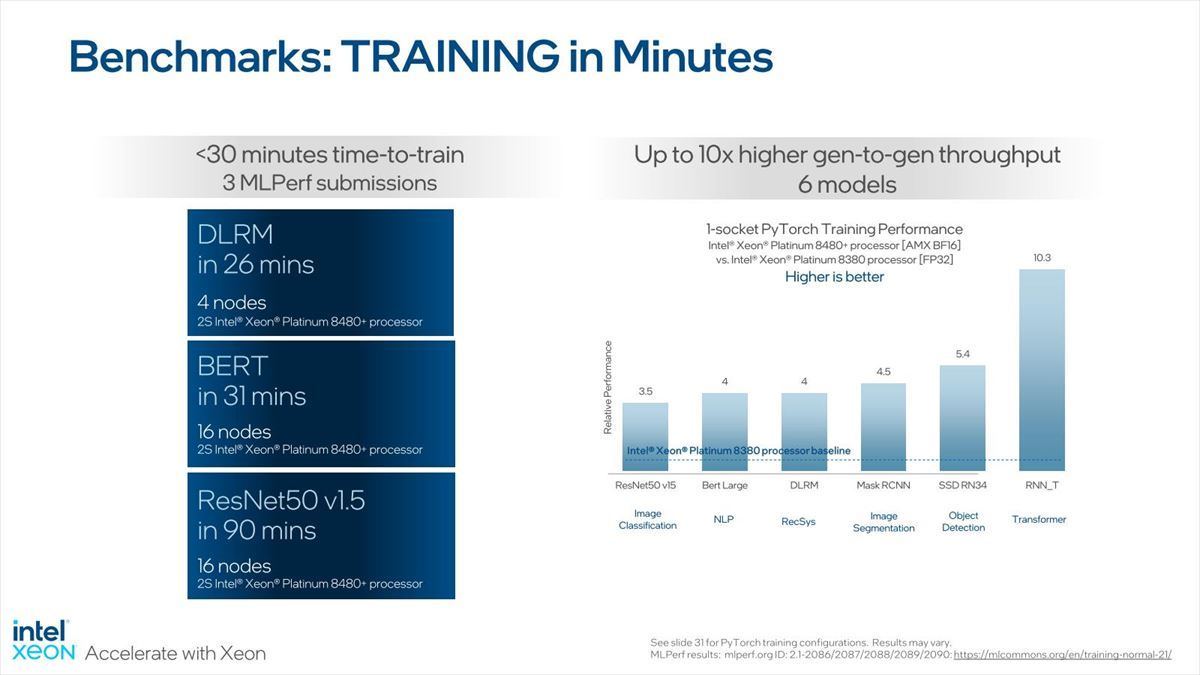
Photo26:ただこれGaudi 2と、どう使い分けるつもりなんだろう(本当に)

MLPerf v2.1(Training Benchmark)の8つのテストの内3つを30分未満で終わらせられるとしており、第3世代Xeonスケーラブル・プロセッサと比べて3.5~10倍高速であるとする。もっともAMXがあるから、この位上がらないとまずい気もするが。ちなみに今のところMLPerfについてはDLRM/BERT/ResNet-50の数字しか登録されていないので、他の結果も早く見たいところだ。このTrainingに関してのA100との比較がこちら(Photo27)。
-
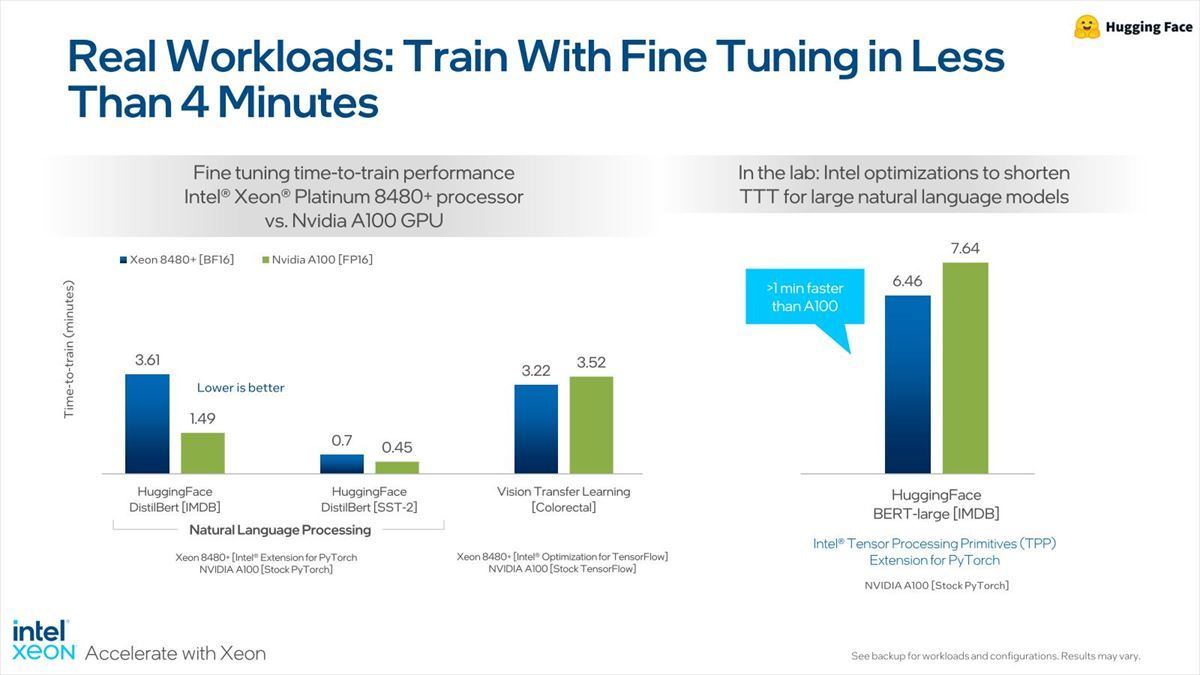
Photo27:というかNVIDIAはSapphire Rapidsの出荷開始を待ってDGX-H100の出荷をスタートした訳で、A100と比較しても、という感想しか抱けないのだが

大雑把に言えば互角と言ったところだが、そもそもA100と比較しても仕方ないという気はしなくもない。ただA100は一昔前のハイエンドGPUだった訳で、それと互角に近いところまで汎用CPUで迫った、という事は評価しても良いかと思う。
HPC分野の性能
HPCの場合もAIに似ていて、モノによってCompute BoundだったりMemory Boundだったり、あるいはその中間だったりする訳だが(Photo28)、ただ原則論としてはProcessor Performanceの向上に合わせてMemory Bandwidthも引き上げるしかない。
-

Photo28:もちろんCompute BoundだったらB/F値はどんなに低くても良い、という訳ではないので、つまるところバランスだったりするのはまぁHPCに限らずどんな分野でも同じことではあるが

で、第4世代Xeonスケーラブル・プロセッサはDDR5のサポートや、4 Socket以上ではMemory Channel自体も増えている事もあり、Memory Bandwidthが向上している(Photo29)。
-
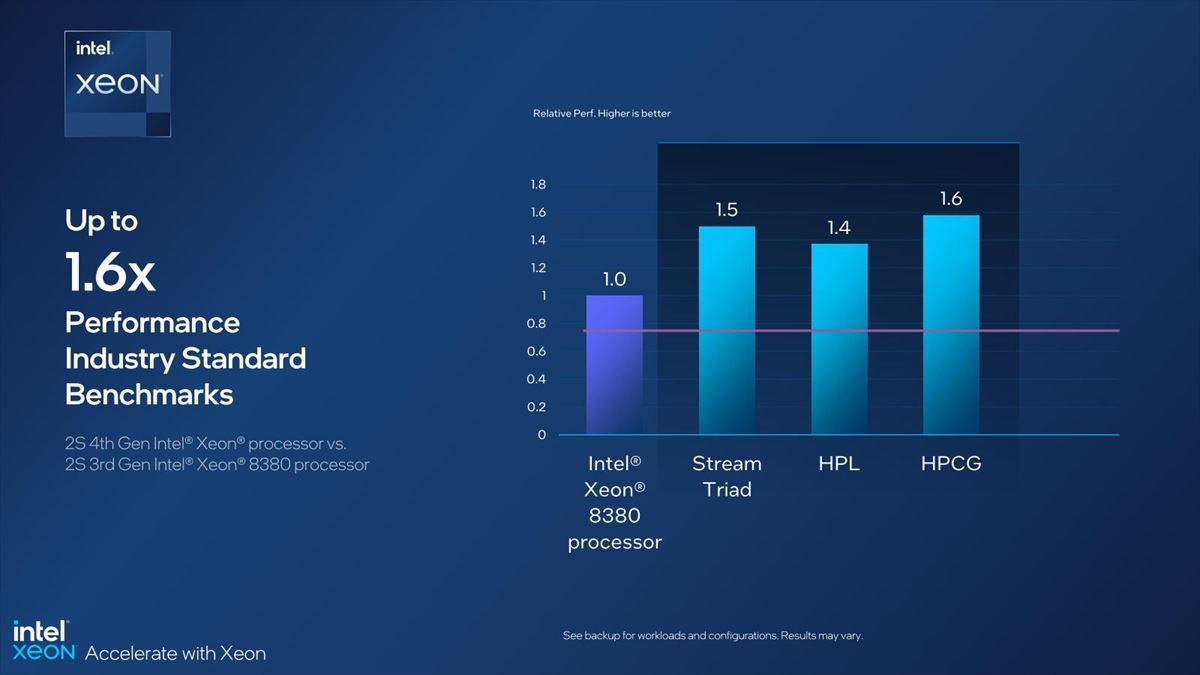
Photo29:2 SocketまでだとDDR4-3200×8chのIce Lake-SPベースとの比較になるから、理論帯域比でも1.5倍だが、4 Socket以上になるとDDR4-3200×6chのCooper Lakeベースとの比較になるので、理論帯域比は2倍、ベンチマークでも1.5倍前後の差になる

加えてProcessor Performanceもコア数とIPCの両方の向上もあって、分野によって差はあるとはいえ、平均50%程度の性能改善が実現している(Photo30)。
-
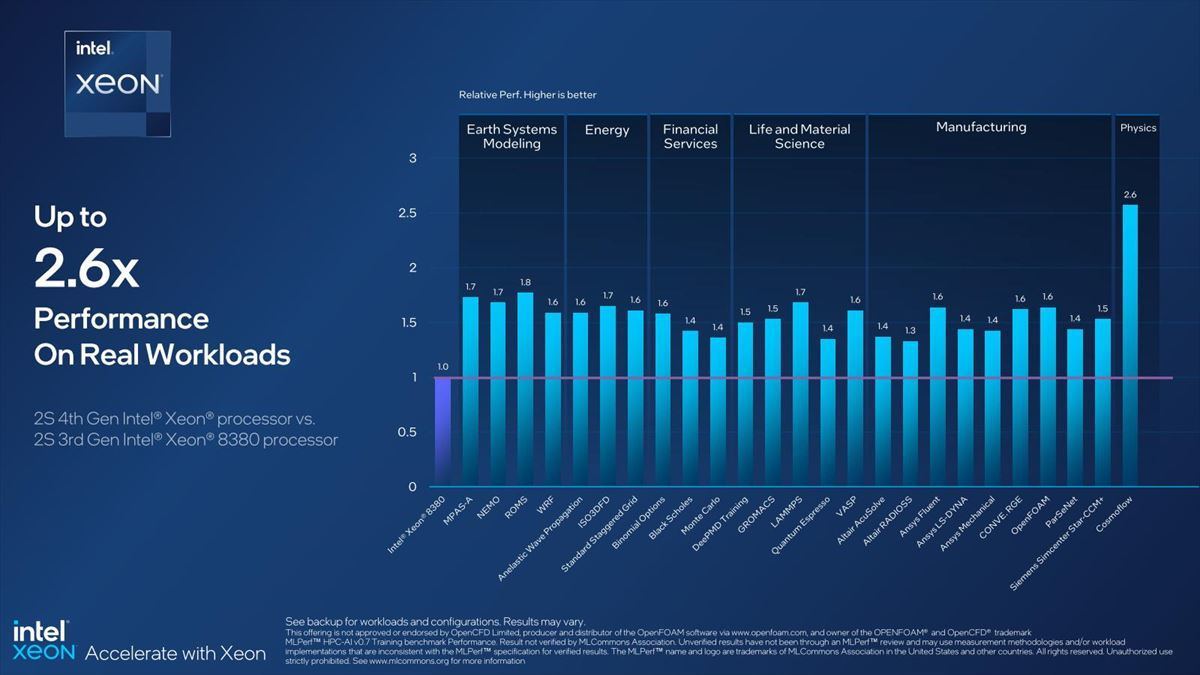
Photo30:これ、Xeon Platinum 8380の相手はXeon Platinum 9480だったりXeon Maxだったりと色々結果が混ざっているので注意は必要

この性能差を確保するための方法が、Xeon MaxのHBM2eである(Photo31)。
-

Photo31:多分性能だけ考えればHBM Only Modeが一番楽なのだろうが、容量が64GB(コアあたり1.1GB強)で足りるか? という問題がある

Sapphire Rapidsは8chのDDR5-4800を搭載し、トータルで307.2GB/secの帯域を誇るが、これを56コアで割るとコアあたりの帯域は僅か5.4GB/secでしかない。ところがHBM2eは1stackあたり409.6GB/secである。これが各Tile(=14コア)に1つ用意されるから、コアあたり29.3GB/secと、DDR5の5倍以上の帯域が利用できる事になる。これは、特にB/F値が問題になりそうなアプリケーションで効果的に働くという訳だ。ちなみにHBMとDDR5は、HBM Only/HBM Flat Mode/HBM Caching Modeの3つが用意される。昔、第3世代のXeon PhiことKnights HillではHBMの代わりにMCDRAMを搭載する予定で、ここではCache Mode/Flat Modeに加えHybrid Modeが用意されていた(Photo32)が、これはサポートされない事になった。
-
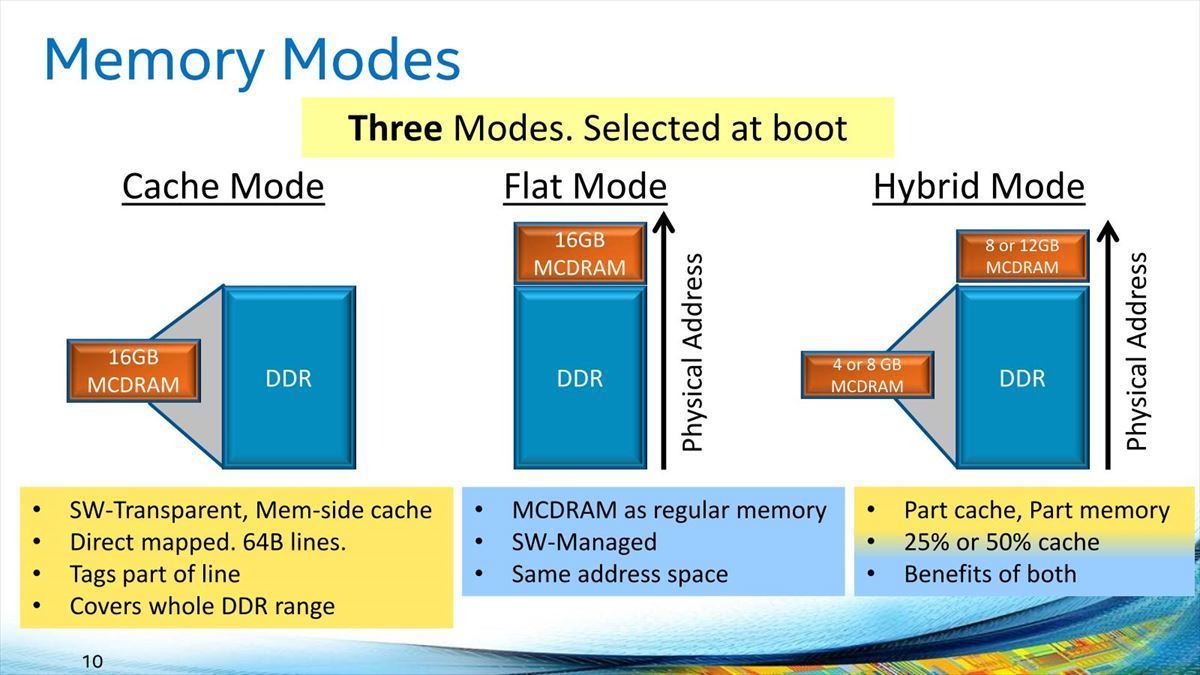
Photo32:これはKnight Hillのプレゼンテーション。HBM StackがTileあたり2つ以上あれば、Hybrid Modeも現実的だったかもしれないが、1つでは厳しいと判断されたのかも

さてそんなHBM2eを搭載したXeon Maxであるが、例えばALTAIR AcuSolveを行った場合、第3世代Xeonスケーラブル・プロセッサと同じ処理性能を遥かに少ないノード数で実現できるとしている(Photo33)。
-

Photo33:ノード数は1/4なのに消費電力は半分弱、ということはノードあたりの消費電力は結構増えているという計算になる訳で、これがSapphire Rapidsの弱点かもしれない。もちろん性能/消費電力比は向上しているのだが

Photo34はメモリ帯域比較で、これはもう理論性能そのままという感じである。もう少し広範なベンチマーク結果がこちら(Photo35)。
-
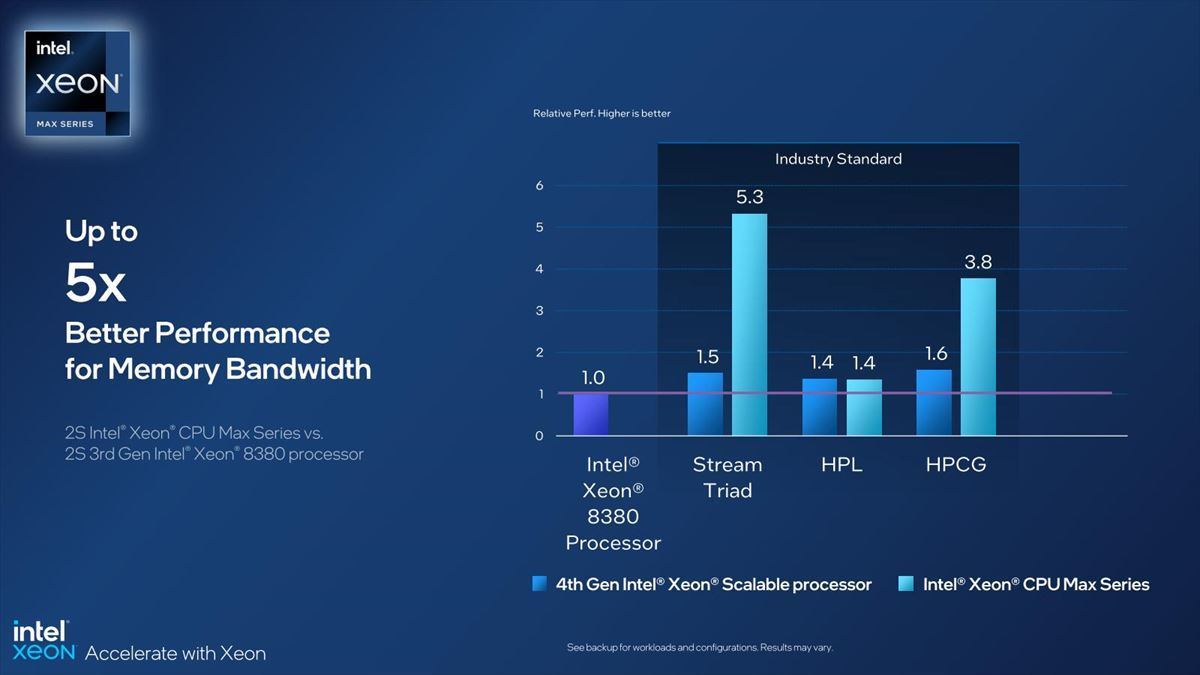
Photo34:HPLがあまり増えないのは、これはLinpackベースのベンチマークで、必ずしもMemory Boundではない事も関係している。多分ボトルネックはCompute側である

-
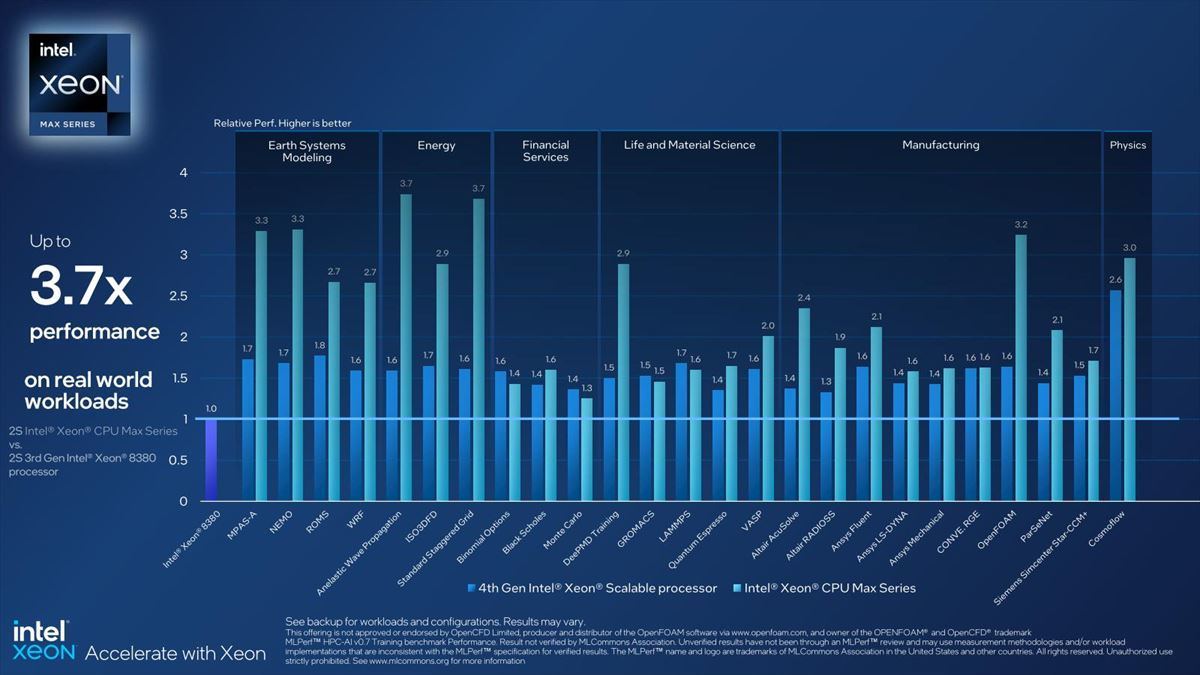
Photo35:青が第4世代Xeonスケーラブル・プロセッサ、水色がXeon Maxである

必ずしも全てのアプリケーションで性能が上がる訳ではない(中にはむしろ落ちる場合もある)が、うまくはまると3倍前後の性能向上を示しており、アプリケーションを選びはするものの、うまく嵌れば効果的であることを示している。
ちなみにXeon MaxのSKUは5製品であるが、それぞれの性格分けがこちら(Photo36)。どんなHPC Applicationを走らせるか次第でSKUを決める形になる訳だ。
-

Photo36:HPCという事もあってか、“Best Performance per Power”という軸が無いのはちょっとアレ。恐らくは9470あたりが一番それに近いのだろうが














