RMMAによる内部解析 - I-TLB Size(グラフ112~117)
こちらにも書いたがRYZEN 7 1800Xは3レベルのTLB構造になっている。これがどの程度の性能かということで見てみたい。ちなみにRMMAの情報によればこんな感じ(Photo74)である。
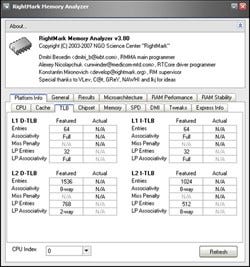
|
Photo74:L2 I-TLBは512 Entriesのはずだが、何故か1024/512 Entriesとなっている。発表の512 EntriesはLPの場合で、SPの場合は倍のエントリサイズになるということだろうか?もっとも今回のテストは64bit環境なので、結果はLPの場合になる |
まずNear Jump, Forward(グラフ112)である。0 Entriesの近傍がちょっとだけ下がっているが、これがL0 TLBと思われる。ただこの際のLatencyはほぼ2.5cycleということで、思ったほどには高速ではなかった。
続く64 EnrtiesのL1 TLBが4cycle程度、512 EntriesのL2 TLBが11cycleほどのLatencyとなっている。ちなみにL2 TLBが11cycleで検索できるのは250Entries弱で、その先はLatencyが増えている。これは検索に時間がかかるためだろうか。
合計で550Entryを超えたあたりでTLB MISSとなり、その先はキャッシュアクセスということでさらにLatencyが増しているが、これはCore i7-6950Xも同じことだ。この傾向はBackward(グラフ113)やRandom(グラフ114)、あるいはFar Jump(グラフ115~117)で一定であり、間違いないように思える。
このあたり、かつてのAMD FX-8150の方がずっと良い特性だったのだが、無理に性能を追求するのではなく、消費電力と性能のバランスを取ったようだ。
















