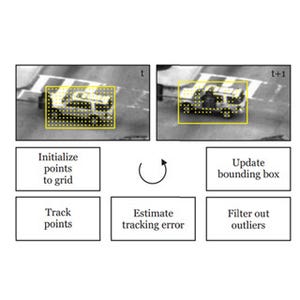
今回からは、「Semantic Image Segmentation」について、詳しく説明していきたいと思います。今回は、「Conditional Random Field (CRF)」を用いた手法をご紹介します。
Conditional Random Fieldとは?
まずは、CRFとは何かをみていきましょう。CRFは、系列ラベリングという問題を解く手法です。機械学習の中では識別モデルに分類され、構造学習を行えるものがCRFです。
系列ラベリングとは
文章のような文字の系列データに、主語、述語、目的語などのラベルを付与する問題のことです。入力が画像データの場合は、画素が2次元に配置された系列データとみなし、どの領域が人で、どの領域が道路で、といったラベルを付与することになります。
識別モデルとは
第15回で紹介したSVMやAdaBoost、Random Forestなどは、機械学習の中の識別関数に分類され、入力データが「人」なのか「人以外」なのかといったようにデータを分類するために用います。一方、CRFは機械学習の中の識別モデルに分類されます。SVMなどの識別関数は「人」「人以外」のようにデータを分類することためのものですが、識別モデルは、入力データがどのクラス(ラベル、カテゴリ)に属するかを確率値として求めることができます。
構造学習とは
構造学習とは、データを1つずつ「人」なのか「人意外なのか」を判別するのではなく、その前後、上下左右、または入力データ全体の関係性を考慮して全体として最適なラベルを付与する手法です。入力データが画像の場合は、人は道路の上に立っていて、人の上の領域は空である可能性が高いという構造関係を考慮して、人、道路、空を同時にラベリングすることになります。
つまり、画素が2次元に配置された入力データ系列に対して、人、道路、空の位置関係を考慮し、全体が最適となるようにどの領域が人で、どの領域が道路かを、確率的にラベリングすることができるのがCRFです。
Conditional Random Fieldを用いたSemantic Image Segmentation
CRFを用いたSemantic Image Segmentationの手法として、ShottonらがTextonBoostという手法[1]を提案しています。
この手法ではまず初めに、図1のように入力データに対して17種類のフィルタを畳み込み、注目画素近傍のテクスチャ情報を求めます。これを全画素に適用し、フィルタのレスポンスに対してK-meansクラスタリングを適用して、各画素に最近傍のクラスタの中央値を割りあてることでTexton mapを生成します。

|
|
図1 画素近傍のテクスチャ(Texton)の計算 |
そして、図2に示すように各注目画素iの近傍にさまざまなサイズ、位置の矩形領域を設定し、その矩形内に含まれるTextonをカウントし、そのレスポンスを特徴量として求めます。その特徴量をもとに、Boostingアルゴリズムにより各画素がどのラベル(物体)に属するかを学習し、識別します。この処理で、Semantic Image Segmentationの結果を得ることはできますが、精度が低く、特に物体の境界で多くのエラーが生じてしまいます。

|
|
図2 Texton mapからの特徴量抽出 |
そこで最後に、得られたラベリング結果を、CRFを用いて画像全体で最適化します。具体的には、数式1の条件付き確率を最大化しするように画像全体のラベル系列を求めます。1つ目のshape-textureは、前述のTexton mapとBoostingアルゴリズムを用いたラベルの推定結果、colorは各ラベルの色情報に関する条件、locationは各ラベルの画像の位置に関する条件、edgeは色が変化するエッジにおいて隣接画素が取り得るラベルの組み合わせに関する条件です。例えば空であれば、薄っすらとしたグラデーションの色・テクスチャを持ち、白から青色の色情報で、画像の上部に存在する可能性が高く、かつ木や建物と隣接する可能性が高い、という4つの条件から総合的に空か否かを判断することができます。

|
|
数式1 |
この手法により得られたSemantic Image Segmentationの結果は図3の通りです。CRF無しのBoostingアルゴリズムのみによるラベリング結果では、足や尻尾の細かい領域の精度が低いことがわかります。colorの条件を含むCRFを用いることで輪郭が明瞭になるとともに、足や尻尾の細かい領域も正しくラベルを付与することができています。

|
|
図3 TextonBoostによるSemantic Image Segmentation結果 |
今回は、CRFを用いたTextonBoostという手法をご紹介しました。近年、Semantic Image Segmentationの分野でもディープラーニングが大きな成果を上げています。十分な学習データ数を集められない場合など、ディープラーニング以外の少し古い手法の方が良い結果が得られることもあるので、今回ご紹介した手法も知っておくと良いでしょう。
参考文献
[1] Shotton J., Winn J., Rother C., Criminisi A.: Textonboost for image understanding: MuIti-class object recognition and segmentation by jointly modeling appearance, shape and context. International Journal of Computer Vision, Vol. 81, No. 1, pp. 2-23, 2009.
著者プロフィール
樋口未来(ひぐち・みらい)
日立製作所 日立研究所に入社後、自動車向けステレオカメラ、監視カメラの研究開発に従事。2011年から1年間、米国カーネギーメロン大学にて客員研究員としてカメラキャリブレーション技術の研究に携わる。
日立製作所を退職後、2016年6月にグローバルウォーカーズ株式会社を設立し、CTOとして画像/映像コンテンツ×テクノロジーをテーマにコンピュータビジョン、機械学習の研究開発に従事している。また、東京大学大学院博士課程に在学し、一人称視点映像(First-person vision, Egocentric vision)の解析に関する研究を行っている。具体的には、頭部に装着したカメラで撮影した一人称視点映像を用いて、人と人のインタラクション時の非言語コミュニケーション(うなずき等)を観測し、機械学習の枠組みでカメラ装着者がどのような人物かを推定する技術の研究に取り組んでいる。
専門:コンピュータビジョン、機械学習