Cerebras Systemsは300mmウェハの中で取り得る215mm角という最大サイズのチップ(chipの語源から、これをチップと呼ぶのは違和感があるが)のAIアクセラレータ「Wafer Scale Engine(WSE)」を開発した。次の写真で、右側のAndy Hock氏が持っているのがそのチップである。
2019年末、東京エレクトロン デバイス(TED)が代理店契約を結び、CerebrasのAIアクセラレータである「CS-1」を日本でも販売するという発表を行うため、Cerebrasの幹部2人が来日した際に、詳しく話を聞く機会をいただいた。


Cerebrasのウェハスケールエンジン(WSE)を搭載するCS-1システムの発表のために2019年末に来日した、同社の創立者の1人でチーフテクニカルオフィサー(CTO)のGary Lauterbach氏(左)とプロダクトマネジメントディレクタのAndy Hock氏(右)


世界最大サイズのチップは誰が考えたのか?
まず、Cerebrasという社名は、どのように決められたのかと聞いたところ、Cerebral Cortex(大脳皮質)から取ったとのことで、人間の大脳に匹敵するようなAIアクセラレータを作ることを目指しているという。
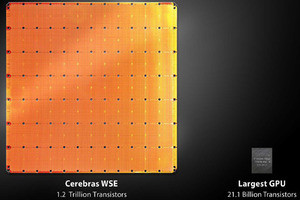
次の図に、Wafer Scale Engineの諸元とNVIDIAのV100 GPUとの比較を示す。チップサイズは56.7倍、コア数は78倍で、オンチップのメモリ容量は3000倍、メモリバンド幅は1万倍、ファブリックのバンド幅は3万3000倍と桁外れの規模である。
-

CerebrasのWafer Scale Engineの諸元とNVIDIAのV100 GPUとの比較を示したスライド (出典:2019年12月に開催された記者発表会でのHock氏の発表スライドを撮影したもの)

Wafer Scale Engineという巨大チップを誰が考えたのかと質問すると、CTOのLauterbach氏が、自分が提案したと答えてくれた。Lauterbach氏は、創立者でCEOのAndrew Feldman氏が、巨大チップはリスクが大きいと反対するだろうと思っていたのであるが、その案が通ってしまったという。
-

WSEの実チップ。100円玉と比べると、その大きさが良くわかる

巨大チップを作る上での問題
巨大チップを作る場合、一般に認識されている問題は、歩留まりと熱膨張係数のミスマッチである。
WSEは40万コアもの回路を集積しているので、不良が全く無い完全良品が採れるとは考え難い。そのため、一般的に取られる対策は、予備的に冗長の回路を作り込んで置き、不良のコアは予備の良品コアと繋ぎ換えて、見かけ上、不良の無いウェハスケールのチップを作り出すという方法である。WSEの場合は、同じ回路が沢山繰り返されているので、比較的少ない予備回路を置くだけでよいので、作りやすい。
もう1つの問題は、シリコンチップの熱膨張率は比較的小さいが、プリント基板の熱膨張率は何倍も大きく、温度が変わると、チップの端子とプリント基板の接触が確保できないという問題である。