話を元に戻そう。若干帯域の向上を施したPhenom IIであるが、Latencyは? ということで、グラフ35~38がAccess別のLatencyである。ことL1/L2に関しては全く差が見られず、基本的にはここでは大きくは手が入っていないと考えられる。おそらくは、先に書いた若干の改善程度なのだろう。
ではL3は? ということで、先のグラフ29~31とグラフ35~38のL3アクセス部を拡大したのがグラフ39~45となる。
面白いのは、ことL3の帯域そのものはPhenom X4 9950が一番高いこと。例えばグラフ39の場合、
Phenom X4 9950 : 3.42Bytes/cycle
Phenom II 940 : 3.11Bytes/cycle
Phenom II 955 : 3.26Bytes/cycle
となっていること。これはL3の管理をしているCPU内部のノースブリッジの動作速度に関係しているのかもしれない(Photo06,07)。それにしても、Read/Write共に3Bytes/cycle前後だから、Memoryに直接アクセスするよりは多少高速とは言え、Core i7のメモリアクセスより遅いのはちょっと問題であろう。特にCopyの場合、Phenom IIでは1.5Bytes/cycle程度であり、対するCore i7やCore 2は4Bytes/cycle程度を維持している。これだけ帯域が違うと、まぁ性能の大きな足かせになっても仕方が無い。
|
|
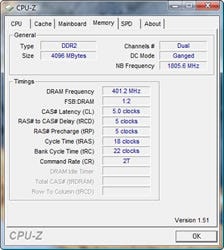
Photo06: Phenom II 940は、North Bridge Functionが1.8GHzで動作 |
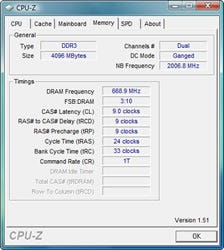
Photo07: Phenom II 955は、North Bridge Functionが2GHzで動作 |
ただLatencyに関してはグラフ42~45に示すとおり、若干ではあるが高速化されているようだ。特にグラフ44のRandom Accessの場合、2MB付近でのスコアはPhenom X4 9950が68Cycle程度を要しているのに対し、Phenom IIは55Cycle程度に収まっており、帯域はともかくLatencyの観点からはMemory Accessよりも大幅にコストが低く抑えられている事が見て取れる。この数字はCore i7とほぼ同等で、単にExclusive Cacheだから遅いとかいう単純な話ではなさそうだ。




















{kind=link}
{kind=link}