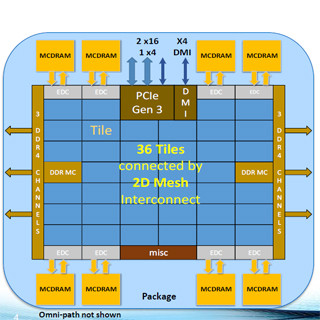
Knights Landingの性能
この基調講演で、一番、興味深いのは、それでKNLの性能はどうなったのか? という点である。
次の図はXeon E5-2697 v4(18コア、ベースクロック2.3GHz)2ソケットのシステムの性能を1.0とした相対的性能を示すもので、左端は基準のXeonで、その右はベンチマークのグループで、その中は左から順に、Linpack、DGEMM、SGEMM、HPCG、Stream Triadの性能である。2番目はTrinityベンチマークのグループ、3番目はライフサイエンス系アプリのグループ、4番目は気象シミュレーションアプリのグループ、5番目は物理とエネルギー関係のアプリのグループ、6番目は物質科学アプリのグループ、7番目は製造関係のアプリのグループ、最後は金融関係のアプリのグループの性能である。
LinpackやDGEMM、SGEMMでは1.6~1.7倍の性能である。Xeon E5-2697 v4が2ソケットで合計36コアで、ピーク演算性能は約1.3TFlopsであるので、ピーク演算性能が3.23TFlopsのKNLがこの倍率というのはちょっと物足りない性能である。その他のベンチマークを見ても1.2~1.8倍というものが多く、Flops比例の性能にはなっていない。メニーコアで、ある程度スケーラビリティが下がるのはやむを得ないが、スカラコアかメッシュネットワークか、どこかにボトルネックがあるような気がする。
しかし、Xeon E5-2697 v4 2個の消費電力は290Wになるのに対して68コアのKNLは215Wと小さい。Intelの希望小売価格では、Xeon 2個で60万円くらいであるのに対して、KNL(Xeon Phi 7250)は50万円位と多少安く、電力が低く、性能が若干でも高い分、お買い得という考え方も成り立つ。

|
|
各種のベンチマークやアプリの性能。Xeon E5-Xeon E5-2697 v4 2ソケットに対するKNL(Xeon Phi 7250)の性能比 |
次の図は、ホストCPU+NVIDIAのK80 GPUの性能を1.0とした時のKNLの性能を示すもので、LINPACKは1.2、Stream Triadは1.5、BlackScholes DPは2.0となっている。LAMMPSは5.0、グラフの右端はレイトレースの性能で、これらはTitanXと比較したものである。
しかし、NVIDIAの最新のTesla P100との比較ではないし、NVIDIAが書くとまったく逆の結果が出そうな絵である。

|
|
NVIDIA K80+HostとKNLの性能比較。右端の2本はTitanXとの比較 |
次のグラフは、 AlexNetとOverfeatという2種のディープラーニングの画像認識ネットワークのトレーニング(学習)とスコアリング(画像認識)の性能を、Xeon E5-2697 v4 2ソケットとKNLの間で比較したものである。AlexNetのトレーニングでは1.4倍強、AlexNetのスコアリングでは1.5倍、Overfeatのトレーニングでは1.7倍弱、Overfeatのスコアリングでは1.8倍の性能となっており、Linpackのベンチマークとほぼ同等の性能比である。まあ、ディープラーニングも行列積が計算の中心であるので、同様の比率になって不思議はない。

|
|
AlexNetとOverfeatの学習と認識の,Xeon E5-2697 v4 2ソケットとの性能比較 |
そして、次の図はAlexNetのトレーニングをKNLのマルチノードで実行した場合の性能で、16ノードで12.8倍、128ノードで52.2倍となっている。ディープラーニングの学習は、コア数に比例して通信が増えるので、ノード数が大きくなると、スケールが鈍化するアプリで、128ノードで52.2倍は、悪くない値である。

|
|
KNLマルチノードでのディープラーニングの学習性能。ノードでは12.8倍の性能、128ノードでは52.2倍の性能となっている |
Word2vecはGoogleの研究者が開発した単語を理解するニューラルネットで、次のグラフは、ノード数に対する単語の処理速度をプロットしたものである。青線がKNLでもう一方がNVIDIAのTitanXである。
この図に見られるように、KNLの方がリニアに近い伸びを示しており、64コアで246.8/9.2=26.8倍の性能になっている。

|
|
word2vecの性能比較。青線がKNLで64ノードで26.8倍の性能。NVIDIAのTitanXは4ノードで性能向上が鈍化し始めている |