



国立天文台(NAOJ)は、第30回「科学記者のための天文学レクチャー」を開催した。そのテーマは、「スーパーコンピュータが描く宇宙―アテルイIIからアテルイIIIへ―」。これまで、研究者を対象に天文学の研究専用のスーパーコンピュータとしてシミュレーション天文学を支えてきた「アテルイII(ツー)」の業績と、2024年12月2日より、岩手県奥州市のNAOJ 水沢キャンパスにて本格運用を開始した後継機「アテルイIII(スリー)」の特徴や、同機で現在進められている最新の研究などが紹介された。
-

国立天文台のシミュレーション天文学専用のスーパーコンピュータ「アテルイIII」。2024年12月2日より稼働開始。(c) 国立天文台(出所:NAOJ CfCA Webサイト)

ここでは、その取材をもとに全4回のシリーズでお届けする。第2回となる今回は、NAOJ 天文シミュレーションプロジェクト(CfCA)の滝脇知也准教授による解説「アテルイIIIの特性とサイエンスゴール」をもとに、アテルイIIIの特徴、アテルイIIとの性能比較、そして同機を用いた最新のシミュレーション結果を紹介する。
-

NAOJ 天文シミュレーションプロジェクトの滝脇知也准教授

理論演算性能は劣るのに計算時間は短縮されたのはなぜ?
天文学は、紀元前より長らく観測と理論の2大分野によって発展してきた。そして20世紀末ごろになってコンピュータの性能が向上してきた結果、第3の分野として“シミュレーション天文学”が登場。NAOJは、その頃からシミュレーション天文学に力を入れている、世界でも類を見ない天文学専用のスパコンを運用している研究機関。そして、そのようなNAOJにおいてシミュレーション天文学を担当している部門が、CfCAである。
アテルイシリーズの初代が登場したのは2013年4月のことで(2014年9月に大規模アップグレードを実施)、2代目の「アテルイII」は2018年4月に登場(2024年8月まで稼働)。アテルイIIIは、型番にNS-06とあるように、NAOJが運用するスパコンとしては通算6代目となる。その名称は、奈良時代の終わりから平安時代の初め(約1200年前)にかけて、現在の水沢付近に暮らしていた蝦夷の首長である「阿弖流為」にちなむ。朝廷の大規模な軍事遠征に対し、少数の蝦夷をまとめて勇敢に戦った人物であり、アテルイもその英雄のように大宇宙の真実に果敢に迫ってほしい、という思いが込められている。
アテルイIIIは、スパコンのタイプとしては、汎用のCPUを大規模に並列接続することによって構成される「スカラ型並列計算機」で、搭載CPUの性能を示す総理論演算性能は1.99Pflops、つまり1秒間に約1990兆回の浮動小数点演算を実行可能な実力を持つ。その最大の特徴は、特性の大きく異なる2種類のスパコンで構成されている点で、その2つとはメモリ転送バンド幅の広さを重視した「システムM」と、メモリの容量を重視した「システムP」である(総理論演算性能は、両システムの理論演算性能の合計を指す)。詳しいスペックは以下の通り。また、比較のためにアテルイIIのスペックも掲載した。
-

アテルイIIIは、メモリ容量重視のシステムPと、メモリ転送バンド幅重視のシステムMの2つのシステムで構成される。(c) 国立天文台(出所:NAOJ CfCA Webサイト)

【アテルイIIIシステム全体】
- 正式名称:NS-06 ATERUI III
- 機種・構成:スカラ型並列計算機 HPE Cray XD2000(水冷式)
- 総理論演算性能:1.99Pflops
- 総コア数:3万2396
- 総ノード数:288
- 消費電力:548kW(定格、冷却系を含む)
【システムM】
- 理論演算性能:1.4Pflops
- CPU理論演算性能:3.4Tflops
- 1ノード理論演算性能:6.8Tflops
- CPU:Intel Xeon CPU Max 9480
- コア数:2万3296
- 1ノードあたりのコア数:112
- ノード数:208
- メモリ転送バンド幅:665TB/s
- 1ノードあたりのメモリ転送バンド幅:3200GB/s
- メモリ量:26.6TB
- 1ノードあたりのメモリ量:128GB
【システムP】
- 理論演算性能:0.57Pflops
- CPU理論演算性能:3.6Tflops
- 1ノード理論演算性能:7.168Tflops
- CPU:Intel Xeon Platinum 8480+
- コア数:8960
- 1ノードあたりのコア数:112
- ノード数(1ノード2CPU):80
- メモリ転送バンド幅:98.24TB/s
- 1ノードあたりのメモリ転送バンド幅:614GB/s
- メモリ量:40.96TB
- 1ノードあたりのメモリ量:512GB
【アテルイII】
- 理論演算性能:3.087Pflops
- CPU:Intel Xeon Gold 6148
- コア数:4万200
- ノード数:1005
- メモリ転送バンド幅:257.28TB/s
- 1ノードあたりのメモリ転送バンド幅:256GB/s
- メモリ量:385.9TB
- 1ノードあたりのメモリ量:384GB
-

システムP(上)とシステムM(下)のブレード。それぞれの右にあるのは、それぞれが搭載するCPU。(c) 国立天文台(出所:NAOJ CfCA Webサイト)

-

アテルイIIIのシステム全体、システムM、システムP、アテルイIIのスペック。カッコ内の数字は1ノードあたりの諸元(出所:NAOJ CfCA Webサイト)

アテルイIIIは、アテルイIIの稼働開始から6年半以上が経ってのリプレースであるため、性能があらゆる面で大幅に向上したものと想像されるところだが、実はそうではないという。理論演算性能だけを見れば、アテルイIIの3.087Pflopsに対し、アテルイIIIは1.99Pflopsであり、1Pflops以上も下回っている。これではスペックダウンのように見えてしまうが、スパコンのトータル性能や使いやすさは、理論演算性能だけでは決まらないし、計算するシミュレーションの種類によっても変わってくるのだ。
シミュレーション天文学では、扱う内容によってスパコンに求められる性能が異なる。同天文学では、大別して「重力多体」、「流体」、「放射輸送」の3種類のシミュレーションがあり、単体もしくはそれらの組み合わせで行われる。この中で、理論演算性能の向上よりもメモリ転送バンド幅を広げることの方が計算の高速化にとって重要となるのが、超大質量ブラックホールの周囲にある降着円盤や、星が生まれる星間雲などを扱う流体シミュレーションだ。
流体シミュレーションは、プログラム中の演算数(足し算、引き算、掛け算などの回数の合計)に対して多くの変数を必要とするため、計算速度の向上にはCPUとメモリの間でやり取りできる情報通信量を表すメモリ転送バンド幅が重要となる。より正確にいうと、理論演算性能とメモリ転送バンド幅のバランスが重要だといい、これは、試験会場のようなイメージで捉えることができるとする。近年のスパコンの理論演算性能の向上は、コア数の搭載数の増加によるところが大きく、いわばテストの回答者が増えたことに例えられる。しかし計算を行うには、メモリからデータを読んでCPUに送る必要がある。これは、答案用紙を回答者に配ったり受け取ったりする先生のような役割。要は、近年は回答者の数が増えているのだが、先生の数やその能力が不足しがちな状況となっているのである。実際にアテルイIIでは、多くのアプリケーションにおいて、メモリ転送バンド幅の狭さが原因で計算速度の低下を招いてしまっていたことから、アテルイIIIでは、メモリ転送バンド幅を重視したシステムMが用意されたのである。
-

メモリ転送バンド幅重視のシステムMが得意とする流体シミュレーションの例。画像は、法政大学/米・プリンストン大学の松本倫明教授が2018年に発表した、連星系の形成シミュレーション(アテルイIIによる成果)。連星系の周囲にできたガスの円盤から、さらにそれぞれの星に向かってガスが落下している様子を確認できる動画がYouTubeに公開されている。(c) 法政大学/プリンストン大学 松本倫明教授(出所:NAOJ CfCA Webサイト)

これまで、アテルイ→アテルイ(アップグレード)→アテルイIIと進むにつれ、理論演算性能とメモリ転送バンド幅のバランスを表す、メモリ転送バンド幅を理論演算性能で割った「実バイト/フロップス(B/F)」の値はどんどん悪化していたという(初代が約0.3→初代アップグレードが約0.14→アテルイIIが約0.08)。つまり、メモリ転送バンド幅が広がらないのに対し、理論演算性能だけが上がってしまっていたのである。先ほどのテストのイメージなら、せっかくテストの回答者の人数はどんどん増えているのに、先生がずっとひとりのままで、答案用紙を配るのに時間がかかっているような状況だ。
世の中のスパコンの実B/Fは大半が1以下であり、計算結果にかかる時間を左右する要素は、理論演算性能よりもメモリ転送バンド幅の方が大きい。もちろん場合にもよるが、要はメモリ転送バンド幅が広いほど、間違いなく計算にかかる時間を短縮できるのである。
しかし、このメモリ転送バンド幅を上げることは容易ではない。そこでシステムMでは、アテルイIIで採用されていたDDRメモリをやめ、半導体を三次元的に多層構造にして一度に多量のデータをやり取りできるようにしたHBMメモリ(HBM2e)を採用したとのこと。その結果、アテルイIIに比べて12.5倍と、大きくメモリ転送バンド幅が向上したのである。
ところがHBM2eメモリはまだ高額なため、大量搭載はコストの観点から厳しい(システムMのメモリ容量は26.6TB)。すると今度は、重力多体シミュレーションが不得手になるという別の問題が生じてしまう。同シミュレーションは惑星系や銀河系、さらには宇宙の大規模構造などいくつもの天体を扱うもので、計算量と総データ量が多いため、メモリ容量が必要とされるシミュレーションである。そこでメモリ容量の少ないシステムMをカバーするため、アテルイIIIでは、メモリ容量を重視したシステムPも用意されることになったのである。
-
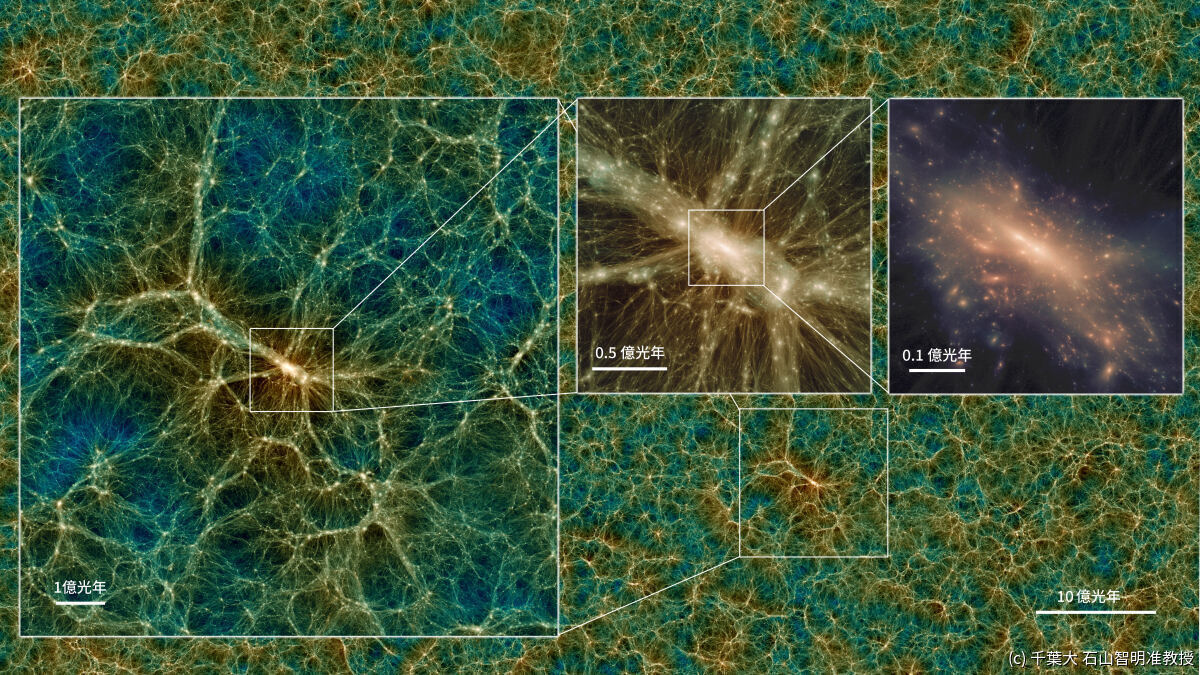
メモリ量重視のシステムPが得意とする重力多体シミュレーションの例。千葉大の石山准教授らが2021年に発表した、世界最大規模のダークマター構造形成シミュレーション「Uchuuシミュレーション」による宇宙の大規模構造(アテルイIIによる成果)。明るい部分ほどダークマターが多く集まっている。図中の囲みはこのシミュレーションで形成され一番大きい銀河団サイズのハローを中心とする領域を順々に拡大しており、最後の図は一辺が約0.5億光年に相当。(c) 千葉大 石山智明准教授(出所:NAOJ CfCA Webサイト)

システムPではHBM2eメモリに比べて安価なDDR5メモリが採用され、40.96TBを搭載。総メモリ容量ではアテルイIIの385.9TBに比べるとおよそ1/10だが、1ノードあたりではアテルイIIの約1.3倍となる512GBを搭載しており、性能向上が図られている。このようにアテルイIIIでは扱うシミュレーションの内容を要求B/Fと要求メモリ量の2つの要素で分類し、適したシステムの使い分けを行うことで、計算速度の短縮を図っているのである。
アテルイIIIの試験的シミュレーション事例も報告
アテルイIIIは本格稼働してまだ日が浅いが、試験的にいくつかのシミュレーションが実施済みだ。その1つが、NAOJ CfCAの岩崎一成助教による「分子雲の形成」である。-263℃という極低温の濃密な星間ガス雲において、星の卵となる分子雲が作られていく一連のプロセスをシミュレーションしたものだ。もう1つが、NAOJ CfCAの三杉佳明特任研究員による、強い磁場に貫かれたフィラメント状分子雲において、星の母体である分子雲コアが合体していく様子を扱った「分子雲コアの合体」である。どちらもシステムMでシミュレーションを実施し、その結果アテルイIIを利用した際のおよそ半分の時間にまで短縮できたという。
-

NAOJ CfCAの岩崎助教による「分子雲の形成」シミュレーション(システムM使用)。黄色いほど高密度となる分子雲(中央)は、赤いほど高温となる温度が大きく変化する原子ガス(左)が集積することで成長する。分子雲内部は細長い微細構造に満ちており(右、中央の拡大図)、このような細長い構造の中で星が生まれる。計算時間は、アテルイIIの約半分になったという。(c) 国立天文台(出所:NAOJ CfCA Webサイト)(出所:NAOJ CfCA Webサイト)

-

NAOJ CfCAの三杉特任研究員による「分子雲コアの合体」シミュレーション(システムM使用)。強い磁場に貫かれた乱流を持った細長いフィラメント構造におけるコアの合体現象を計算した初の研究成果だ。白線は磁力線、コントア(図中の、等高線のような値が等しい点を結んだ線)は等密度面が示されている。通常、強い磁場を持つ環境で単一のコアから多重星を形成することは困難だ。しかし、このような合体現象は多重星の形成につながる可能性があるため、星形成の多様性を理解する上で重要な現象だという。また、星およびその周囲で起こる惑星形成の現場である星周円盤に非定常な質量供給が起こることが予想されるため、現在の孤立した環境下における惑星形成モデルを大きく変える可能性があるとしている。こちらの計算時間も、アテルイIIの約半分になったとした。(c) NAOJ CfCA 三杉佳明特任研究員(出所:NAOJ CfCA Webサイト)

「アテルイIIIの特性とサイエンスゴール」の解説を担当した滝脇准教授は、星の最期の瞬間に未解明な点が多いことから、さまざまな星の死と爆発的天体現象に関する研究を行っている。滝脇准教授自身は、アテルイIIIで「超新星爆発シミュレーション」を実施したといい、滝脇准教授は今後、超新星爆発、ガンマ線バースト、ブラックホール生成、パルサーやマグネターなどの中性子星の生成プロセスを統一的に理解することを目的に、元の星の質量、自転速度、磁場の強さをかけてアテルイIIIで100のモデルをシミュレーションする「100超新星プロジェクト」を実施する計画とした。
なお、アテルイIIIの利用は、シミュレーション天文学の研究であれば、研究者は無料で利用することが可能だ(もちろん研究内容の審査はある)。そして運用(リース契約)期間は2031年3月31日までとなっている(スパコンは基本リース契約の形を取る)。NAOJ CfCAを率いる小久保英一郎教授によれば、その後はまだ未定だが、個人的には、NAOJも属する自然科学研究機構の複数研究機関を対象に、合同でより高性能なスパコンの運用を可能なら実現させたいとしている。













