シリコンバレーのDe Anza Collegeで2018年8月19日から21日にかけて開催された「Hot Chips 30」において、富士通のアドバンストシステム開発本部 プロセッサ開発統括部 第一開発部の部長の吉田利雄氏が日本の次期フラグシップスパコンであるPost-Kシステムのプロセサについての発表を行った。
-

Hot Chips 30でPost-KスパコンのCPUについて発表する富士通の吉田利雄氏

SPARCからArmに変わっても生き続ける富士通のDNA
富士通は、6月にフランクフルトで開催されたISCでPost-KスパコンのCPUチップのパワーオンを発表したが、この時には、チップの概要の発表であり、今回が中身についての初めての詳しい発表であるので注目を集めた。
富士通はこれまでSPARCアーキテクチャのプロセサを開発してきており、京コンピュータのCPUもSPARCアーキテクチャのプロセサであった。しかし、SPARC陣営の仲間であったOracleが、昨年9月にSPARC CPUやSolaris OSの開発エンジニアを大量にレイオフしたとのうわさが流れ、事実、それ以降はOracleからは新しいSPARCプロセサは発表されておらず、仲間がいなくなってしまった。
このような状況では、仲間集めが重要なオープンソフトの波には乗れないので、富士通はPost-KスパコンではSPARCからArm陣営に乗り換え、Armと協力してArmのベクタ拡張であるSVE(Scalable Vector Extension)を開発した。
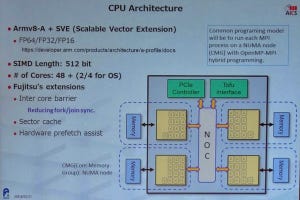
富士通のPost-Kプロセサは、Arm V8-A SVEアーキテクチャの命令を実行するプロセサであり、「A64FX」プロセサと呼ばれる。命令アーキテクチャはArm V8-A SVEであるが、ハードウェアの中身は富士通のプロセサのDNAを受け継いでおり、メインフレームで培った高信頼度設計、SPARCサーバで磨いた高性能と柔軟性、そして、京コンピュータで実現した高い電力効率などの富士通の設計が生きている。
いうなれば、喋る言葉はSPARCからArmに変わったが、中身の人間は、富士通のDNAを受け継いだ人間であるということである。
今回の発表ではA64FXプロセサの消費電力は発表されなかったが、かなり低電力のグリーンなスパコンになっているという。そこで吉田部長に、低電力になった理由にArmアーキテクチャに替えたことがどの程度貢献しているかと質問したところ、まったく関係ない。低電力化は富士通のマイクロアーキテクチャの改善によるという答えであった。
-

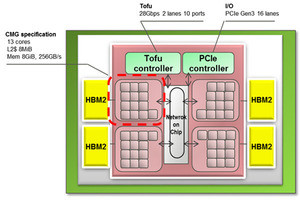
Post-KのA64FXプロセサはArm V-8A SVE命令を実行するが、富士通のメインフレームの高信頼性、SPARCサーバの高性能、柔軟性、京コンピュータの高エネルギー効率を受け継いでいる (出典:この連載のすべての図は、Hot Chips 30における富士通の吉田氏の発表スライドのコピーである)

7nm FinFETを採用するA64FXプロセサ
A64FXプロセサは、(1)HPCやAIでは汎用CPUを大きく超える高性能を持ち、(2)512バイト長のベクタ演算を2パイプ並列で実行、HBMによる高メモリバンド幅、48コアによる並列計算、Tofuインタコネクトによるスケーラビリティなどによる高スループット、(3)DGEMMなどではピーク演算性能の90%以上のFlops、Stream Triadではピークメモリバンド幅の80%以上の性能を発揮する高効率を持ち、(4)Arm V8.2A +SVAとSBSA(ARM Server Base System Architecture)に準拠する標準アーキテクチャのCPUである。
-

A64FXは、高性能、高スループット、高効率のArm V8.2-AとSVSAに準拠するプロセサである

Arm V8-Aアーキテクチャのプロセサは、昔から使われている32bit長のAArch32命令と、新しい64bit長のAArch64命令という2つの命令形式をサポートしている。しかし、Post-Kのような使い方では、AArch32のソフトウェア資産があるわけではないし、わざわざ古いAArch32でプログラムを開発する必然性もないので、A64FXではAArch64だけのサポートとなっている。
使用する半導体プロセスは7nmのFinFETプロセスであり、トランジスタ数は8,786Mとなっている。そして、1チップに48個の計算コアと4個のアシスタントコアを集積するメニーコアプロセサとなっている。
マルチコアで生じる処理時間のバラつき「OS Jitter」
多数のプロセサコアで並列計算を行うスパコンでは、計算の一番遅いコアで全体の処理時間が決まってしまう。全部のコアが同じ処理をしていれば良いのであるが、OSを走らせるコアではI/Oの割込処理などが行われて、長く時間が掛かる場合があり、このため、処理時間にバラつきが出てしまう。このバラつきをOS Jitterと呼ぶ。
OS Jitterが発生すると、割込処理などを行うコアの処理完了タイミングが遅くなるだけでなく、そのコアの処理完了を待ち合わせる他のコアの処理完了も遅れてしまい、全体として処理性能が下がってしまう。
このため、割込処理などはアシスタントコアにやらせて、計算コアの処理完了時間がバラつかないようになっている。
なお、物理的には計算コアもアシスタントコアも同じものであり、使い方が違うだけである。
A64FXチップのピーク演算性能は2.7TFlops超
そして、A64FXチップのピーク演算性能は2.7TFlops超と発表された。A64FXのコアは512ビット長のベクトル演算器を2つ持っているので、1サイクルに16個の倍精度浮動小数点の積和演算を実行することができる。2700GFlops÷32演算(積と和演算の合計)÷48コア=1.76GHzとなり、クロックは1.76GHz程度と推測される。
そして、メモリは4個のHBM2(3次元積層メモリ)を使っている。HBM2を使うとメモリ容量は32GB決め打ちでDIMMのように増設はできないが、1024GB/sという高いメモリバンド幅が得られる。
さらに計算ノード間を接続するTofuインタコネクトのコントローラもCPUチップに内蔵している。Tofuインタコネクトのトポロジは、京コンピュータと同じ6次元のMesh/Torusである。1本のインタコネクトの伝送バンド幅は送受ともに28Gbit/sであり、10本のポートで同時に伝送を行うことができる。これは現在のTofuインタコネクトの2.8倍のバンド幅となっている。
次の図の中の表には、A64FXとその現在の富士通のFX100スパコンとSPARC V9 CPUの諸元の比較が載っている。
-

A64FXは64bitのAArch64アーキテクチャだけをサポートし、それに加えてSVE命令をサポートしている。7nmのFinFETプロセスで作られ、8,786Mトランジスタを集積する。チップは52個のプロセサコアとTofuインタコネクトのコントローラ、PCIeコントローラを持つ。メモリには4個のHBM2を使用している

(次回は8月30日に掲載します)