英Armは2020年9月30日に「Neoverse V1」および「Neoverse N2」の概略を発表したが、4月27日にこれらについてもう少し細かい情報を公開した。事前説明会の資料を基にこれをご紹介したい。
前回のロードマップではNeoverse V1こそすでに提供開始されていたものの、Neoverse N2に関してはまだ未提供という状況であった。今回はこれがどちらも提供開始に切り替わっている(Photo01)。このNeoverse N2の提供開始を受けての今回の発表、という形になったようだ。
-

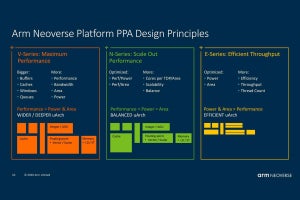
Photo01:実はNeoverse V1とN2は思った以上に異なっていた

さてNeoverse V1とN2のポジショニングであるが、Neoverse V1は完全にHPC向けのアーキテクチャで、コアあたりの性能(≠スレッドあたり性能)が競合と同等で、性能/消費電力比が良いあたりを狙い、Neoverse N2はスレッドあたり性能が競合と同等で、性能/消費電力比を大幅に引き上げる、というあたりが狙いとなっている。
-

Photo02:どちらのコアもSMTは採用していないので、つまりNeoverse N2はコアあたりの性能は競合(つまりx64)より低くても良い、という割り切りである

さて、そのNeoverse V1であるが、やはり内部構造は以前推察した通りCortex-X1をベースにしたもの、という公算が高そうだ(Photo03)。
-

Photo03:ただしIssueに関してはおそらく再設計が行われている模様。主にNEON/SVEあたりだろうか。というか、NEONも搭載しているのが驚きである

Cortex-X1の内部構造はこちらであるが、こちらはIssueが10-wideである。一方Neoverse V1は15-wideになっているが、恐らく増えているのはSVEに絡む部分と思われる。4×ALU、2×BRとかは完全に一緒である。もっともNeoverse V1ではFetchが8-wideとなっており、5-wide FetchのCortex-X1とはちょっと異なる部分だが、Decode/Renameが8-wideというのは一緒である。また確認したところ、Neoverse V1はベースがArmv8.4-Aで、そこにArmv8.5-A/8.6-Aの幾つかの命令が追加されている、という話であったので、Armv8.6-A完全対応のMatterhornベースとも異なる事がはっきりした。となると、まぁCortex-X1しかない、ということになる。
余談になるが、こちらはHPC向けコアということもあり、Memory Subsystemが異様に充実している。厳密には後述するCMN-700の機能であろうが、HBM3やDDR5に加えて、CXL 2.0経由でのアクセラレータ接続や、CCIXによるマルチコアの接続にも対応している。
このNeoverse-V1、とにかくHPC系の性能強化が最大のポイントであり、またまた恐らくはA64FXのお陰で切り開いたHPCアプリケーションとの互換性重視(こちらで書いたように、SVE2を実装してしまうとIDレジスタに関して書き換えが発生する)もあってSVEの実装となっているが、ことHPC向けという観点で言えばSVE2で追加されたNEON互換命令は別に要らない(というかNEONはそのまま実装されているっぽいので、SVE2の必要性がない)というあたりが理由と思われる(Photo04)。
-

Photo04:Neoverse N2と比べても性能が高いのは、Neoverse N2が128bit×2なのに対しNeoverse V1では256bit×2構成であるのが主な理由と思われる

Vector WorkloadでNeoverse N1比1.8倍、MLが4倍、FPUで2倍、といった形でHPC向けに最適化されたコアとなった格好だ(Photo05)。
-

Photo05:MLはbFloat16のサポートが主な理由であろう(FPUの性能が2倍であり、さらにNeoverse N1はbFloat16のサポートがなくFloat32のみになるから、ここでさらに2倍になる)

さて、一方Neoverse N2であるが、こちらは先に書いたようにSMT構成のコアよりもスレッドあたり性能と消費電力あたり性能を引き上げるのが目標となっている(Photo06)。
-

Photo06:左はまぁ言いたいことは判るのだが、実際にはx64が全部SMTになっている(IntelはついにAtom系列までSMTを導入した)事を考えると案外にバランスは難しそうである

これをどうやって実現したのか? というと、SVE2の導入である。つまりNeoverse N2は初めてのArmv9.0-Aを実装したCPU IPという訳だ(Photo07)。
-

Photo07:SIMDエンジンを主体にすれば、それはSMTでは効率が悪いのは間違いない。問題は、どこまでSIMDエンジンだけで処理が片付くか次第である

Armv9.0-AとSVE2を利用することで、Neoverse N1比で1.2~1.4倍の性能向上が見込めたというのがArmの説明である(Photo08)。
-

Photo08:逆に言えば、SVE2を使わない場合でどうか? というのが非常に気になるところである。SVE2はそれなりにエリアサイズを喰うはずで、となると非SVE2の命令パイプラインは相対的にシンプルになっていると想像される

Photo09は以前のもののUpdate版であるが、実はこのからくりを見るとこの表も素直に見られなくなる。
-

Photo09:白はXeon系列、グレーがEPYC系列と想像される。SIMDをフルに使う、という条件の場合、AVX512×2のXeonやAVX2×2のEPYCも、もう少し性能が上がる(というか、Neoverse V1/N2を上回る)気がするのだが、あとはコアの数で勝負というあたりなのだろうか?

Photo10/11がこれをBreakdownしたものだが、スコアそのものはSPEC CPU 2017 rateを実施したものである。


Photo10,11:比較基準はNeoverse N1らしい


問題はこれのコンパイルオプションであるがPhoto12がその説明である。
-

Photo12:まぁこうした事をちゃんと公開してくれるあたりはまだ良心的だとは思う

ここでずるいというか、どうなのか? と思うのは、
- Neoverse N1/V1/N2:-marchに細かくアーキテクチャ指定を入れてきちんと最大限のパフォーマンスを得られる設定にしている。
- XEON/EPYC:-mcpu=native指定である。
これをやると「コンパイル時に」(つまりBenchmark用のBinaryをビルドしているマシンの状態に合わせて)最適化が行われる。なので、実際に最適な動作をしているとは思えないという事になる。最新バージョン(GCC 10.3)の場合の-marchの指定を見ていただくと判るが、本来なら
- Xeon 8268:-march=skylake-avx512
- Ice Lake System:-march=icelake-server
- EPYC 7742:-march=znver2
- EPYC 7743:-march=znver3
としたバイナリをそれぞれ生成した上で比較しないとフェアとは言えないだろう(というよりも、このスコアはどう見てもAVX2やAVX512をフルに使っているとは思えない)。まぁこのあたりは将来訂正した結果が出てくるのを待ちたいところだ。
もっとも現在はIce Lake SystemやEPYC 7743、Neoverse V1/N2などがすべて推定(Neoverseはシミュレータ上で動かした結果かもしれないが)なので、今の時点で目くじら立てても仕方ないところはある。いずれこれらのシリコンが登場したあたりで、IntelやAMDから実際のベンチマーク結果が示されるという形で評価が出てくると思う。
最後になるが、このNeoverse V1/N2とあわせてInterconnectであるCMN-700についても説明があった。主にNeoverse V1向けという形に見えるが、最大256コアのサポートと512MBのSLC、40ポートのメモリコントローラ向けI/Fという、なかなかのお化けである。これはスケールアウト方向のNeoverse N2にはちょっとオーバースペックな感もあるので、Neoverse N2では引き続きCMN-600が使われることになるかもしれない。
-

Photo13:SW controlled dynamic resource managementとは、Armv8.4-Aで追加されたMPAM(Memory System Resource Partitioning and Monitoring)に対応する機能である