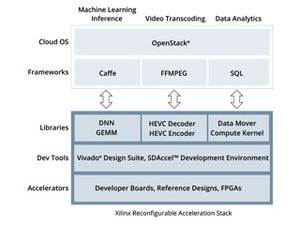
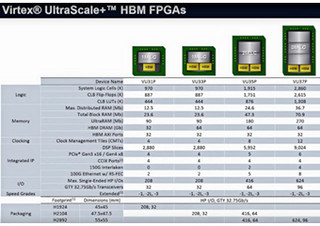
さて、従来これをFPGAでやろうとする場合、アプリケーションはOpenVXやOpenCVで記述、推論部はCaffeあたりを利用して、その下でさまざまなCNNを走らせるという形になっていた(Photo08)。この状態でも、SDSoCを活用することで、サブシステムの設計を大幅に短縮することは可能であった(Photo09)が、reVISIONを活用することで、これが劇的に低下することが期待できるとする(Photo10)。しかも性能面でも大きなメリットがある、としており、NVIDIAのJetson TX1とZynqベースの比較を行って、その性能の優位性をアピールした(Photo11)。

|

|
|
Photo08:SDSoCはある程度、C/C++で記述されたコードをVerilogに変換してくれるが、効率が必ずしも良いとはいえなかった |
Photo09:OpenCVの最適化や機械学習部分はSDSoCの範囲外なので、ユーザーが最適化を行わないといけない部分だった |

|

|
|
Photo10:これは要するにOpenCVの最適化や、主要なネットワークのFPGAのインプリメントをXilinx側で行っているので、その部分の工数が丸ごと削減できるという意味である |
Photo11:余談ながらNVIDIAもJetson TX2を3月8日にリリースしており、Jetson TX1比で2倍の性能が実現できたとしている |
この性能の差を、自働ブレーキに適用した場合、ということで示されたのがこちら(Photo12)。ただここで注記を見ていただくと判るが、Xilinxはbatch=1の環境なのに、NVIDIAではbatch=8となっている。これに関してNi氏曰く、確かにNVIDIAはbatch=8で、これだとレイテンシが大きくなるが、その一方で性能が上がらないためで、実際にNVIDIAの発表資料を見るとbatch=8の結果が多いからとの事。こちらだとレイテンシは増えるが、性能も163image/secまで改善している。一方Xilinxの場合、batch=1でもbatch=8でもレイテンシ/処理速度ともに変わらないので、batch=1の数字を使った、としている(Photo13)。

|

|
|
Photo12:時速100Km/hで走行していて前方に障害物を発見した、というシナリオであるが、そもそもNVIDIAだと衝突するようなイメージはやややりすぎな気も。要点はブレーキの開始が40ms以上早く、停止までの走行距離が33ft短いという「だけ」である |
Photo13:batchサイズを変えても性能が変わらない、というあたりがFPGAのメリットの1つではある(限度はあるが) |
またCNNを構築する上で、FPGAを利用すると性能面でのメリットが大きいもう1つの理由がこちら(Photo14)である。CPUにしてもGPUにしても、Convolutionの結果をそのまま次の処理に渡す、ということは原理的に難しいため、どうしてもメモリアクセスが多発し、これが全体の処理速度を決めることになりかねないし、レイテンシも当然増える。対してFPGAではこの必要を最小限に抑えられるので、スループットも高く、レイテンシも下げられるわけだ。

|
|
Photo14:CPU/GPUでもうまくキャッシュにヒットするような作り方をすれば、メモリアクセスそのものの頻度は削減できる。ただ複数スレッドで同時にネットワークのさまざまなConvolution処理を同時に行っている状況で、こうした最適化は非常に難しい。他方FPGAの場合、うまく分散メモリを活用することで、外部メモリのアクセスを無しあるいは最小限に抑えることが可能である |
今後の展開として、まだまだ今後どんなネットワークが登場するか判らないという状況であり、こうした場合でもFPGAであれば構成を柔軟に変えられる点がメリットであるとしている(Photo15)。また、センサそのものも、今後は機械学習を生かしたセンサフュージョンがさらに進化し、より多くの種類のセンサが利用されてゆくと同社は見込んでおり、こうしたさまざまな進化に対応しやすいのもFPGAベースのメリットだ、とする(Photo16)。

|

|
|
Photo15:今後はデータ精度が8bit未満、あるいは可変精度といった要求がでてくることもあるとし、こうしたケースではFPGAが有利であるとする |
Photo16:例えば衝突防止は、まずはRaderだが、続いて赤外線、高解像度カメラときて、将来はマルチスペクトルRFが投入されるかもしれない。こうしたセンサはデータ量がさらに増えていくため、機械学習を利用しての情報の整理が必須になる、という事だろう |
すでに同社はさまざまなEmbedded Vision向け開発キットを発表しているが(Photo17)、これらのキットの上にreVISIONを載せることでそのまま機械学習が利用可能、としている。これによって、これまで欠けていたエッジデバイス向けのソリューションが揃った(Photo18)、というのが同社のメッセージである。

|

|
|
Photo17:実際reVISIONは単に同社のFPGAがあれば動くので、既存のEmbedded Visionのハードウェアがそのまま利用できることになる |
Photo18:緑色の部分がreVISIONがカバーするエリアになる。ちなみにコンシューマ/エンターテイメント/リテール向けは、価格への要求が極めて厳しいので、そもそもXilinxのソリューションが適していない、という話であった |
ちなみに最後にちょっと補足説明を。reVISIONの場合、あらかじめbitstreamとして用意されたCNNそのものがFPGAファブリックにロードされ、さらにこれに対応したCaffeがXilinxから提供される。なので、プログラマはこのCaffe経由で呼び出しをかけるだけでよく、あとはCNNのパラメータを設定して、データを入れれば推論結果が出てくるという仕組みだ。当然どんなCNNが用意されるかが重要になってくるが、同社によればまずAlexNet、GoogLeNet、SqueezeNet、SSD、FCNなどが提供され、さらに今後もラインアップを拡充してゆく、という話であった。またCaffe以外のAPIに関しても検討中だが、「今のところCaffeが一番広く使われているので」(Ni氏)というのが、とりあえずCaffeを提供する理由だそうだ。

|
|
Photo19:今後はTensorFlowの提供なども考えている、という話であった |