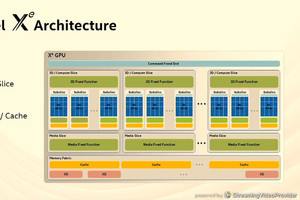
Cerebrasのウェハスケールエンジン(Wafer Scale Engine:WSE)は直径300mmのシリコンウェハをまるまる1枚を使う超巨大LSIのAIエンジンである。Hot Chips 32では、このWSEの使い方に関する考え方、そして次世代のWSEに関する話が語られた。
システムとしての利用が進むCerebrasのWSE
このチップ(?)は1.2Trillionトランジスタを集積している。NVIDIAのA100 GPUが54.2Billionトランジスタであるので、その20倍以上のトランジスタを集積しているわけである。そして、そのトランジスタを使って、WSEは18GBのオンチップメモリとAI演算に最適化した40万個のコアをチップ上に作っている。
-

CerebrasのWafer Scale Engineは1.2Trillionトランジスタと、NVIDIAのA100 GPUの20倍以上のトランジスタを集積している (このレポートのすべての図は、Hot Chips 32におけるCerebrasのSean Lie氏の発表スライドをキャプチャしたものである)

CerebrasはすでにWSEチップを搭載したCS-1システムを販売している。CS-1は1チップのシステムであるが、Cerebrasはクラスタシステム級の性能を持っていると言っている。すでにアルゴンヌ国立研究所で使用されており、ピッツバーグスパコンセンターからも2台のCS-1を受注しているほか、一般の企業にも導入されているようであるが、それらの顧客は明らかにされていない。
-

CS-1はクラスタシステム級のディープラーニング性能を発揮する

WSEのプログラミング方法
WSEのコアはマシンラーニングに最適化された拡張命令を持ち、データフローアーキテクチャで入力が入ってきた時しか演算を行わないようになっている。メモリはコアごとに分散されており、メモリとロジックが混然一体となった造りになっている。そして、高バンド幅、低レーテンシのネットワークを持ち、ユーザの指定したトポロジの接続を行うことができる。
-

CerebrasのコアはFMACのデータパスとレジスタ、SRAMメモリを持ち、ファブリックにつながっている。演算器はML演算に最適化された拡張がなされている

WSEのプログラミングは、TensorFlow、PyTorchやCaféなどのフレームワークで記述されたニューラルネットを、まず、LAIRと呼ぶ中間表現に変換し、それをカーネルグラフとのマッチングを調べてWSEでの実行方法を決定する。そして、各部の実行プランをリンクして、全体の実行モジュールを作ってWSEで実行するという流れになる。
-

CerebrasのWSEはKernel Graphと呼ぶグラフを実行する。そのため、まず、フレームワークで記述されたニューラルネットをLAIR表現に変換し、それをKernel Graphに変換する。Cerebrasのグラフコンパイラは、DNNグラフを自動的にコンパイルしてくれる

Cerebrasのコンパイラはフレームワークの演算とグラフカーネルの一致を調べて、フレームワークの記述をカーネルに変換する。カーネルとしては汎用の自動生成したものと、人手で最適化したカーネルが用意されている。
-

Cerebrasのコンパイラはフレームワークの記述とカーネルのライブラリとの一致を調べ、一致していればカーネル表現に置き換える。一致するものが無い場合は、自動生成したカーネルを使うものと思われる

次の図はコンパイラの最適化の例を示すもので、1つの層の処理を3×3から、12×12までの面積と性能の異なる5種の候補で、自動的にトレードオフを検討した例である。
-

ニューラルネットの1つの層で面積を3×3から12×12まで自動的に振って、面積、性能のトレードオフを検討した例

そして、それぞれの層をWSE上のコアに配置、配線して作り、カーネルを実現する。このプロセスは、LSIの配置配線と同様のプロセスを実行している。
-

カーネルの面積、性能のトレードオフが決まると、WSE上の配置や配線が行なわれる