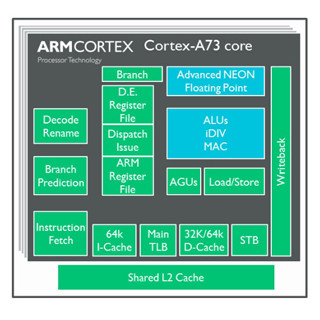
次が「Clause」の話である。実の所「Clause Execution」という概念は結構昔からあるが、ハードウェアの実装という形では余り記憶がない。そもそもどういう概念か? という事でまず通常の命令実行手順を紹介したのがこちら(Photo20)。これに対してClause Executionでは、こんな形(Photo19)に複数の命令を固まり(Clause)にして、そのClauseの単位で実行を行う(Photo20)事でオーバーヘッドを削減しよう、というものだ。

|

|
|
Photo18:とりあえずアウト・オブ・オーダーとかの話は置いておきたい。イン・オーダーの場合、命令を実行するごとに次の命令をどうするか決めるという仕組みである。もちろんこれだと時間が掛かって仕方ないのでパイプラインでオーバーヘッドを遮蔽する訳だ |
Photo19:オーバーヘッドってなに? という具体例はこの後 |
この方式の実装例を見かけないのは、実は性能改善にはほとんど影響がないためだ。例えばPhoto20だとあたかも5つのClauseが同時に実行できるように見えるかも知れないが、実際はClause内の1個の命令処理の時間は変わらないし、5つのClauseを同時に実行するためには実行ユニットも5並列が必要になるから、全然意味が無い。そもそもオーバーヘッドの部分はパイプラインで遮蔽されているから、普通に実装する限りは性能はまったく同じである。では、何に効果があるか? といえば省電力である。オーバーヘッドがあるということはパイプラインであっても、そのオーバーヘッド分を処理するエネルギーは命令ごとに消費される。ところがClause単位で固まりにすれば、オーバーヘッドの総数が減るから、その分消費電力が削減できるという訳だ。

|
|
Photo20:Clauseという処理単位を設けて、この中でのBack-to-Backの処理の互換性を保障することで、安心して命令を継続できるとする |
実際の例で見てみたい。ここでは
ADD R2, R0, R1 (R0+R1→R2)
ADD R4, R2, R3 (R2+R3→R4)
ADD R0, R4, R5 (R4+R5→R5)
という3つの加算を行うケースである。これを通常の方式で行ったのがPhoto21で、6回のレジスタファイル読み出しと3回の書き込みが発生する。ところが、この場合2回目と3回目の加算はそれぞれ1回目と2回目の結果を利用している。そこで中間領域(T:Temporal Register)を用意して、ここに演算結果を一時格納することで、レジスタファイルの読み出しは4回、書き込みは1回になる(Photo22)。これで性能が上がるわけではないが、消費電力は明確に削減できるし、利用するレジスタファイルの数も減るから最適化が容易になる。

|

|
|
Photo21:レジスタファイルは高速(基本0サイクルでのアクセスが可能)な分、消費電力も多いから、使わずに済むなら使わないほうが消費電力的には好ましい |
Photo22:Clauseの内部では利用しているレジスタとか処理される命令は異なるが、3命令目の終了後はPhoto21のケースと同じである。この3命令を連続して行う(これはClauseにより強制的に行われる)ことで、プログラマから見れば通常の実行と変わらない結果が保証される |
ただ、Clauseベースにすると、スケジューリングに関しては別の配慮が必要になる。例えば1つ目のClauseでテクスチャを操作して、その結果を3つ目のClauseで使う(Photo23)なんてケースだ。この場合、テクスチャユニットの処理結果が確定するまで3つ目のClauseはホールドされるが、そこで間が空いてしまう場合、別のQuadのClauseが埋める形になる。考え方としてはDeterministic Multi-Threadingと同じ方式だ。なので、実際には複数のClauseが交互に実行されるような形になる(Photo25)。このClauseの実際のサンプルはこんな形(Photo26)である。あとはコンパイラがどれだけ上手くClauseを構成できるか、で効率が変わってくることになるだろう。

|

|
|
Photo23:別にテクスチャだけではなく、Load/Storeユニット待ちということもありえるだろう |
Photo24:ある意味スレッディングと同じなのだが、スレッディングよりももう少し大きなClause単位での管理、というのがポイントとなる |

|

|
|
Photo25:実際にはもっとQuadが多くなる訳で、恐らくRound Robin的な形で複数のQuadを廻すものと思われる |
Photo26:t0/t1がテンポラルレジスタとなる。いくつテンポラルレジスタを利用できるのかは現状明確では無い |
話をExecution Engineに戻すと、基本的には32bitのエンジンで、8/16bitも扱える仕組みになっている(Photo27)。また、Addと並行してSpecial Function Unitも搭載されている。これと組み合わされるレジスタファイルは、ある意味当然ではあるがQuad単位ではなくスレッド単位で用意されている(Photo29)。このExecution Engineと組み合わされる3種類のユニットも、それぞれMidgardから色々変更がなされているが、主眼はいかに省電力化するか、というあたりに置かれている(Photo30)。

|

|
|
Photo27:ここには無いが64bitのフロートも扱えるそうで、その場合は性能が1/2になるとの事。2サイクル使って処理を行うものと思われる |
Photo28:どうやってサイズを削減しているかというと、文面から見る限り一部の機能はハードウェアからコンパイラ側に移しているように思える |

|

|
|
Photo29:レジスタの量はMidgardと比べて2倍になった |
Photo30:Indexの話はPhoto32に |
これはメモリアクセスに関しても同じである。まずテクスチャに関しては、Midgardと同様のタイル型の格納方法を取るが、タイルの幅をより小さく分割することで最適化を図っているとする(Photo31)。またシェーダーではIndexベースのアクセスとすることで、必要とするメモリアクセスの帯域そのものを削減したとしている(Photo32)。

|

|
|
Photo31:青白のタイルが従来のMidgardのもので、点線の領域がBifrostで利用する格納エリアとの事。ところで一番左には、小さな白いTriangleが青い領域にあるのだが、それが消えてるのがMicro-triangle eliminationなのであろうか? |
Photo32:当然必要な帯域が少ない分、若干といえど性能が上がる可能性がある(基本はクロスバだから帯域的にはMidgardでも足りているはずだが、当然調停の必要性が減る分オーバーヘッドの若干の改善になる)し、省電力には当然効果がある |
ちなみに冒頭でも述べたが、Mali-G71は完全なキャッシュコヒーレンシを実現している。このため、Mali-G71は最大4本のLinkでCCI-550と接続される形になる(Photo33)。このL2を含むMali-G71コア全体でもTrustZoneを当然サポートしている。

|

|
|
Photo33:これはつまりL2のクラスタが最大4つまでサポートされる、という意味でもある |
Photo34:これはまぁ当然だろう |
ということで、Mali-G71の詳細をご紹介した。全体としては、Cortex-A73と同じく性能を改善しつつも、省電力への配慮の方が非常に多い実装となっている。絶対性能もさることながら、性能/消費電力比を大幅に引き上げたのがMali-G71の特徴ということになるだろう。