AMDのMagny-CoursとIntelのNehalem EX
2009年8月23日から25日にかけて米国スタンフォード大学のメモリアルオーディトリアムでHot Chips 21が開催された。なお、初日の8月23日はチュートリアルで、午前はシステムインターコネクトと題して、AMDのHyperTransport 3とIntelのQPI、PCI Express(PCIe)3.0についての説明が行われた。そして、午後はGPUなどを使う新しい計算処理用言語であるOpenCLが説明された。

|
|
Hot Chips 21の会場風景 |
今回のHot Chipsの目玉は、 AMDの12コアMagny-Cours とIntelの8コアのNehalem EXというサーバ向けのx86プロセサの発表と、秘密に包まれていたIBMのPOWER7の発表である。ということで、x86サーバプロセサの発表は24日の開会直後のServer Systems I、POWER7の発表は、25日の終了直前のServer Systems IIで発表された。このように目玉の発表を最初に持ってきて、初日の朝から遅れず出席させ、また、早く帰ってしまわないように、もう一つの目玉を最後に持ってくるのは学会運営の常套手段である。
6コアチップを2つ搭載したMagny-Cours
AMDのMagny-Cours(マニクールという人と、英語風にマグニークーアスと発音する人があり、発表者のConway氏は後者)であるが、12コアといっても、シリコンチップはIstanbulと同じで、6コアのチップを1つのパッケージに2個搭載する形の12コアCPUである。Istanbulについてはすでにある程度発表されているので、今回の発表はプロセサコアには触れず、チップ間を繋ぐHyperTransport 3とIstanbulから採用されたHT Assistという機能を中心とした発表であった。なお、Magny-CoursのチップはIstanbulと同じチップであるが、HyperTransportのスピードが4.8GT/sから6.4GT/s、DDR3メモリのスピードが1066から1333へと向上している。

|
|
Magny-Coursについて発表するAMDのPat Conway氏 |
Istanbulチップは6個のGreyhound+コアと6MBの3次キャッシュを集積し、x16のHypertransport 3(HT3)を4本持っている。なお、このHT3はx8を2本、x4を4本というように分割して使用することもできる。

|
|
Magny-Coursのチップ写真(1チップ分)(出所:Hot Chips 21 配布資料) |
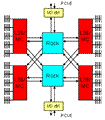
Magny-Coursは、このチップを2個同一パッケージに入れ、パッケージ内の配線でx16とx8それぞれ1本を使用して2つのチップを相互接続し、外部接続のポートとしてそれぞれのチップからはキャッシュコヒーレンシをサポートするx16とx8のcHT3を各1本出している。さらに一方のチップからはI/O接続用にキャッシュコヒーレンシをサポートしないx16のncHT3を出し、他方のチップではこのx16ポートは未使用となっている。

|
|
Magny-Coursの2チップの接続(この図の右下のx16 cHTはncHTの誤りで発表スライドでは修正されていた)(出所:Hot Chips 21 配布資料) |
そして、次のような2ソケット、4ソケットの場合の接続図が示された。4ソケットの場合でも他のどのチップにも2ホップで到達でき、平均距離は1.25である。また、各チップから2本のDDR3 1333が出ており、4ソケット全体では170.4GB/sという大きなメモリバンド幅を持つ。

|
|
2ソケットと4ソケットシステムの接続(出所:Hot Chips 21 配布資料) |
AMDのキャッシュコヒーレンシ制御は、データの要求元のノード(チップ)がそのアドレスのメモリを持つノード(ホームノード)にアクセス要求を送り、ホームノードが全ノードにプローブを送ってそのデータが他のノードのキャッシュに格納されているかどうかを問い合わせる。そして、各ノードのプローブ応答(とデータを持っているノードは、そのデータ)を要求元のノードに送る。そして、要求元のノードがすべてのプローブ応答と、データを持っているノードから送られるデータを受け取るとメモリアクセスが終わるという手順となる。
しかし、どのノードもそのアドレスのデータを持っていない場合は、全ノードをプローブするのは無駄であり、HT3のバンド幅を無駄に消費し、消費電力も増えてしまう。これに対して、Magny-Cours(Istanbulも同じ)のHT Assistでは、各ノードが管理するメモリのデータが他のノードのキャッシュに格納されているかどうかを示す情報を持ち、どのノードもデータを持っていない場合は、ホームノードは他のノードに対するプローブは行わず、自分のメモリからデータを読み、直ちに要求元のノードに送り返すという動作を行う。このような無駄なプローブ動作を省くことにより、メモリアクセス時間も短縮できる。