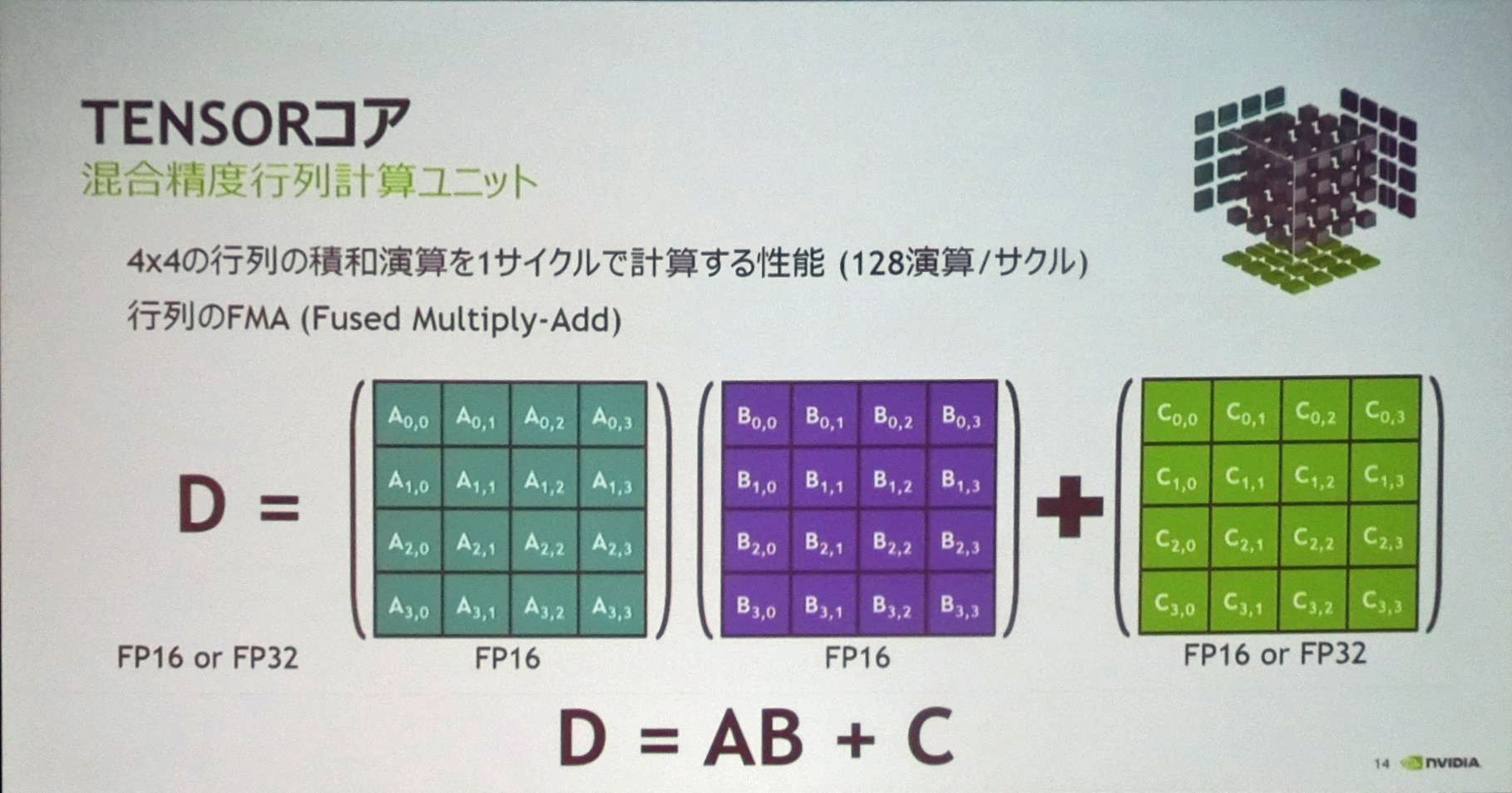
Voltaで新たに追加されたTensorコア
V100で新設されたTensorコアであるが、4行4列の行列AとBを掛け、それを行列Cに足しこむという演算を行う。行列AとBはFP16形式、行列Cと演算結果の行列DはFP16あるいはFP32形式である。
-
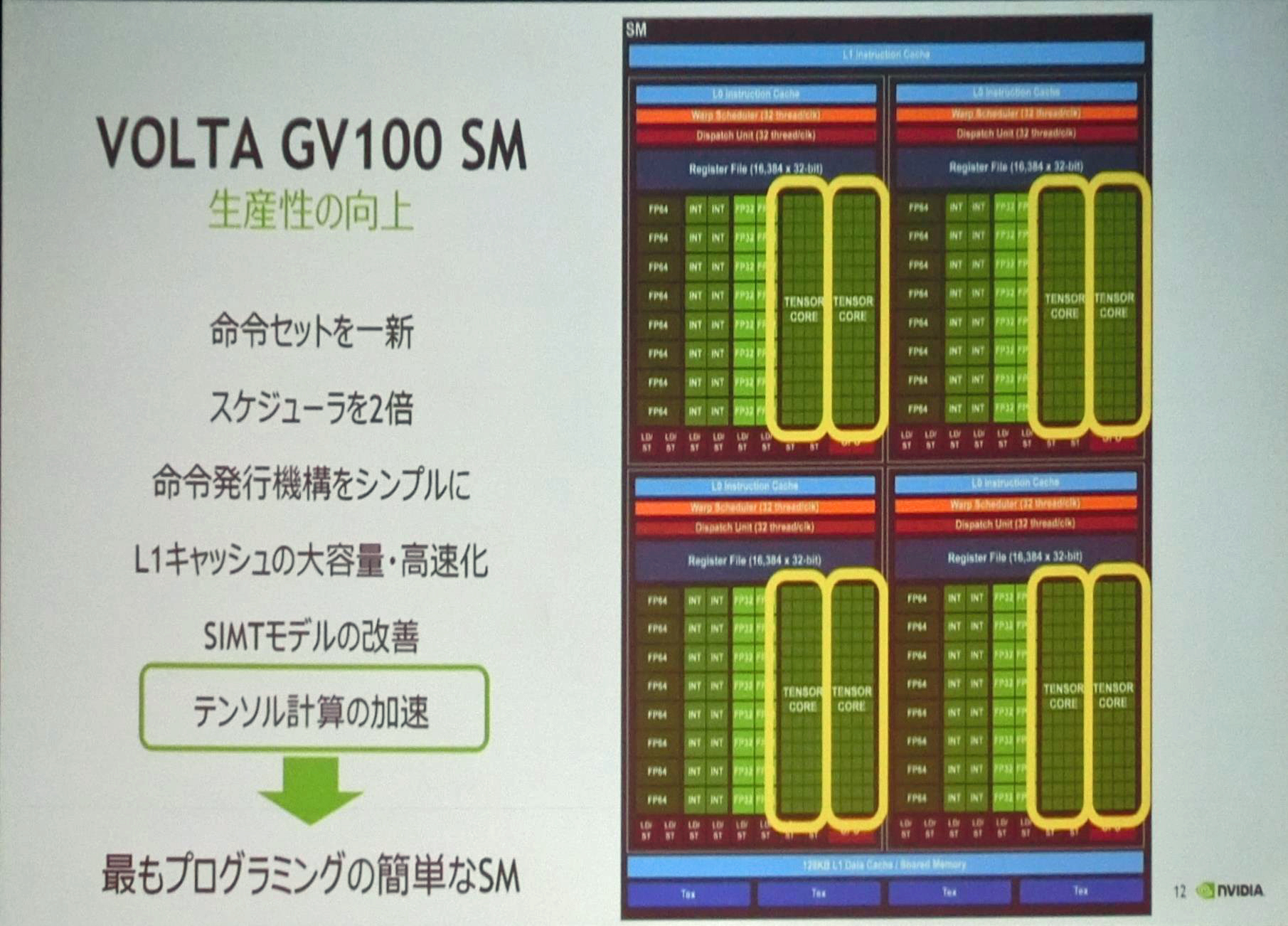
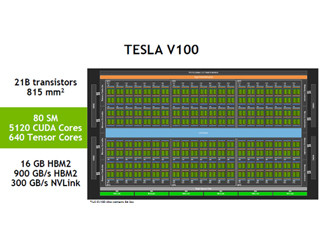
V100 GPUのSMは、Tensorコアの追加によりディープラーニング性能を大幅に引き上げ、SIMTモデルの改良などプログラムの生産性を向上させるため、命令セットを一新した

ディープラーニングの計算では、A、Bの積をFP16で計算しても、結果を累積するCの計算をFP32で行えば、必要な精度は確保できるということから、Tensorコアは乗算はFP16、加算はFP32という混合精度の演算を行っている。
Tensorコアは、全体で128演算を必要とするこの計算を1サイクルで実行できる。このため、V100 GPUは、非常に高いディープラーニング性能を持っている。
-
V100 GPUでは、行列の積和演算を行うTensorコアを追加した

Tensor演算を詳しく書くと、A、B入力は2つの16bit精度の数であるが、掛け算の出力はまるめを行わず32bitの精度で出力し、それにFP32のCを加算している。このため、FP16の積をFP16にして出力する普通のFP16の積演算よりも、計算誤差が小さい。
そして、FP16出力が必要な場合は、FP32の結果をFP16に切り詰めることもできる。
-

TensorコアはFP16の掛け算結果を32bit精度で出力し、それにFP32の入力を加える。このため、FP16だけの計算と比べて計算誤差が小さい

通常は、NVIDIAのGPUは32スレッドをまとめて1つのワープとして同じ命令を実行するのであるが、次の図に示すように、Tensorコアで演算を行うときは32スレッド分のハードウェアを全部使って、Tensorコア命令を実行する。
そのため、Tensorコア命令を実行する前に、32スレッド全部が同期した状態とすることが必要である。そして、Tensorコア命令の実行中は各スレッドはTensor演算を分担して実行し、最後に全スレッドの同期を行ってSIMTのワープの実行に戻るという動作になる。
注意深い読者は気が付かれたかも知れないが、この図では16×16の行列の積和演算と書かれており、前の図の4×4の行列の積和演算という説明と食い違っている。
実は、VoltaのTensor演算は16×16の行列の演算を行うように作られており、前に掲げたTensor演算の説明の図は、1枚のPowerPointに収めるために、単純な絵を作ったようである。
-
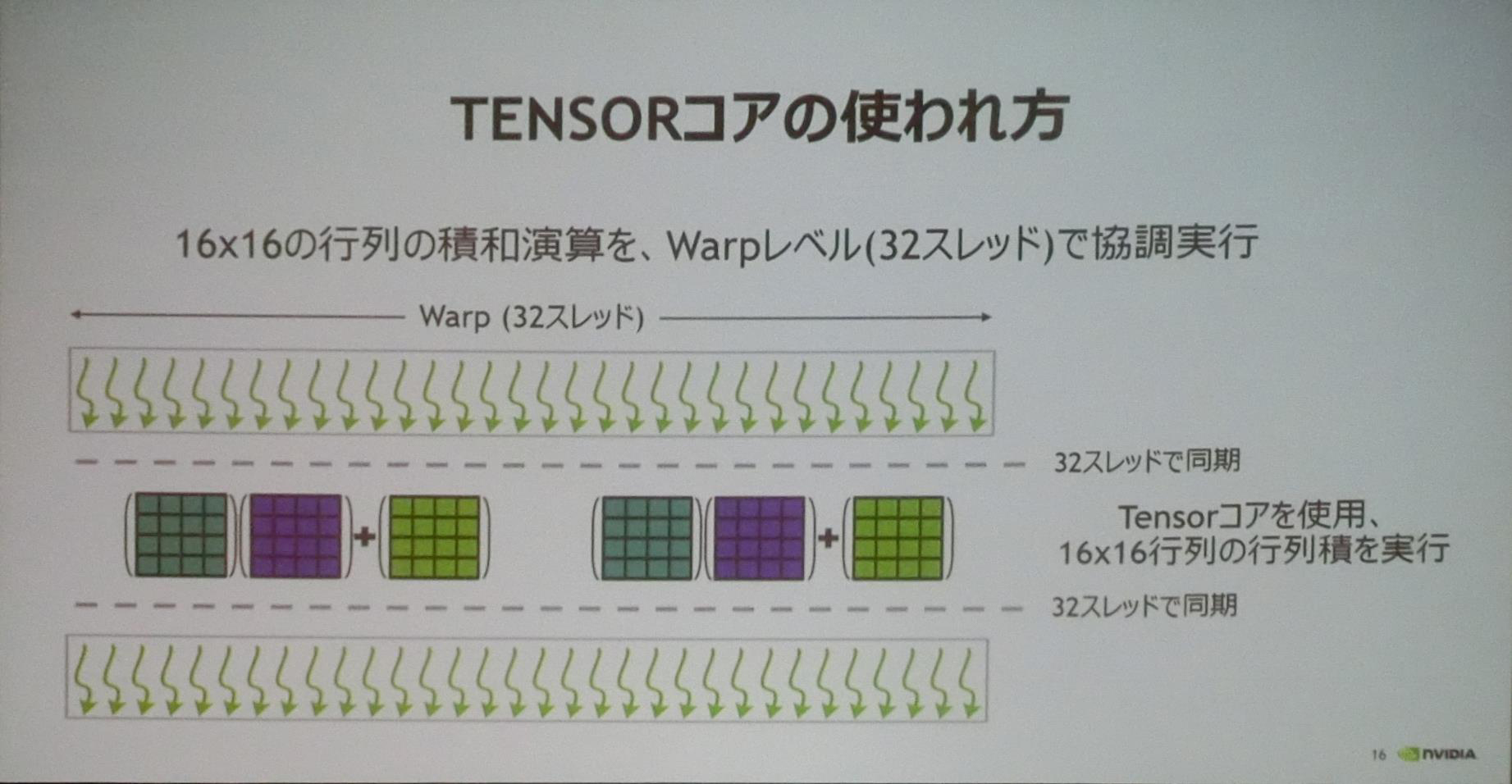
Tensorコアの命令の実行には32スレッド全部のハードウェアを使う。このため、Tensorコア命令の実行の前後には32スレッド全部の同期をとる必要がある

Tensorコアはどうなっているのか
前に示した性能・諸元の一覧では、FP32の演算性能は15.6TFlops、TensorコアのFP16性能は125TFlopsと書かれている。つまり、演算精度の違いを無視すると、Tensorコアは、FP32演算ユニットの8倍の性能をもっている。
SMあたりのFP32演算器の数は64個と書かれているので、Tensorコアはその8倍の512個の混合精度の演算器を持っていると考えられる。そして、SMあたりのTensorコア数は8個であるので、1個のTensorコアは64個の混合精度の積和演算器を持っていることになる。
これでどのように16×16の行列の積を計算するのであろうか? それについてNVIDIAからの情報は無いので、筆者独自に推理をしてみる。
Tensorコアあたりの演算器の数は64個であるので、16×16の行列の積を1サイクルで計算することはできない。しかし、8×8の行列の積なら1サイクルで計算できる。また、8×8の行列は64要素で、各要素がFP16の場合は、32スレッド分のレジスタの1エントリに格納できる。
16×16の行列を4つのレジスタから同時に読み出そうとするとレジスタファイルの読み出しポートが多数必要になり、チップ面積も増えてしまうが、8×8の行列なら普通の演算と同じように1つの読み出しポートで読み出すことができる。
次の式のA、Bはそれぞれ8×8の部分行列である。

この式に見られるように、元の16×16の行列をA11~A22の8×8の部分行列に分解してやると、式の右辺のように、8回の部分行列の積の和で16×16の行列の積を計算することができる。
1/4SMには2つのTensorコアがあるので、これらを並列に使うと、4サイクルで16×16の行列の積を計算できることになる。また、8×8の行列の全要素が1つの(32スレッド分の)レジスタに収まっているので、これをrow_majorで読み出すのか、column_majorで読み出すのかは、配線とマルチプレクサで切り替えることができ、行列積の計算には都合が良い。
これは筆者の推測であるが、おそらく、Tensorコアはこのように作られていると思われる。
Tensorコアの使い方
次の図の右側のCUDA C++の記述は基本的なTensorコアの使い方を説明したもので、wmma::fragmentで始まる3行は16×16の行列A、B、Cを宣言するものである。
その次のwmma::load_matrixで始まる2つの行は行列AとBをロードするもので、メモリから256個のFP16 の行列要素がレジスタファイルに読み込まれる。このロードでは連続する4個のレジスタが使われ、2FP16×4レジスタ×32スレッドで256個のFP16要素を格納する。
そして、wmma::fill_fragmentで始まる命令で行列Cをゼロでクリアし、wmma::mma_syncで始まる命令でA×B+Cを計算してCに格納するTensor演算を行う。この命令は結果を別の変数Dに格納することもできるが、この例では、結果はCに上書きしている。そして、wmma::store_matrix_syncで始まる命令でメモリ領域Dに格納している。
Store命令では3つ目のパラメタとして16が指定されているが、これはストライドというパラメタで、16を指定すると、(row_majorの場合)行の間隔が16要素であることを示す。大きな行列から部分行列を切り出して処理をする場合は、行の長さに合わせてストライドを指定すると便利である。また、wmma::row_majorと指定されているが、loadやstoreでは行方向のインデックスが先に変わるrow_majorの配列か列方向が先に変わるcolumn_majorの配列かを指定することができる。
このTensorコアのハードウェアの上にVolta向けに最適化されたcuBLAS、cuDNNやTensorRTといったライブラリが載り、さらにその上に、MXNETやTensorFlowなどのディープラーニング用のフレームワークが載っており、通常は、これらのV100 GPU用に最適化されたフレームワークを使えばTensorコアを利用することができる。
-

V100 GPUハードウェアの上にはcuBLAS、cuDNN、TensorRTと言った最適化されたライブラリがあり、その上に各種のディープラーニング用のフレームワークがある。これらのフレームワークを使えば、自動的にTensorコアを使うことができるが、右側のようにCUDA C++レベルでTensorコアを直接プログラムすることもできる

なお、Tensor演算のすべてのオペランドがレジスタファイルに入っている場合は125TFlops(FP16)の性能が出せるが、少なくともA入力はメモリから読んでくる必要があるというような使い方が一般的である。
(次回は2月8日に掲載します)