|
|
Hot Chips 29でVolta GPUを発表するNVIDIAのJack Choquette氏 |
Hot Chips 29では、AMDのVegaに続いて、NVIDIAのVoltaが発表された。Voltaは、4月のNVIDIA主催のGTC(GPU Technology Conference)で、Jensen Huang CEOが基調講演の中で発表したが、主要な学会での詳しい発表は今回が初めてである。
Voltaチップは、815mm2に210億トランジスタを集積している。光による露光では最高の分解能であるArF液浸スキャナの露光面積は26mm×33mmであり、851mm2より大きいチップは分割しなければ作れない。26mm×33mm=858mm2なので、815mm2というのは、まだ余裕があると思うかもしれないが、X、Yそれぞれのサイズの制限があるので、実際にはこれ以上大きいチップは作れない露光限界という巨大チップである。また、AMDのVega10 GPUは486mm2であるので、その1.68倍という巨大さである。
半導体チップの値段は1枚の直径300mmのシリコンウェハから何個の良品がとれるかに依存する。したがって、チップ面積に逆比例してウェハ上に作れるチップの数が減少して製造コストが上がる。これに加えて、製造欠陥の密度×面積の指数関数で良品率が下がって行くので、さらにコストは上がる。
そのためVoltaチップの製造コストはVegaチップの数倍以上高いはずである。また、GPUチップとHBM2メモリを搭載するシリコンインタポーザもサイズが大きくなり、シリコンインタポーザのコストも上がる。
さらに、VegaはHBM2を2個使っているが、VoltaはHBM2を4個使っており、その分、コストが上がっている。
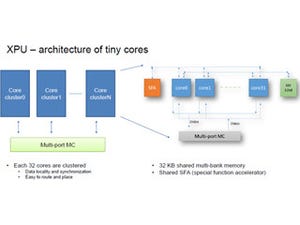
次の図は、Voltaチップ(正式名称はTesla V100)のブロックダイヤグラムであり、NVIDIAがSM(Streaming Multiprocessor)と呼ぶユニットが84個描かれている。この内の4個は不良SM救済のためのスペアであり、製品としては80SMが使用される。
各SMには64個のCUDAコア(FP32の積和演算を実行する)が含まれているので、チップ全体では5120CUDAコアということになる。また、Voltaでは、新たにTensorコアという行列同士の掛け算を効率よく実行するコアが、各SMに8個、チップ全体では640個存在する。
GPUのデバイスメモリは現在のPascal GPUと同様にHBM2を4個使っているが、メモリ容量は16GBに増え、メモリバンド幅も900GB/sに向上している。さらに、GPU同士、あるいはGPU-CPUを接続するNVLinkは、片方向25GB/sのリンクを6本に増強され、CPUや他のVoltaチップとの合計の接続バンド幅は300GB/sに増加している。

|
|
NVIDIAの最強GPU「Volta V100チップ」の概要 (このレポートの図は、特に断ったものを除き、Hot Chips 29におけるNVIDIAのChoquette氏の発表資料のコピーである) |
Volta V100チップと現在のPascal P100チップの性能を比較したのが、次の表である。
ディープラーニング(Deep Learning)の学習(Training)は、P100ではFP32で行うことになるので、その演算性能は10TFlopsであるが、V100ではTensor Coreが新設されており、これを使えば、120TFlopsの性能が得られ、P100と比べて12倍に性能が向上する。ディープラーニングの推論(Inferencing)では、P100では半精度(FP16)を使用すれば21TFlopsになるが、V100ではTensor Coreを使えば120TFlopsで、6倍の性能である。
V100の科学技術計算の単精度(FP32)、倍精度(FP64)性能は、P100の1.5倍のそれぞれ15TFlops、7.5TFlopsとなっている。このように、HPC性能は1.5倍であるが、ディープラーニング性能は6倍~12倍となっており、Voltaがディープラーニングに狙いを定めているのは明らかである。
HBM2のメモリバンド幅はP100の720GB/sからV100では900GB/sに向上している。なお、GoogleのTPU v2もHBM2を使っているが、600GB/sの性能しか出ていない。SamsungもSK HynixもHBM2のメモリバンド幅は256GB/sと言っているが、実際の使用状態でこの値を実現するのは難しいようである。
第2世代のNVLink(以下、NVLink IIと書く)のバンド幅は160GB/sから300GB/sと1.9倍に向上している。これはリンクのスピードが20Gbit/sから25Gbit/sに向上したのと、1チップから出ているリンク本数が4本から6本に増加したことの合わせ技である。
また、L1キャッシュの容量が1.3MBから10MBに、L2キャッシュが4MBから6MBに増加している。
半導体プロセスとしては、P100が16nm FinFET+であるのに対して、V100は12nm FFNプロセスで作られており、単純にはプロセスルールのシュリンク(12/16)2の面積に縮小できる計算であるが、チップサイズは610mm2から815mm2に増加している。つまり、チップの物量は2.37倍に増えているという計算になる。ただし、チップのトランジスタ数は153億から211億と1.38倍にしか増えておらず、12nmのプロセスへとシュリンクされたのであるが、トランジスタ数は1.38倍でトランジスタ密度はほどんど増加していない。
これらの数字から見ると、NVIDIAはAMDなどとの価格競争は眼中になく、大幅なコストアップをものともせず、最強のGPUを作ったという感じである。

|
|
NVIDIAのP100 GPUとV100 GPUの性能の比較 |