



-

デモブースで展示されていたGaudi2

インテルは大規模なAI開発のために専用プロセッサーを用意
インテルは2024年6月6日、東京ミッドタウンホールにてインテル AI Summit Japanを開催した。近年、大きな盛り上がりを見せているAIをテーマとしているところから、午前中の基調講演は立ち見(その後、サテライト会場を急遽オープン)する人がいるほどの盛況ぶりであった。
この記事では午後の分科会セッションのうち「DC-3:インテル Gaudi AIアクセラレーターを活用した生成AI/LLM開発」の内容と会場でのGaudiアクセラレーターのデモコーナーの様子を紹介する。
分科会はインテル インダストリー事業本部 サービスプロバイダー事業統括部 シニア・ソリューション・アーキテクトの小佐原大輔氏が説明。前半がGaudiシリーズ製品全体の紹介で、後半はGaudiアクセラレーター向けのアプリ開発に関して解説を行った。
-

インテル インダストリー事業本部 サービスプロバイダー事業統括部 シニア・ソリューション・アーキテクト 小佐原大輔氏

Gaudi2が見せたコスパの良さとその実力
インテルはさまざまな領域に向けた広範なプロセッサーを展開している。その中でも、AI向けという観点では昨年に発表されたコンシューマー向け、開発コードMeteor Lakeこと第一世代のCore Ultraプロセッサーにも、AI処理に特化した専用プロセッサーのNPUが搭載された。また、サーバー用の汎用プロセッサーであるXeonにおいてもAI推論に向けて低精度数値表現やAMXアクセラレーターを内蔵している。
数あるプロセッサーの中で、近年のAIブームを下支えしたのがGPUであることは間違いない。現在のスパコンの多くはGPU等のアクセラレーターを使っているのが一般的だ。インテルは長らくコンシューマー製品向けにGPUを内蔵した製品を投入しているが、ここ数年は大きな性能向上を見せている。コンシューマー向けとしては22年ぶりとなるディスクリート製品Arcシリーズを販売しているほか、同じチップを使用したデータセンター向けのData Center GPU フレックスシリーズを販売している。
AIの需要が高まる中、さらに高度なAI専用製品が求められるのは必然だ。インテルはこの分野にAI専用アクセラレーターを投入しており、これがGaudiシリーズである。現在販売中のGaudi2は2022年の「Intel Vision 2022」で発表した。
Intel Vision 2022では現在の生成AI大ブームのきっかけとなったChatGPT発表前という事もあり画像生成デモしか行われていなかったが、「少ない文字列で画像候補をこれだけ出すのはすごい」と筆者は感じていた。
Gaudiのターゲットとなるのは深層学習(DL)や大規模言語モデル(LLM)となっており、逆にHPCの利用に関してはGPUの方にメリットがある。
小佐原氏はGaudiの特徴としてAI専用設計により競合よりも安価に得られる事、シングルボードだけでなく4096ノードまで確立された拡張性がある事、最小限のコード変更で既存のアプリケーションが利用できることの三点を挙げた。
-
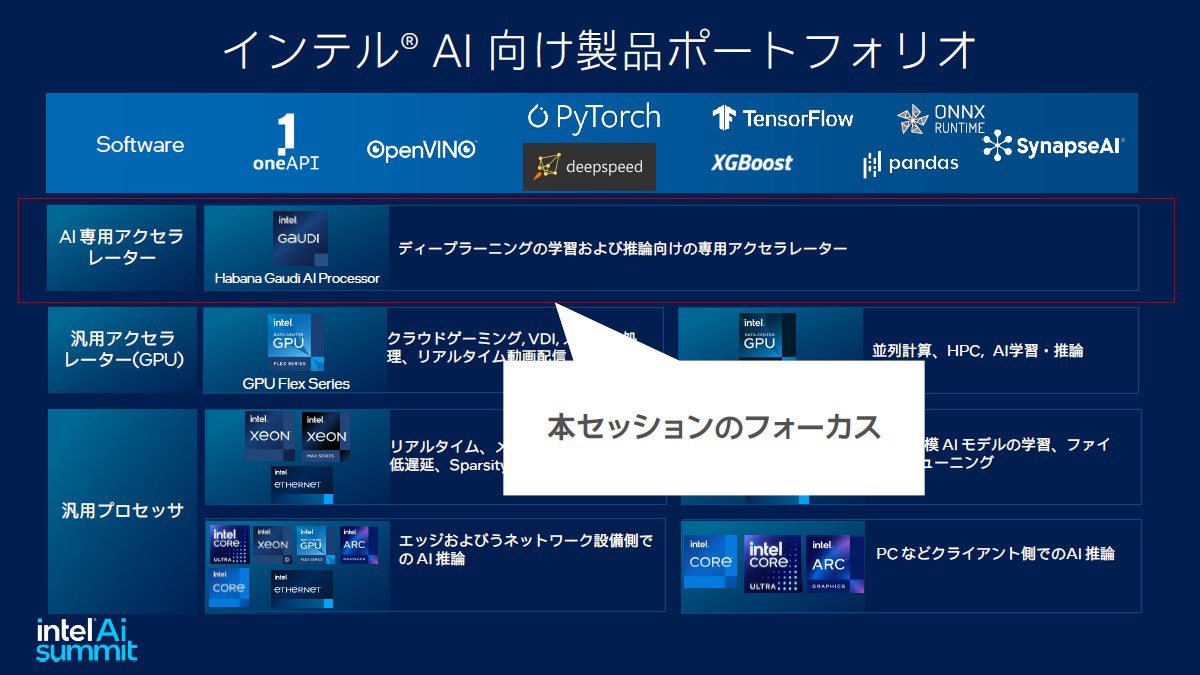
インテルは多種多様なプロセッサー・アクセラレーターを販売しているが、今回のターゲットはAI演算専用に設計されたプロセッサーを扱う

-
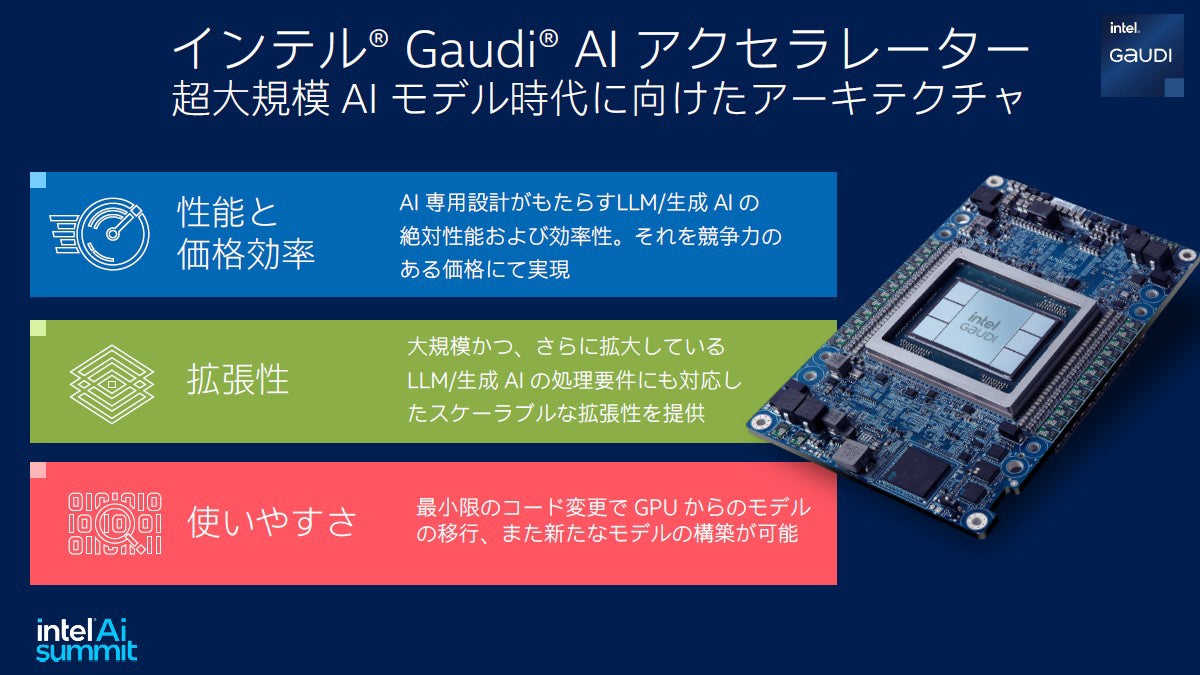
GaudiシリーズはAI専用設計ゆえの性能と価格効率とスケールアウトできる拡張性、そして既存のAIアプリケーションの一部を書き換えることで実行できる使いやすさが特徴だ

現在販売中のGaudi2は24のTensorコアと2つの行列演算エンジンを備えているほか、96GBのHBMメモリと48MBのSRAMによって大きなデータに高い帯域幅でアクセスできる。さらに大規模構成に対応するため業界標準の100Gビットイーサネットを24系統搭載し、外部バスも業界標準のPCIe Gen4 16レーンとなっている。小佐原氏は「(イーサネットやPCIeといった)業界標準のI/Fを使用することで使い慣れた機器メーカーや価格のこなれた製品を使うことができる」とシステム全体のコスト削減につながると説明した。
-
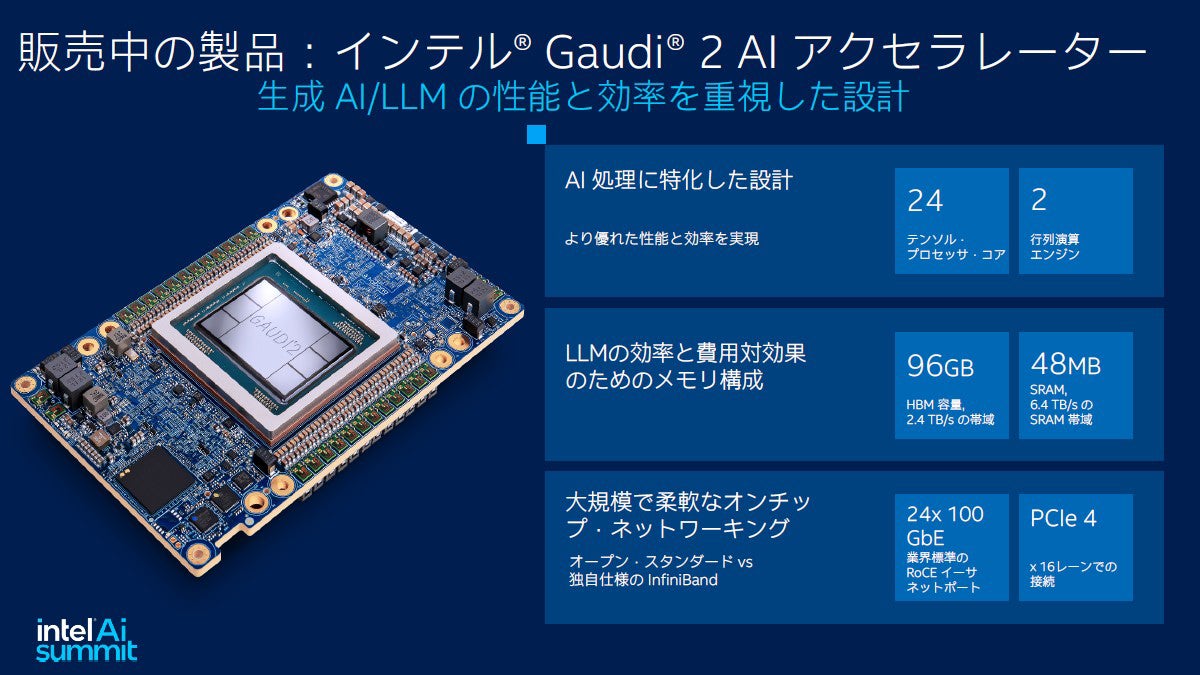
現在販売中の製品がGaudi2。Tensorプロセッサーを24、行列演算エンジンを2個内蔵しており、生成AIで不可欠な高速メモリもライバル製品よりも多く搭載している。また、大規模構成に不可欠なネットワークは業界スタンダードな100GbEを24備える

コストに関してはDatabricksの評価結果を引用して、現在の最大ライバルであるNVIDIA製品と比較していた。推論性能はNVIDIA H100と競合する性能を持ちつつ、AWS上の価格で比較すれば約半分のコストになるという。学習能力に関してはH100比で1.47倍のコスパと表現していた。
-
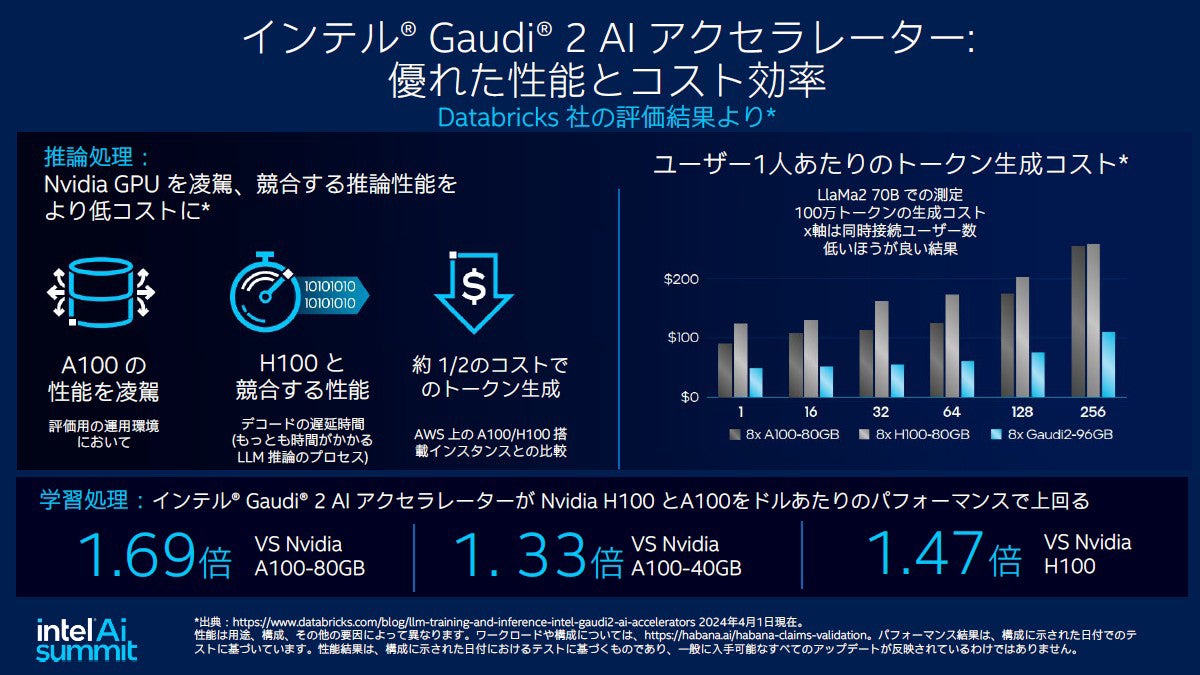
業界最大のライバルであるNVIDIA製品との比較。性能が高く価格が低いという事で高コスパが魅力だ

大規模化に関してはGaudi2が持つ24ポートのイーサネットを使用することでノード内部のアクセラレーター間接続もノード間のスケールアウト接続も同一のファブリックが使用できるほか、業界標準の100GbEを使っているため業界標準のRoCE対応イーサネットスイッチで利用できる。16台のGaudi2を1ノードとして構成し、これをリーフスイッチとスパインスイッチで接続することで512ノード4096個の構成まで実際に(デベロッパークラウドにて)構築できている。スケールアップ時の効率に関しては256枚と348枚でMLParfを使用した比較で、スケーリング効率が95%と高いことを示した。
-
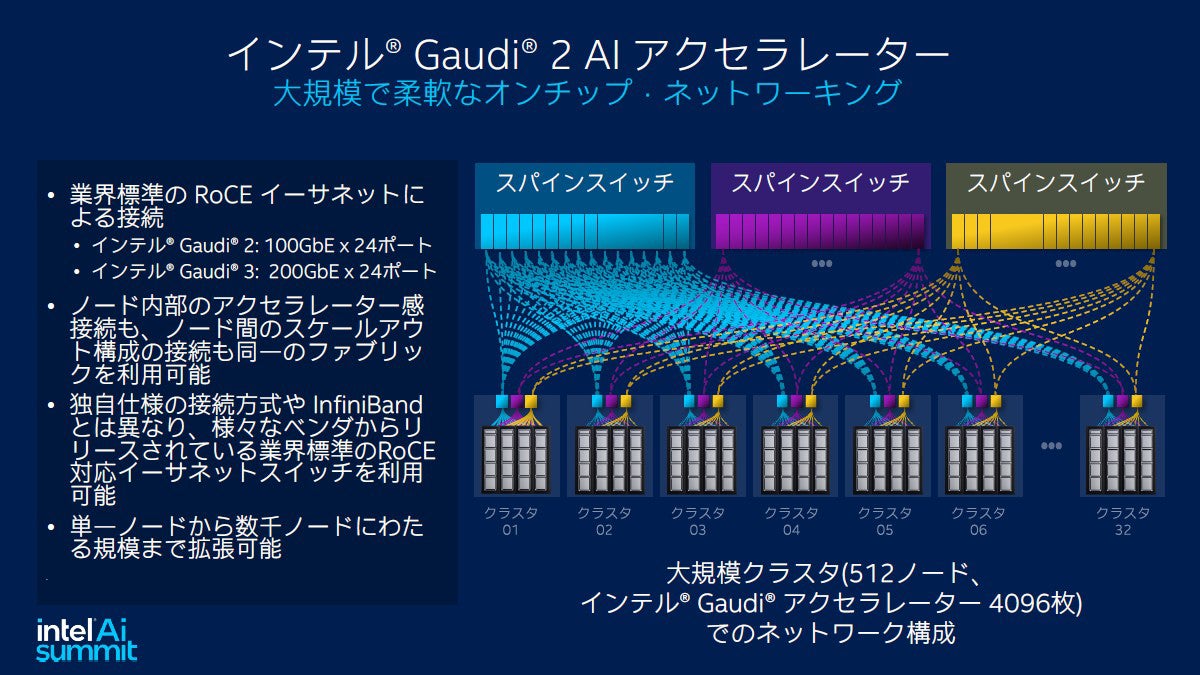
1ボードの利用から、リーフスイッチ、スパインスイッチを使うことで4096枚までの構成に実績がある。業界標準のRoCE対応イーサネットスイッチが利用できるため、スイッチベンダーの柔軟な選択が可能だ

-
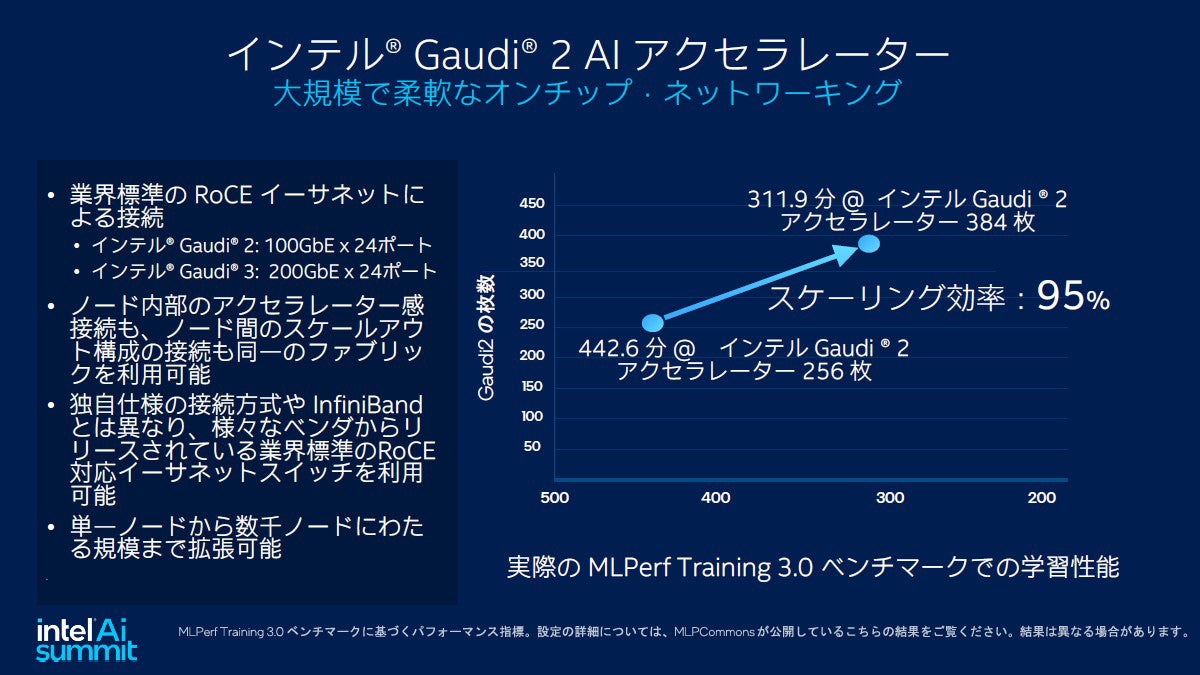
256枚を384枚にしてMLPerf 3.0ベンチマークを実行した結果のスケーリング効率も95%と高い

このため、(自社の秘密データを扱うため、クラウドではなく)オンプレミスで10Bから1T規模の生成運用を行い、チップメーカーを特に選ばないことで調達コストと納期や調達リスクを抑え、業界標準のイーサネットシステムでの環境構築とオープンソースベースの開発環境を使う場合にGaudiは最適であるという。
具体的な利用例として、画像生成のStable Diffusionシリーズで有名なStability.AIはNVIDIAと比較したうえで性能に優れたGaudi2を採用。Gaudi向けのコード変更に関しても一日以内で完了したと説明した。
-

利用事例としてStabilyty.AIを紹介。NVIDIA製品と比較して高速であるという事を検証した上で現在Gaudi2を使用しているという。コード以降も短期間で行えている

また、SupermicroのGaudi2 AI Tranig ServerSYS-820GH-TNR2-01は1サーバーに8枚のGaudi2とホストCPUの第三世代Xeon SPを使用したシステムが現在、期間限定で$90000の特別価格で購入できるようになっていることを紹介していた。
-

現在Gaudi2を8枚使用したサーバーが$90000のキャンペーン価格で提供中との事

さらに進化を遂げたGaudi3の紹介も
さらに小佐原氏は、今回のイベント直前のCOMPUTEXで紹介されたGaudi3についても言及した。Gaudi2は7nmプロセスで製造されているが、Gaudi3では製造プロセスを5nmにまで進化させ、演算に関してもFP8は2倍、BF16は4倍とAI処理能力を増強。ネットワークを100GbEから200GbEにすることで速度も2倍、そしてメモリ帯域を1.5倍と増強。価格は上昇したもののコスパは堅持しているという。
開発環境も同一なため、Gaudi2上で開発テストを行い、Gaudi3が販売されてから本番実行を行うという使い方ができると小佐原氏はアピールしていた。
-

今年後半に登場するのがGaudi3。大幅な性能向上となっている

-

価格は上昇するが高コスパは堅持。Gaudi2で開発しておき、実際の実行はGaudi3で行う事もできる

Gaudi3は現在サンプル提供が開始されており、今年後半から量産出荷される予定となっているという。また、OAM(Open Accelerator Module)以外にPCIeカード形状の提供も予定されている。
システム販売にはGaudi2の時点でのDELL、HPE、Lenovo、SuperMicroに、Asus、Foxconn、Gigabyte、Inventec、Quanta、Wistronも加わる。
-

Gaudi2を国内で購入する場合は実質SuperMicro一択だったとの事だが、Gaudi3はベンダー数が大きく拡大するという

既存コードから2ステップの手順でGaudiを利用可能。GitHubには検証済の参照モデルを公開
後半はGaudiを使うための説明となった。小佐原氏は「Gaudiは特殊な製品でプログラミングも特殊と思われがちだが違う」と説明。いくつかのシチュエーションで紹介した。
-
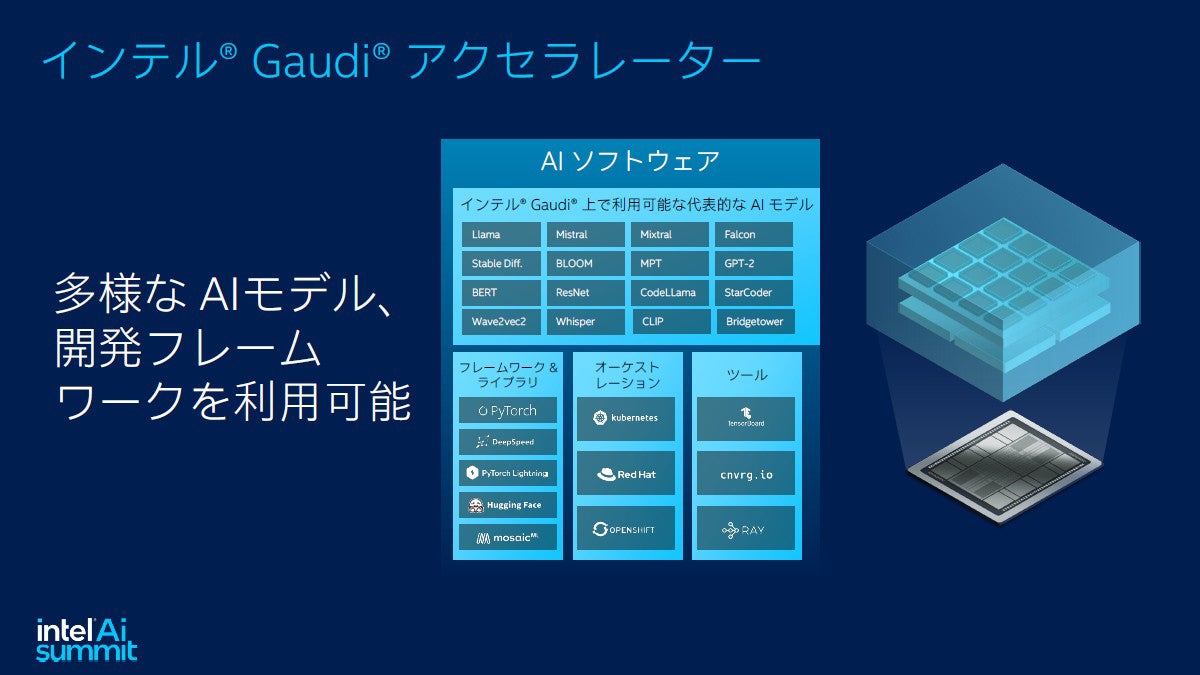
インテルはハードウェアベンダーと思われがちだが開発ソフトウェアも優秀だ。Gaudiに対しても多彩なAIモデルや開発フレームワークをサポートする

-

アプリケーションの移行に関しては3つのシナリオを示した

現在よく使用されているPyTorchをGPUで動作するアプリケーションからの移行の場合、手動で変更するためには結構な量の作業が必要となる。しかし、GPU Migrationツールを使用するとライブラリのインポートと学習ループ部のコード変更だけでGaudiを利用することができる。 またインテルは、20以上の参照モデルを検証してGitHubにて公開しており、このGitHubの検証例をベースとしてあらたなアプリケーションを開発することもできる。
AIではHugging Faceで公開されているコードでの利用も多いが、設定をGaudi向けに置き換えるだけで動作し、現時点で30以上の最適化済モデルが利用可能になっている。
-

GPUベースのソースコードはGaudi PyTorchパッケージに含まれるGPU Migration Toolkitを使うことで少ない工数で変更可能

-

Hugging Faceで公開されているモデルに関しても少ない工数で実行できる

さらにハードウェアを購入しなくても、検証から通常利用まで使用できるインテル Tiber デベロッパークラウドも用意されている。Gaudiだけでなく、インテルの最新製品も、購入せずに確認できる。
-

Gaudiを購入しなくてもインテル Tiber デベロッパークラウドで利用可能だ。詳細はインテルもしくは代理店のエクセルソフトへの問い合わせが必要だ

-
開発者向けのドキュメントも豊富に用意されている

ここまでの話を伺う限り、ライバルとなるNVIDIAのCUDAを駆使したアプリケーションに関しては難しいと思うが、オープンソースを活用したアプリケーションならばGaudiでもアプリケーション開発は実用的であるという印象を受けた。性能に関してもベンチマークだけでなく、AIスタートアップ企業が検証した結果Gaudiを利用していることから十分な競争力があると感じる。
今後はGaudiのコスパや入手性だけでなく、広く使える実用例をさらに示すことが、さらなる拡大につながるだろう。
デモブースではGaudi2の実物ボードの展示に加え、Gaudi2を用いた生成AIのデモを実施していた。
-

デモブース。Gaudi3と書かれているが、デモはGaudi2ベースだった

Llama3-70Bという巨大モデルもGaudi2で実行できていることと、今年5月10日に公開された「『富岳』を活用した大規模言語モデル分散並列学習手法の開発」の研究成果となる(参考記事)「Fugaku-LLM」が動作していた。
Fugaku-LLM研究成果発表会ではHugging Faceで公開するため、ライセンス条件の範囲で誰でも利用できると説明していたが、発表日にはリアルデモがなかったため、今回のインテルのデモ展示はHugging Faceで公開されているFugaku-LLMの動作する実例として大変参考になった。
-
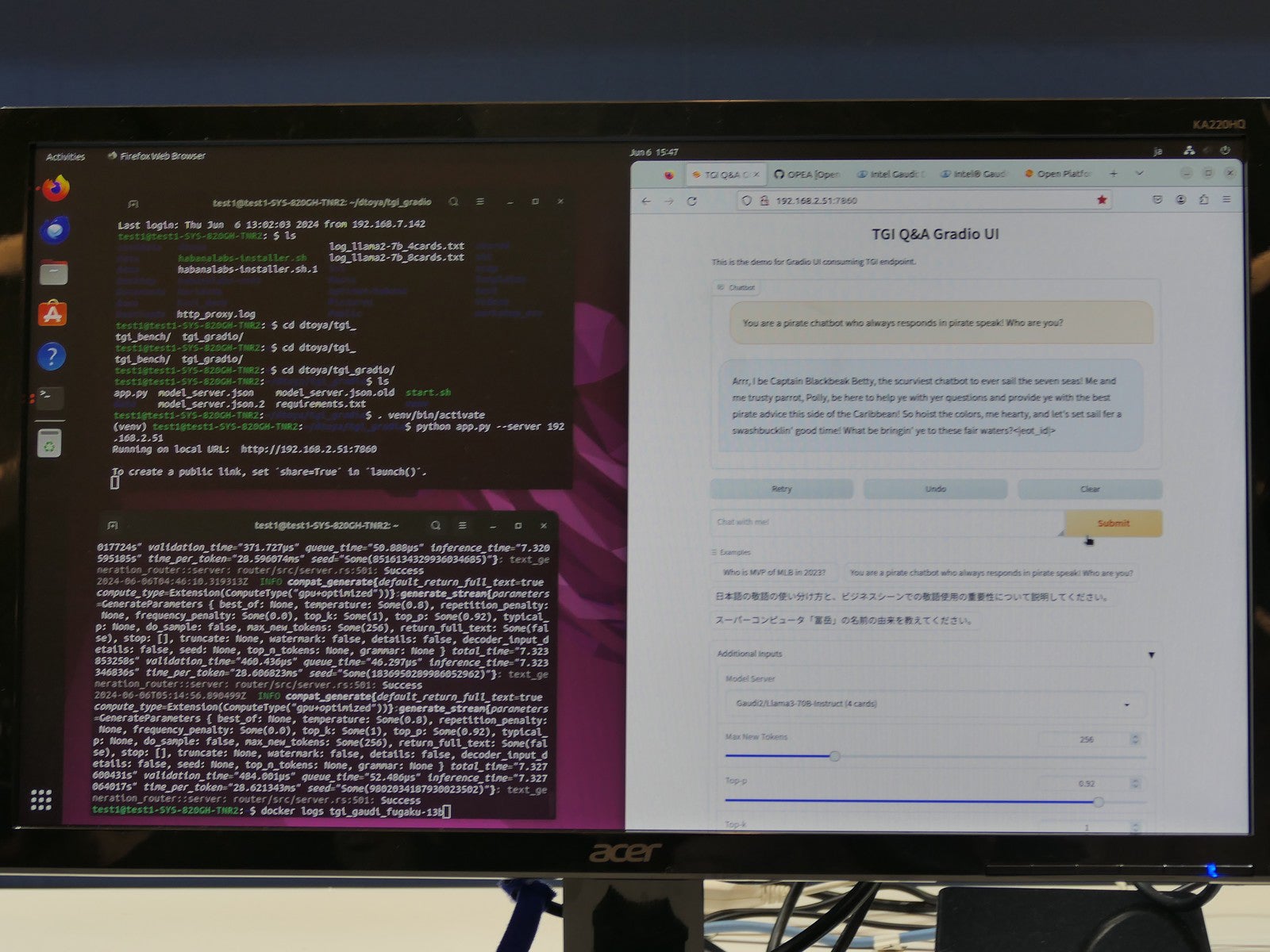
リモートでGaudi2を動作。Chatでプロンプトを入力するスタイルとなっていた

-
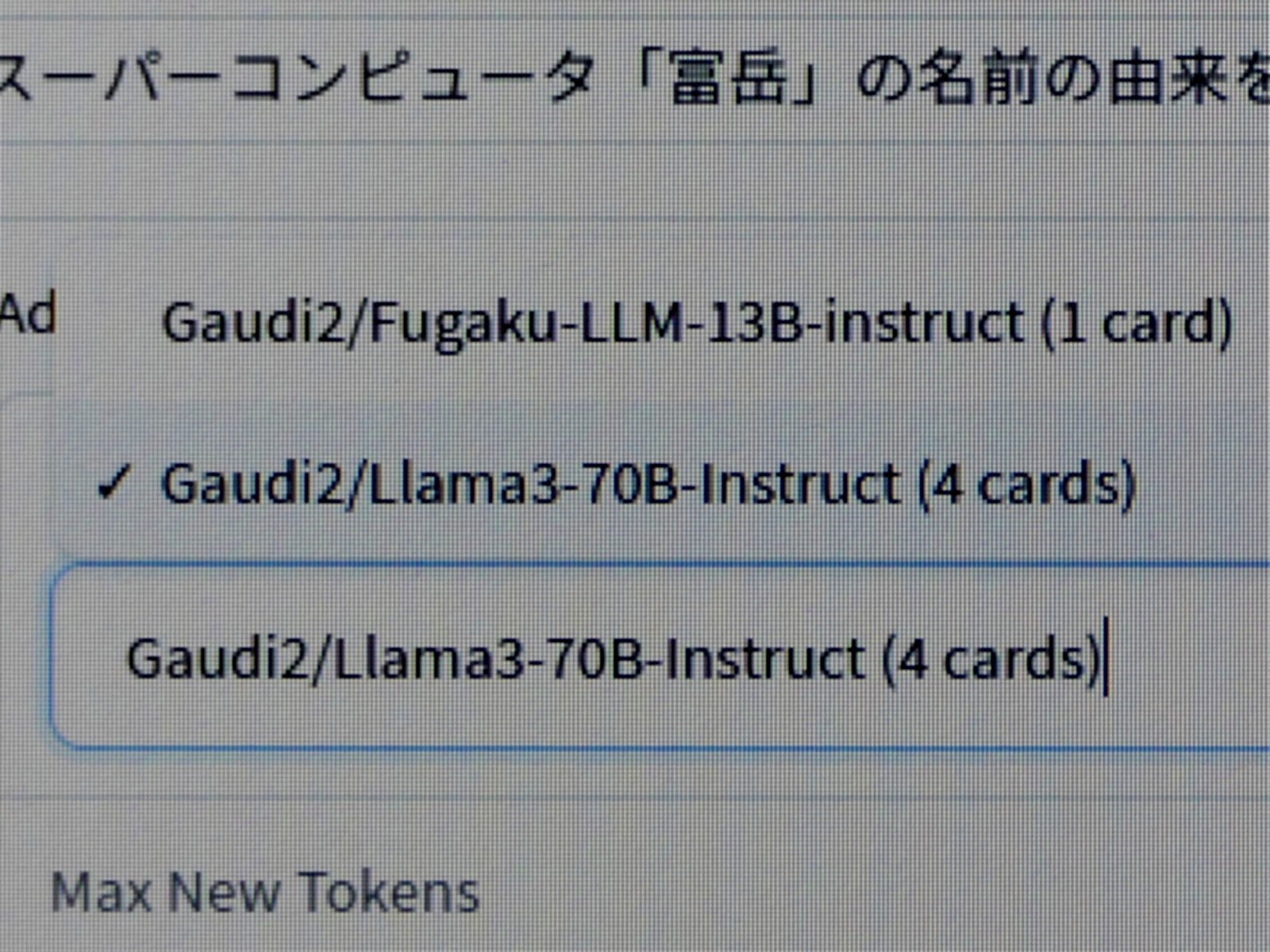
今回用意されていたのはLlama3-70BとFugaku-LLM-13B

-
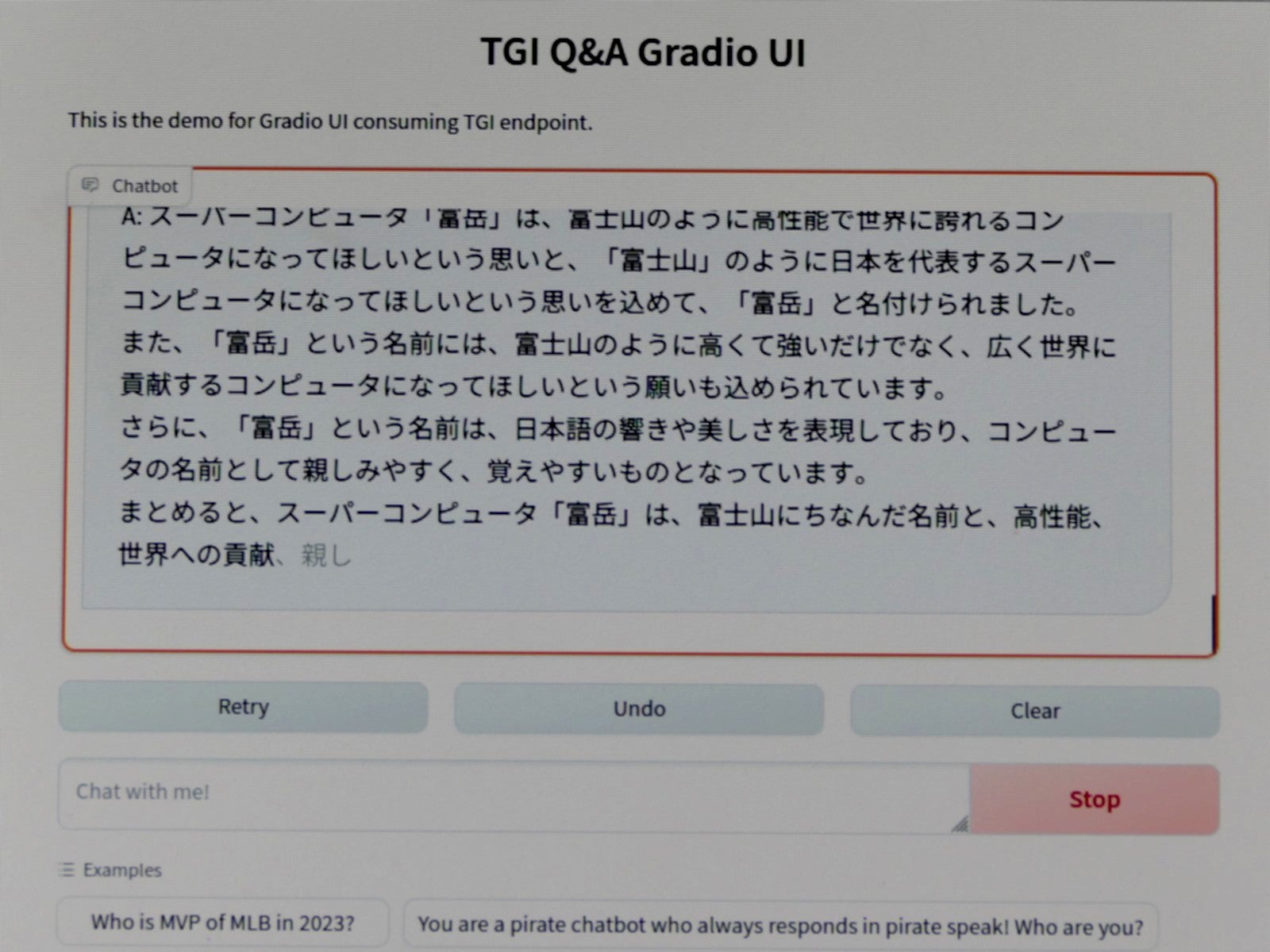
Fugaku-LLM-13Bの実行例。Gaudi2一枚で実行していたが、体感的にはWindows copilot以上の速度で表示していた

一方、COMPUTEXでGaudi3ボードがPat Gelsinger氏によって示され(参考記事)、今回の展示のタイトルもGaudi3となっていたが、デモがGaudi2になっていたのは少々残念だ。ぜひとも実物のGaudi3をこの目で見てみたいと強く感じた。











