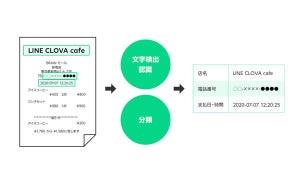
LINEのAIカンパニーは9月7日、国会図書館が保有するデジタル化資料247万点、2億2300万画像を対象とした「デジタル化資料のOCRテキスト化」作業を受託し、「CLOVA OCR」の技術によるモデル開発を実施して全文のテキストデータ化が完了したと発表した。
CLOVA OCRは、書類や画像の文字などの情報をテキストデータへ変換するサービス。文書解析と認識に関する国際会議ICDARにおいて、2019年3月には4分野で世界1位の評価を得たという。
今回テキストデータ化を行ったデジタル化資料の多くは昭和前期以前の資料であり、レイアウトも複雑なため、既存のOCRでは同プロジェクトに必要な精度に達しないことや、2億2300万枚を超えるデジタル化資料の処理に時間を要する点が課題だったとのこと。
-

改善結果報告書の抜粋

そのため、同社のAI-OCRモデル研究開発チームは、CLOVA OCRの技術を基に、同プロジェクト用のOCRモデル開発を実施したという。
結果として、全33区分中、1970年代に出版された雑誌資料を除く32区分で国会図書館の目標値よりも高い認識性能を発揮するモデルが完成し、全文テキストデータ化に寄与したとのこと。
なお、改善結果や同プロジェクト結果の詳細は、国会図書館がNDLラボで公開している。