「Perlmutter」は2020年に稼働予定の米国のPre-Exaスケールのスパコンである。米国で最大のスパコンが設置されるのは、最近はOak Ridge National Laboratory(ORNL)で、現在はORNLのSummitスパコンがTop500の1位である。
Lawrence Berkeley National Laboratory(LBNL)は、ORNLに次ぐ規模の科学技術計算用のスパコンが設置される研究所で、2020年にLBNLのNERSC(National Energy Research Scientific Computing Center)に設置される予定のスパコンがPerlmutterである。NERSCの9代目のスパコンであり、NERSC-9とも呼ばれる。
NERSCのスパコンには大きな業績を挙げた科学者の名前が付けられており、現在のNERSCのメインのスパコンはCoriという名前で、 Gerty Coriから名づけられている。Gerty Coriは、アメリカ人(生まれはオーストリアである)の女性としては初めてノーベル賞を受賞した生化学者である。
そして、Perlmutterは宇宙が加速膨張している証拠を見つけてノーベル賞を受賞したSaul Perlmutter教授にちなんだ命名である。なお、Perlmutter氏は健在で、現在もカリフォルニア大バークレイ校の教授である。
このPerlmutterスパコンについて、PerlmutterのチーフアーキテクトであるNicholas Wright氏がGTC 2019で講演した。
-

GTC 2019で講演するPerlmutterのチーフアーキテクトのNicholas Wright氏

NERSCはエネルギー省の主要スパコンセンターの1つであり、科学の発展とスーパーコンピューティングを発展させるという使命を担っている。そして、コンピュータのメーカーと協力してスパコンの開発を行い、アプリケーションプログラムの開発を行っている。
-

NERSCは、科学の発展とスーパーコンピューティングを発展させるという使命を担っている(このレポートのすべての図は、GTC 2019でのWright氏の発表スライドのコピーである)

次の図は米国の先端スパコンのロードマップを示すものである。Perlmuttterは科学技術研究用のスパコンであり、Summitに続くスパコンと位置付けられている。この先は、Exaスケールの時代になり、Argonne国立研究所のA21(Aurora 21)、ORNLのFrontier、LLNLのEl Capitanなどのスパコンが予定されている。
-
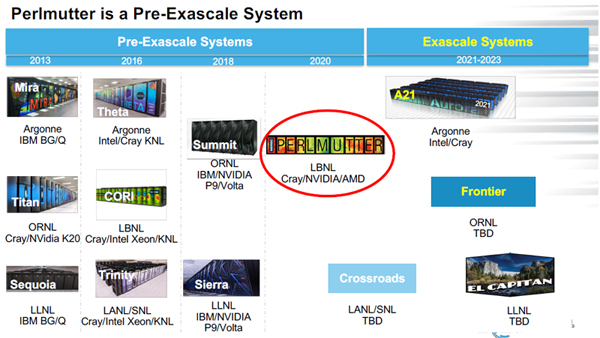
PerlmutterはSummitやSierraと並ぶ米国のPre-Exaスパコンである

その中でNERSCとしてはEdison(NERSC-7)、Cori(NERSC-8)に続いて2020年にPerlmutter(NERSC-9)を稼働させる。そして、その先には2024年のNERSC-10、2028年のNERSC-11と4年ごとのペースで次世代スパコンが続いている。
-
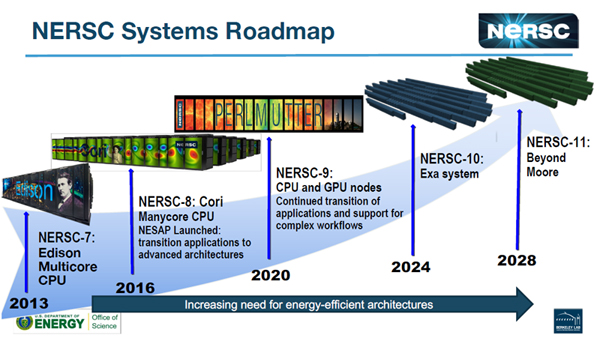
PerlmutterはNERSCの9代目のスパコンであり、NERSC-9とも呼ばれる。NERSCは、その後も4年ごとの更新を計画している

現用機のCoriはCrayのXC40スパコンで、IntelのKnights Landingプロセサを使う計算ノードを9600あまり使用している。これにIntelのHaswellプロセサを使うノードが1600、NVRAMのバーストバッファが1.5PBと30PBのディスクが付いている。
Top500の登録データでは、Coriのピーク演算性能は27.88PFlops、HPL性能は14.01PFlopsとなっている。
-

CoriはCrayのXC40スパコンで、IntelのKnights Landingノードを9600ノード以上使っている

PerlmutterはGPUをアクセラレータとして使うスパコンで、GPUをつけたノードと大量データを扱うためのCPUだけの計算ノードを搭載している。そして、計算ノード間を接続するインタコネクトはCrayのSlingshotである。Slingshotは高性能でスケーラブルで、低レーテンシのEthernetと互換なネットワークである。
ストレージとしてはオールフラッシュでCoriのファイルシステムの6倍の性能を持つLustreファイルシステムを持つ。また、複雑なワークフローをサポートするための高メモリノードを持っている。
なお、PerlmutterのキャパシティはCoriの×3-4となっており、Sierra(ピーク125.7PFlops)を若干下回る規模になるのではないかと思われる。
-
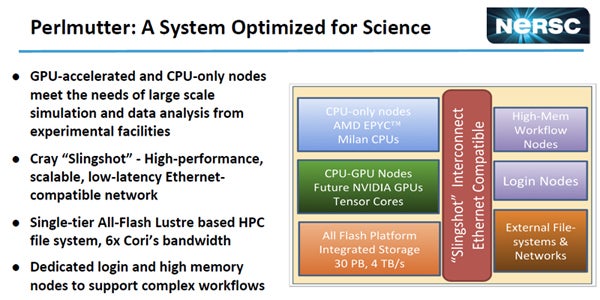
PerlmutterはAMDのMilan CPUにNVIDIAのVolta-next GPUをアクセラレータとして付加する。また、大容量メモリを搭載し、GPU無しのノードも持つ。インタコネクトはCrayのSlingshot。オールフラッシュのLusterファイルシステムを使う

GPUノードはAMDのMilan CPU(開発コード)に4台のNVIDIAのVolta-next GPUを接続する。Volta-nextということで、現在のV100より改良されたものとみられるが、具体的にどのようなものかは明らかにされなかった。
そして、GPUノードからは25GB/sのSlingshotが4ポート出ており、これでPurlmutter全体のネットワークを作ると考えられる。KNLを使ったCoriのノードと比較すると、GPUノードは×2-3の性能とのことである。
-

PerlmutterはNVIDIAのVolta-next GPUをアクセラレータとして使う。性能はCoriの×2-3XA@Perlmutter

CPUはAMDのZen3アーキテクチャのMilan CPUを使う。右下の写真の両脇の8個の小さいチップが7nmプロセスで作られる8コアCPUチップで、中央の大きなチップがメモリコントローラやPCIeなどの外部接続を担うI/Oチップである。
-

CPUはAMDのZen3アーキテクチャのMilanを使う

Perlmutterは科学技術計算に最適化されており、GPUアクセラレータ付きのノードと大量のメモリを使うシミュレーションや大規模データ解析のためのCPUオンリーの計算ノードを持っている。
-
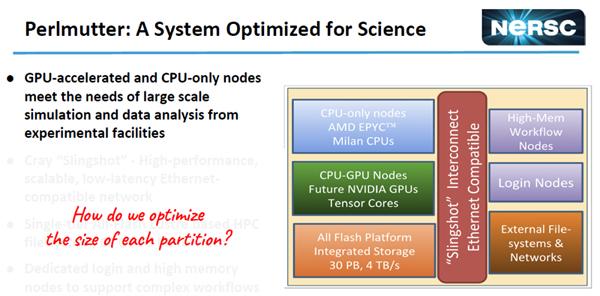
GPU付きのノードとGPUは無しで大量のメモリを搭載するノードの2種類を使う。どのようにしてこの2種のノードの搭載比率を最適化するか?

NERSCには7000人のユーザが居るが、 3つのアプリケーションでワークロードの25%以上を占めている。上位10種のアプリケーションでは50%、上位30種のアプリケーションでは75%のワークロードとなっている。一方、残りの25%のワークロードはその他の600以上のアプリケーションの実行に分かれている。
-
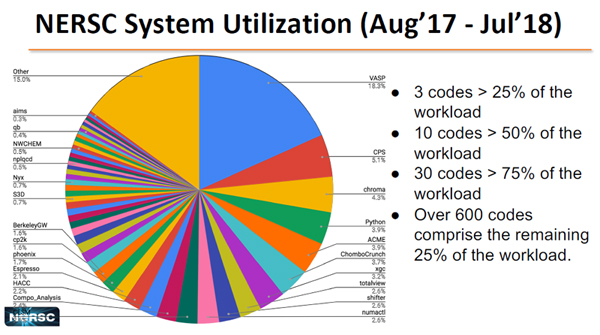
NERSCでのアプリケーションの使用状況。上位の3つのアプリで、計算時間の25%以上を占めている

現在のCoriではGPUを使っておらず、Perlmutterでそれらのコードが使えるかどうかが問題になるが、調査したところ、32%のアプリケーションでは大部分の機能がGPUに移植されており、部分的に移植が進んでいるものが29%であった。しかし、14%のアプリケーションでは移植は進んでおらず、移植には大きな手間が掛かることが判明した。また、25%のアプリケーションは状況が不明であった。今後、これらのコードの移植を行って行く必要がある。
-
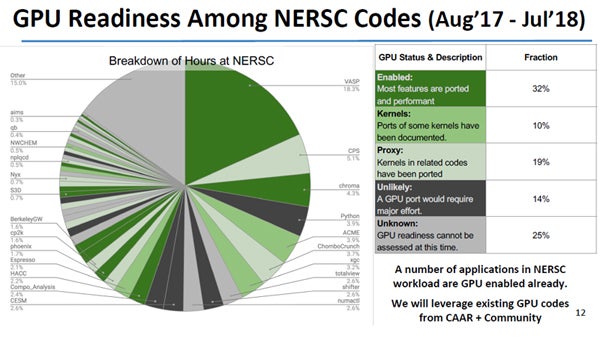
NERSCで使われているアプリケーションのGPU対応状況。32%のアプリケーションではほとんど移植ができており、29%のアプリケーションでは部分的にGPU移植が進んでいる。しかし、14%のアプリケーションは移植が進んでいない、あるいは移植が困難である。また、25%のアプリケーションでは状況が不明である

GPUノードとCPUオンリーノードを使うので、どれだけGPUノードを置くべきかということが問題になる。この検討のため、下の図の右の表に書いた代表的なアプリケーションを実行する場合のリファレンスマシンとの性能比であるScalable System Improvementを求める。
-

GPUノードの設置比率を決めるため、リファレンスノードとの性能比であるScalable System Improvementを求める

次の図の右側の3本の折れ線グラフがGPUノードのコストがCPUノードの8倍、6倍、4倍の場合のSSIの変化を示す。横軸は、GPUノードに使う予算の比率である。この分析の結果、一番下の折れ線のGPUノードのコストが8倍の場合は、GPUを買う意味はない。6倍の場合は25%の予算をGPUノードに使うのが最適で、SSIは1.05倍になる。GPUノードが4倍のコストの場合は50%の予算をGPUノードに使うとSSIは1.23倍になるという結果が得られた。
-
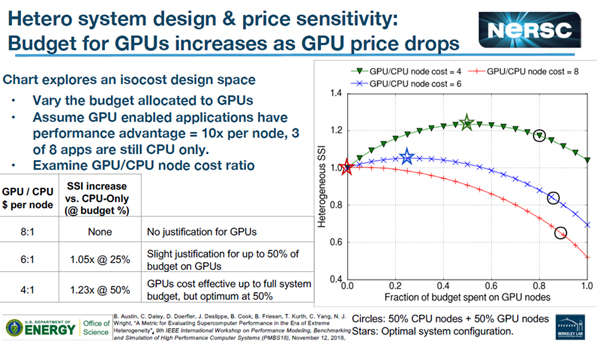
GPUノードのコストがCPUオンリーノードの8倍、6倍、4倍と仮定し、GPUノードに割く予算を横軸にとり、システム全体のSSIを求めた。8倍の場合は、GPUを買う意味はない。6倍の場合は25%の予算をGPUノードに割き、4倍の場合は50%の予算をGPUノードに割くのがSSIを最大にする

また、8アプリの内の5アプリで、ソフトウェアの最適化でGPUノードの性能がCPUノードの10倍、20倍、30倍になると想定する。そして、GPUノードのコストはCPUノードの8倍とする。
この場合、性能が10倍になるのではGPUを使うメリットは無いが、20倍であると45%の予算をGPUノードに使えばSSIは1.15となる。また、30倍の性能になるとすると、60%の予算をGPUノードに使うとSSIは1.60となる。
Wright氏は、このような分析を示したが、GPUノードのコストやGPUを使用することによる性能向上をどう見るかについては触れられず、PerlmutterでGPUノードの比率がどの程度になるのかは明らかにされなかった。
-

GPUノードのコストが8倍でも、GPU向けのチューニングでアプリケーション性能が20倍、30倍になれば、SSIは1.15倍、1.4倍とGPUノードのメリットが出る

結果として、アプリケーションのGPU化とチューニングによる性能向上が重要で、NERSCのExascale Scientific Application Program(NESAP)により、~25のアプリケーションを最大17人のポスドクを使って最適化したり、他の化学計算を担当する部門やベンダーの経験を利用してアプリケーションの準備を進める。
そして、Perlmutterでの性能改善のドキュメントを作ってユーザを教育し、複数のアーキテクチャで性能が出せるようにコードを最適化するなどを推進する。
-

NESAPで17人のポスドクを雇い~25アプリケーションをPerlmutterに移植する。他部門との連携やベンダーの経験の活用を行う。また、ドキュメントの作成やトレーニングで移植の知識を広める

PerlmutterでのNESAPがこれまでと違うのは、ノード内での並列性を明らかにし、データの局所性の改善が重要になる点である。
-
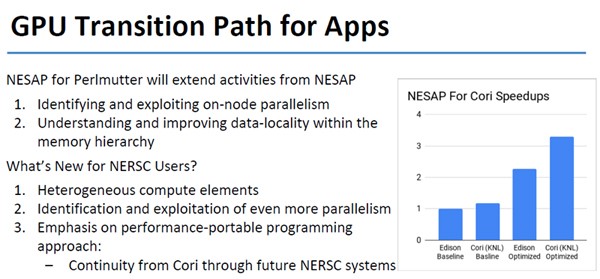
そして、NESAPではノード内での並列性を明らかにし、データの局所性の理解を推進する。そして、高性能を保てる移植のやり方に重点を置いて開発を行う

次のグラフは2017年のユーザサーベイの結果であるがOpenMPが最も広く使われている並列化手法で、90%のユーザが使っている。CUDAを使っているユーザも30%程度存在する。
-
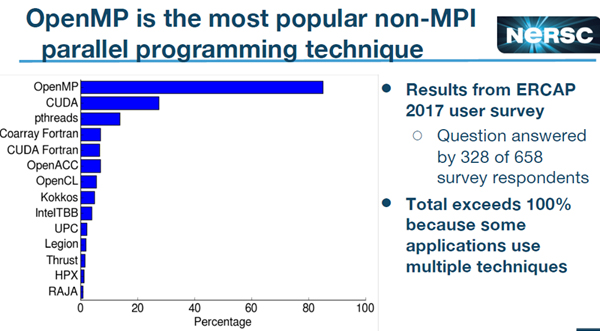
MPI以外の並列プログラミングツールの使用状況。OpenMPを使っているユーザが90%近い。CUDAを使っているユーザも30%近い

OpenMPはC、C++やFortranをサポートしており、NERSCのプログラム資産と相性が良い。また、DOEの研究所の異なるアーキテクチャのスパコンへの移植性もよい。そして、OpenMP 5.0ではアクセラレータが使えるようになった。
-

OpenMPはC/C++、Fortranでサポートされており、最近のOpenMP5.0ではアクセラレータもサポートされた。OpenMPで書いておけば、他の研究所のスパコンにも移植しやすい

ということで、PerlmutterでOpenMPが使えるようになることは重要で、NERSCはNVIDIAと協力してPGIコンパイラでOpenMPが使えるようにする。
-

OpenMPが良いと考えられるので、NVIDIAと協力してPGIのコンパイラでGPUでのOpenMPのサポートを行う

NERSCがNVIDIAと協力してPerlmutterのコンパイラを開発するというニュースが発表された。

また、NERSCは高性能の移植を可能にするOpenMPやOpenACCの開発に協力する。

CrayのSlingshotは低レーテンシで高バンド幅のネットワークで、3ホップでシステム内のどのノードにも届く。また、高度な適応型の混雑回避アルゴリズムを使っており、レーテンシのばらつきが小さい。
SlingshotはEthernetと互換であり、システム外の装置にも直接つなぐことができ、ストレージとも直接接続できる。
-
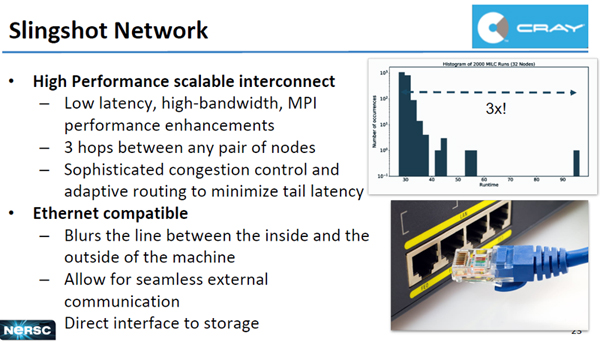
CrayのSlingshotは3ホップで、全ノードに届く低レーテンシの高バンド幅ネットワークである。Ethernetと互換性があり、ストレージに直結したり、外部のネットワークに接続したりすることができる

Perlmutterはオールフラッシュのファイルシステムを持ち、4TB/sの連続使用バンド幅をもち、7,000,000 IOPSのアクセスが可能である。また、毎秒320万個のファイルのCreateができる。ストレージはなじみのあるLustreで30PBの容量が使える。
-
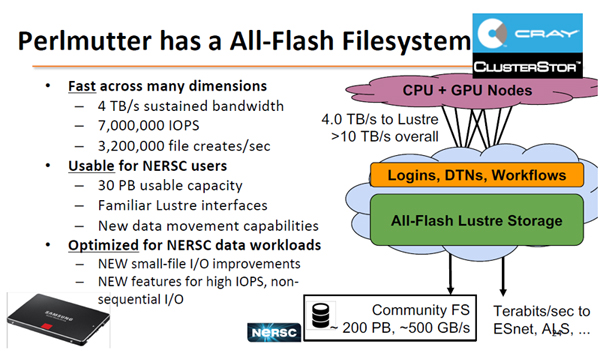
PerlmutterのストレージはオールフラッシュのLustreファイルシステムで、30PBをNERSCユーザで使用できる。連続使用できるバンド幅は4TB/sと高バンド幅である

Perlmutterは、科学計算に最適化されたシステムである。CrayのShastaシステムであり、現有のCoriの3-4倍の性能を持つ。そして、大規模シミュレーションとデータ解析に対応できるNERSCとしては最初のスパコンである。
2020年の遅い時期に設置される予定で、シミュレーション、データ解析、ラーニングなどのアプリケーションの準備を進めている。
-

PerlmutterはCrayのShastaスパコンであり、Coriの×3-4の能力を持つ。NERSCのシステムとしては、初の大規模シミュレーションと大規模データ解析ができるスパコンである。納入は2020年の遅い時期を見込んでいる