HEPはGPUのマイクロアーキテクチャの先駆け
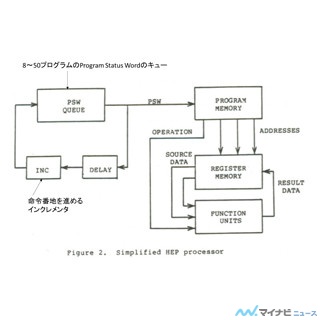
HEPアーキテクチャの特徴的なところは、PSWキューと制御ループで、このキューから次々と読み出されたPSWの指す命令を実行していくという制御方法である。この方式では、例えば8個のPSWがキューにある状態では、 8個のプロセスを順に実行することになる。つまり、個々のプロセスの命令は8サイクルに1回実行され、クロックは10MHzであるので、個々のプロセスの命令実行速度は1.25μs/命令となる。
HEPの演算器は8サイクルで演算を行うように作られているので、ある命令の演算結果が得られるタイミングで、そのプロセスの次の命令が実行されることになり、キャッシュを持たなくても演算レーテンシを隠すことができるという設計になっている。
このHEPの命令実行方式は、8個以上のスレッドを切り替えながら並列に実行するという点で、従来のスカラプロセサやベクタプロセサと大きく異なっている。この実行方式は、毎サイクル、実行するスレッドを切り替えるという点でNVIDIA GPUのSIMT実行と似ており、筆者は、GPUのマイクロアーキテクチャの先駆けとも言えるのではないかと思っている。
レジスタとデータメモリの間のデータ転送を行うためにSFUというユニットが設けられており、このユニットはスイッチネットワークにパケットを送り、データメモリとレジスタ/定数メモリ間のロード/ストアを行う。SFUはこのロードストアを行うパケットを発行したプロセスを制御ループから除外してSFU内部のキューに保持し、応答パケットが返ってくるまで、制御ループに再挿入しないというやり方で長レーテンシの命令を扱っていた。。
ファンクションユニットは、浮動小数点演算の加減乗除とCompareをサポートしていた。
HEPはマルチプロセスのマシンであるので、特別な機能として、条件分岐のようにユーザ状態で条件に従ってプロセスを生成したり、終結したりする命令をもっていた。
そして、実行条件の整っていない命令は実行されないで、プログラムカウンタを更新しないで、再度、制御ループに挿入されて次回に実行が試みられる。
同じ、保護ドメインで動作するプロセスはタスクと呼ばれる。HEPは7個のユーザタスクとそれに対応するスーパバイザタスクを実行できる。ユーザプロセスはCreate命令を実行して、そのタスクの中に新しいプロセスを生成できる。特権命令を使えば、どのタスクにでもプロセスを生成したり、タスクに含まれるすべてのプロセスを終了したりすることができるようになっていた。
HEPのJobは1個以上のタスクで構成される。1つのジョブに含まれるタスクは、同一のメモリを割り当てることにより、データの受け渡しや通信が行なえるようになる。
プロセサがサポートできる最大のユーザプロセス数は50であった。
そして、HEPは16CPUまで拡張できる設計であったが、実際に作られた最大規模のシステムは4CPUで、図3.6のようなものであった。
HEPのCPUとデータメモリ、I/Oシステムは、3ポートのパケットスイッチ網で接続されていた。CPUとデータメモリの間の接続はバタフライネットワークで、どのCPUからどのデータメモリにも接続できるようになっており、したがって、I/Oシステムからもどのデータメモリにもアクセスできる構成になっていた。
3ポートの双方向のルータは、3ポートの出力は入力ポートの順序を並べ替えたものになっており、内部にデータが溜まってしまったり、消えて仕舞ったりすることはないという構造であり、その性質が保たれているかをチェックしてエラーを検出していた。また、パケットのパリティーチェックによるエラー検出も行っていた。
パケットは終着点に近づく出力ポートに送られるが、その出力ポートが使われている場合には、パケットが遠回りをする。そのようなケースでは迂回の回数を数えてパケット処理の優先度上げるという方法が取られていた。
スイッチの通過時間は50nsで、スイッチ間のケーブル長は最大4mとなっており、これで100nsの周期で1パケットを処理することができた。
-
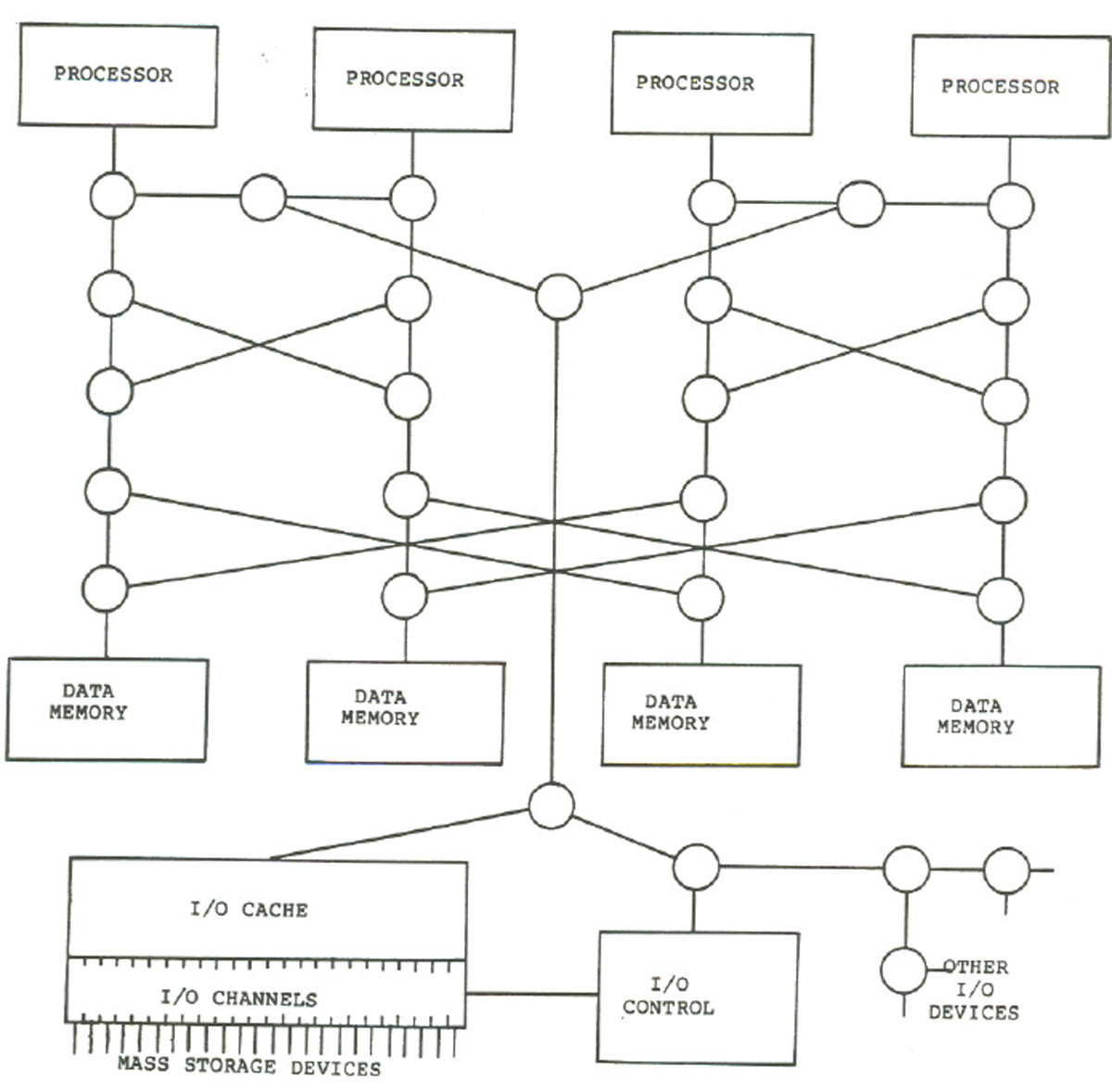
図3.6 4CPUのHEPシステム。〇は3ポートの双方向スイッチである。HEP CPUとデータメモリを接続し、さらにCPUにI/OコントロールとI/Oキャッシュを接続している

(次回は10月4日に掲載します)