


そしてディープラーニングへ
前回までに、オープンデータを活用し、教師なし学習、教師あり学習を実践してきました。また、「決定木」「ロジスティック回帰」手法の違い等にも触れ、機械学習のイメージができてきたかと思います。
今回は、最終回ということで、昨今話題になっているディープラーニングの入口であるニューラルネットワークに触れ、今後の広がりに関してご紹介していこうと思います。なぜディープラーニングがこれほど注目されているか、少しでもイメージできるように説明していきます。
線形分離の限界
今回は、これまでとは違いオープンデータではなく、イメージしやすいサンプルデータを用います。
いつものようにJupyter Notebookを立ち上げ、右上のNewから、Notebookを開き、タイトル名を変更しておきましょう。今回は、NeuralNetworkという名前にしました。今回は、データを生成するのでデータダウンロードは必要ありません。まずは、下記コードを実行し、データ生成・可視化を行ってみましょう。
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import make_moons
X, Y = make_moons(n_samples=100, noise=0.3, random_state=0)
data = pd.DataFrame({'X0':X[:, 0], 'X1':X[:, 1], 'Y':Y})
plt.scatter(data['X0'],data['X1'], c=data['Y'])-
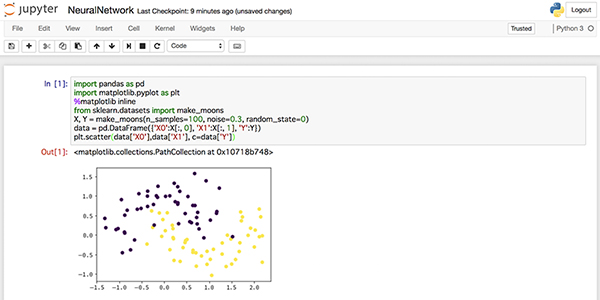
データ生成および可視化

まずは、1から4行目までが必要なライブラリのインポートとなります。4行目でデータ生成のためのライブラリをインポートし、5行目で実際にデータを生成しています。6行目では、これまでのCSVと同様に扱えるようにデータを成形しています。最後に可視化を行なっています。こちらの図を見ると、make_moonsという名前からもわかるように、円弧状に上下にわかれたデータが生成されています。5行目のn_samples、noise、random_stateを変化させるとデータも若干変化するので試してみてください。また、興味のある方は、data.head()等でデータを眺めてみるのも良いでしょう。
さて、これらのデータを分割する線を引くこと(=学習)を考えていきましょう。今回は、ロジスティック回帰を使って分類をしてみます。予測モデルの作成から可視化まで一気にやってしまいましょう。また、今回は、正解、不正解がわかるように2種類のプロットと分割線も引いていきます。
from sklearn.linear_model import LogisticRegression
import numpy as np
logisticModel = LogisticRegression()
logisticModel.fit(X, Y)
predicted = pd.DataFrame({'logisPredicted':logisticModel.predict(X)})
data_predicted = pd.concat([data, predicted], axis =1)
plt.scatter(data_predicted['X0'],data_predicted['X1'], c=data_predicted['Y'])
plt.scatter(data_predicted['X0'],data_predicted['X1'], c=data_predicted['logisPredicted'], marker='x')
a = logisticModel.coef_[0,0]
b = logisticModel.coef_[0,1]
z = logisticModel.intercept_[0]
x = np.arange(-1.5,2.5,0.1)
plt.plot(x,(-a*x-z)/b)-
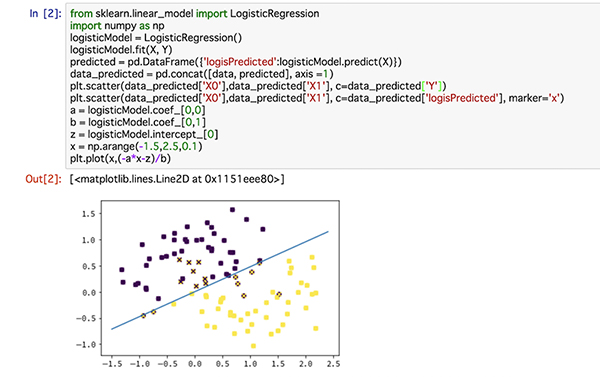
ロジスティック回帰

1行目でロジスティック回帰、2行目でnumpyのライブラリをインポートしています。3から6行目までが、ロジスティック回帰の実行、データ成形、data_predictedへの格納となっています。興味がある方は、data_predictedを一覧表示して見てみても良いと思います。7行目で正解データの可視化、8行目で予測データの可視化を行なっています。予測データはマーカーにバツ印を指定しています。そうすることで、不正解データではデータ点にバツ印が表示されます。9行目からは分割線を引く作業となります。
上図中のグラフを見るとわかるように、ロジスティック回帰では直線によって分割します。これを線形分離と呼びます。これは、第6回でも紹介したように、線形回帰の関数Y=aX1+bX2+zを0から1の範囲に押し込めてしまう関数を使用し、分類を行なっていることに起因しています。実際に、線の上下にバツ印、つまり不正解データが数多く見られます。ここから、今回のような複雑なデータでは線形分離するのは不可能であることがわかります。
ニューラルネットワーク
では、ロジスティック回帰の代わりにニューラルネットワークという手法を用いるとどうなるかやってみましょう。あとで説明は行うので、まずは深く考えずに、ニューラルネットワークという手法を使うとどう分類できるかを見てみましょう。
from sklearn.neural_network import MLPClassifier
mlpModel = MLPClassifier(solver='lbfgs', random_state=0, hidden_layer_sizes=(20, ))
mlpModel.fit(X, Y)
mlpModel.predict(X)
predicted = pd.DataFrame({'mlpPredicted':mlpModel.predict(X)})
data_predicted = pd.concat([data, predicted], axis =1)
plt.scatter(data_predicted['X0'],data_predicted['X1'], c=data_predicted['Y'])
plt.scatter(data_predicted['X0'],data_predicted['X1'], c=data_predicted['mlpPredicted'], marker='x')-
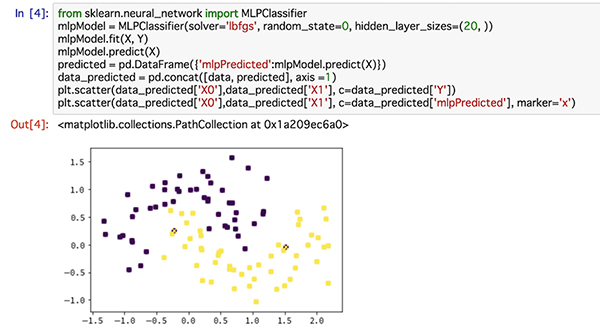
ニューラルネットワーク

新しい手法ですが、ロジスティック回帰や決定木と流れは同じです。まずは、1行目でモデルのインポートを行い、2行目でモデルの定義を行なっています。モデル定義の詳細は一旦気にせず、進めていきましょう。それ以降の流れは、先ほどのロジスティック回帰とまったく同じです。1点だけ違うのは線の可視化がないことです。
さてこちらのグラフを見ると先ほどとは違い、2点を除いて、上手く分類できていることがわかります。つまり、線形分離できないものもニューラルネットワークを用いることできれいに分類することができるということです。まずは、ロジスティック回帰とニューラルネットワークの分類の仕方が違うことをイメージできましたでしょうか。
では、ニューラルネットワークというモデルについて少し考えていきましょう。脳は、いわゆる神経細胞ニューロンのネットワークによって成り立っています。これをモデル化(模倣)することで、人間と同じような高度な処理ができるのではないかという期待からニューラルネットワークは生まれています。そこで、まずはニューロンのモデル化が行われました。
-
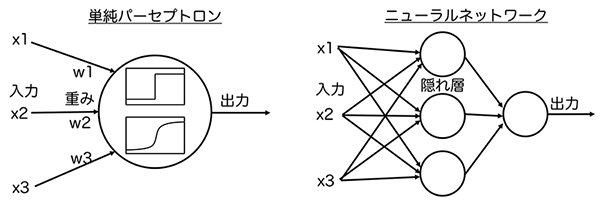
単純パーセプトロンとニューラルネットワーク

図にあるように、ニューロンを模したモデルとして単純パーセプロトンがあります。これは、単純な入力層と出力層からなります。x1等の入力に対して、重みづけされ、閾値を超えた場合は1(発火)を出力します。実は、閾値を離散的(ステップ)ではなく、なめらかにしたものがロジスティック回帰です。ロジスティック回帰の関数Y=aX1+bX2+zでいうa、bがこの図でいう重みに相当します。
ただ、先ほどロジスティック回帰で直面したように、単純な入力層と出力層からだけだと線形分離が不可能な場合に上手く分類することができません。そこで、中間層として少なくとも1つ以上の隠れ層を追加したニューラルネットワーク(多層パーセプトロン)が提案されました。これによって、線形分離できないケースもきれいに分類できるような複雑なモデルを作成できるようになったのです。
ニューラルネットワークの特徴は隠れ層にありますが、隠れ層の層数や、隠れ層のノード数(図でいう隠れ層の◯の数)を調整することでモデルをチューニングすることができます。隠れ層の役割は、端的に言うと新しい説明変数を生み出すことです。入力層である説明変数は、物価指数など人間が理解しやすい形が使用されています。それらを一旦、隠れ層に通すことで、コンピュータが学習した重みづけを受けて、いくつかのノードに格納されます。それらを説明変数として最後の分類が決定されます。つまり、学習の結果、人間には理解できない(しにくい)説明変数が隠れ層に生成され、最適な分類をすることになります。
このように人間には理解できないロジックで分類(判断)をするといった部分が、人間を超えるという期待感を生んでいるのかもしれません。一方で、現状、機械は我々に納得のいくような説明をしてくれるわけではないということを考慮する必要があります。人間がさまざまなオペレーションを実行しなくてはならない人間中心社会である以上、人間に説明する必要があり、そういったデータを取り扱う場合はニューラルネットワークよりも、決定木やロジスティック回帰の方が良いと思います。さらに、我々は複雑なモデルを作成することが目的ではなく、あくまで汎化性能の高いモデルを作ることが目的です。複雑なモデルは、過学習に陥る傾向にある点も注意が必要です。そういった観点から、マーケティングのように多種多様なデータを取り扱う場合には、ニューラルネットワークは繊細すぎるように思えます。
ディープラーニング
では、なぜディープラーニングはこんなに注目されているのでしょうか。ディープラーニングは、先ほどの隠れ層を多層化したものです。これは、先ほど実際に取り組んでわかるように、より複雑なモデルを構築することが可能です。つまり、コンピュータによる、より複雑な推論が多くの隠れ層を通して行われることになります。人間ができることは、インプットとアウトプットを定義することだけで、その過程でどんな推論(処理)が行われたかということは、人間には理解できません。一方で、データに敏感であることには違いはなく、過学習に陥らないように、適切なデータ前処理や大量のデータを必要とします。
では、どういったデータが適切でしょうか。その1つは画像です。画像はピクセルの数だけデータが存在し、フォーマットもほぼ決まっています。60×60ピクセルであれば、360個の説明変数が存在し、すべて数字データとして取り扱えます。ディープラーニングの代表的な使用例として画像認識があげられるのはそのためです。
Googleがディープラーニングを使って猫を認識したのは有名な話ですが、そのインパクトは、人間が特徴を抽出したのではなく、コンピュータが自律的に特徴を作り出したところにあります。一般的には、猫といえば、耳がある、目があるというように猫の特徴を設定します。しかし、ディープラーニングの場合、猫の画像、猫以外の画像を与えるだけで、勝手にコンピュータが猫の特徴を見つけ出します。それは人間が考えた特徴とは違う可能性があります。そうすると、人間では判別できない虎っぽい猫も、コンピュータなら判別できる可能性があるということです(あくまでも可能性です)。
画像以外にも、音声やセンサデータ等へのディープラーニングの適用が進んでいます。人間には理解できないという気持ち悪さはありますが、画像認識や音声認識はどう判別したかよりも、判別できることの方が重要であり、その利便性から応用はどんどん進んでいくでしょう。
これで、本連載は終了です。実際に手を動かしながら、機械学習のイメージをつかむことはできましたでしょうか。こんなことができるというイメージがつけば、あとはさまざまなデータを用いて機械学習に取り組んでスキルを伸ばしていくことが重要だと思います。
機会学習の概要に始まり、最後にディープラーニングの説明を行いました。実際に手を動かしたこともあり、なぜディープラーニングが注目されているか、イメージが一歩深まったのではないでしょうか。本連載では、実際に扱うことができませんでしたが、文章を識別するテキストマイニング、ディープラーニングを用いた画像認識、自律的に学習していく強化学習など、まだまだ奥が深く広がりもある分野だと思います。また、機会があればご紹介させていただきます。
今回、まずは機械学習の入口に立ち、最初の一歩は踏み出せたのではないでしょうか。少しでも、みなさんの最初の一歩をサポートできたとすれば幸いです。ありがとうございました。
著者プロフィール
下山輝昌
大手電機メーカーにて、ハードウェアの研究開発に従事した後、独立。独立後はソフトウェア、データ分析等において実務経験を積むとともに、数社を共同創業。その中でも合同会社アイキュベータでは、人工知能・IoTなどの可能性や方向性を研究している。最近では、オープンデータに着目し、オープンデータ活用のためのwebサービスの立ち上げ、オープンデータ×IoTによる価値創出を1つのテーマに取り組んでいる。










