米Intelは6月24日よりオンラインの形で開催されているISC 2021の基調講演で同社のHPC向け製品の動向を紹介。すでに投入済のIce Lake-SPベースXeon Scalableの性能の高さに加え、次世代CPU/GPUの動向などを発表した。この基調講演の模様は上のリンク先から視聴できるが、事前説明会の内容を元にポイントをご紹介したい。
-

Photo01:HPC分野に向けてのSix Pillar(?)

今回の発表は、主にIce Lake-SPベースのXeon ScalableがHPCの分野で競合(主にMilanベースのEPYC)より高い性能を発揮する、という主張がメインであるが、これに加えてStorageとInterconnectの分野での新発表も付け足しの様に行われた。
まずそのIce Lake-SPについて。Cascade Lake後継ということで、HPC分野のワークロードで平均53%の性能改善が実現した(Photo02)としている。
-

Photo02:比較対象は前世代製品ということでCascade LakeベースのXeon Platinum 8280と、Ice Lake-SPベースのXeon Platinum 8380の比較となっている。テスト結果の詳細はこちらの[108]

HPCの場合はScale Out的な構成になる事が普通なので、Cooper Lake系列のScale Up向け製品ではなく、2PのCascade Lake系列を使って構成されることが多く、これをIce Lake-SPに置き換えると大幅に性能が改善する、という訳だ。
実際、さまざまなアプリケーションで比較した場合、同じコア数で言えばSkylake-SPはMilanに比べてベンチマークの結果で平均23%高速である、としている(Photo03)。
-

Photo03:細かなテスト条件はこちらの[47]にあるが、予想通りXeon Platinum 8358はAVX512を有効にしており、EPYC 7543はAVX2を有効にした状態での比較である

また、AI Workloadに関してはoneAPIを利用して最適化を掛けることで、Cascade Lake比で10.3倍高速化される(Photo04)としている。
-

Photo04:細かなテスト条件はこちらの[52]。Tencent PRNet Modelを利用しての推論が4.23倍、Tencent TGW NGINX WebサーバへTLS 1.2を利用して接続する際のConnection/secの処理性能が5.13倍とされる。どこから10.3倍が出てきたのかは不明

このAIに関しては、End-to-Endの国勢調査デモを行った際の処理性能がEPYCに比較して20.7%高速、という結果も示されている(Photo05)。
-

Photo05:細かなテスト条件はこちらの[56]。これはoneAPIのサンプルの1つであるEnd-to-End Census Workloadを実施したものと思われる

すでにこのIce Lake-SPはHPCマーケットに多くのカスタマーおよびパートナーが存在する(Photo06)、というのがIce Lake-SPに関する〆の説明であった。
-

Photo06:ちなみに2021年6月版のTOP500リストのTop 10には1システムも入っていない。Milanの方はPerlmutterが5位入りしているのと対照的ではある

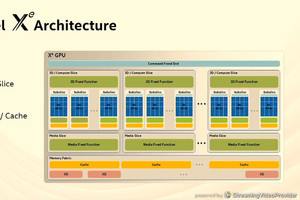
さて次はこれに続く話。まずGPUであるが、Ponte Vecchioはすでに最初のサンプルが稼働し、現在検証中であるとした。またXe HPはDevCloudですでにプログラムの開発が可能になっており、Xe HPGはすでににDG2のSamplingが始まっているとしている(Photo07)。
-

Photo07:一番上のPonte VecchioのチップはOAM(OCP Accelerator Module)に搭載される。AuroraはこのOAMを4つ搭載したSub-Systemを利用する、というあたりだろうか

ちなみにこのPonte Vecchioに関してはArchitectであるRaja Koduri氏が色々公開してくれており、全体はこんな感じになっており、全部で47のTileから構成されているという、ある意味お化けチップである。
これを最初に実装する予定であるANLのAurora、当初は2021年中に納入のはずであったが、肝心のPonte Vecchioは今Validationが行われているというのは、どう考えても2021年に納入は無理であって、来年中に納入が出来ればラッキー位に考えておくのが無難だろう。
そのPonte Vecchioとペアを成すCPUである第4世代Xeon ScalableであるSapphire Rapidsであるが、今回公式にHBM2メモリを搭載することが明らかになった。これは実は前からささやかれていた話であり、これが正式に確認されたという事になる。
もっともHBM2をメインメモリに、という話はあり得ない。現在のHBM2/HBM2だとStackあたり16GBが最大容量であり、16個積んでも256GBにしかならない。そもそもPhoto08にもあるようにSapphire RapidsはDDR5もサポートしており、こちらは規格上256GB/Moduleまでサポートする。まだ公式にはSapphire RapidsのMemory Channelは発表されていないが、Ice Lake同様に8chであれば16枚(2DIMM/channel)構成だとDRAMだけで4TBに達する。これに比べると明らかにHBM2は足りない。
-

Photo08:Sapphire Rapidsの概要

恐らくはキャンセルされたKnights Hill(こちらはMCDRAM+DDR4)と同様に、HBM2は複数のアクセスモードをサポートし、アプリケーションのニーズに応じてローカルキャッシュ、あるいはローカルストレージとして使うといった形になるのではないかと思われる。
さて、スライドはこの程度で終わりであるが、もう2つ。まず最初はPhoto01に出てきたDAOSの話である。DAOS(Distributed Asynchronous Object Storage)はIntelがHPC向けに開発している分散型オブジェクトデータべースで、先に出てきたAuroraでも利用される予定になっている。開発自体は以前から行われており、SC20でPengcheng LaboratoryのMADFS(Mobile Agent-based Distributed File System)が出て来てトップの座を明け渡したものの、最新のIO500のリストで3位にダブルスコアを付けている、割と実績のあるファイルシステムである。今回の発表はこのDAOSを商用サポートするという話で、HPE、Lenovo、Supermicro、Brightskies、Croit、Nettrix、Quanta、RSC Groupといった企業が商用提供を行うという話になっている。
さて最後がInterconnectの話。Photo01で“New High Performance Networking”とか書いてあるが、これはIntel Ethernet 800シリーズのネットワークカードと、Intelが2019年に買収したBarefoot Networkが提供していたTofino P4-Programmable Ethernet Switch ASIC、それとIntel Ethernet Fabric suite softwareをHPC向けにも提供する(名称はHPN:High Performance Networking with Ethernet solutionになるそうだ)という話で、ここまでは良い。問題はこのISC 2021に合わせてIntelがオンラインで展開しているHPC+AI Pavilionの方である。Fireside Chatsの中に“Cornelis Networks Omni-Path Express (OPX) Technology: The Future of Purpose Built High Performance Fabrics in a Converged HPC/AI World”なるセッションがあって、「OPXって何?」という事になる。
Intelは2019年7月に、第2世代Omni-Path Fabricの開発中止とOmni-Path Fabricそのものからの撤退を表明したが、このOmni-Path Fabricの開発を行っていたPhil Muyrphy氏(元々はQLogicでVP, Engineering兼VP, HPC TechnologyのポジションでInfiniBand関連製品の開発を手掛けていたが、IntelによるInfiniBand関連ビジネス買収に伴いIntelに移籍した)はそのOmni-Path Fabric関連資産をIntelから譲り受けた形で2020年3月にCornelis Networksというスタートアップを立ち上げ、ここでOmni-Path Expressという名称で既存のOmni-Path Fabricと互換性のあるネットワーク製品の提供を始める事にしたのだそうだ。ちなみにIntelとしては、このOPXは“Purpose Built, High Perfromance Fabrics in Converged HPC/AI World”と説明しており、(言い方は悪いが)既存のOmni-Path Fabricを引き続き使いたい顧客のサポートをCornelis Networksにブン投げた格好になる。
ちなみにCornelis Networksが現在提供中の製品はまだ第1世代、つまり100GbpsのOmni-Path Fabric互換製品となっており、今のところ200Gbps世代品は出て来ていない。ただ同社は昨年10月のSeries A1 Roundで、Intel Capital他から総額2050万ドルを調達しており、今年2月のSeries A2 RoundではNYのAdit Venturesと西海岸のRedgline Partners、さらに日本のGlobal Brainからも資金を調達した事が明らかになっている(調達額は不明)。これらの調達した資金で、恐らくは第2世代OPXが投入されるものと思われる。