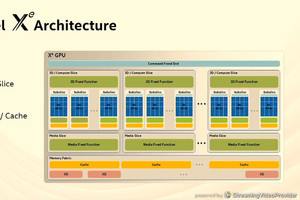
Lightmatterは、Hot Chips 32において、「Mars」と呼ぶAI推論用アクセラレータを発表した。
このアクセラレータがその他のAIアクセラレータと大きく異なるのは、中心となるAI計算が電子的に行われるのではなく、光で行われるという点である。
ただし、AI処理の中には光での計算に向いている処理と、光でやるよりも電子的に処理する方がやりやすい処理があり、Marsでは、前者の処理はシリコンフォトニックスチップで実行させ、後者の処理は通常のシリコンチップで行わせている。
-

Lightmatterのフォトニックにマトリクス計算を行うMarsアクセラレータボード。光で計算するので、計算は光速で、かつ消費電力が小さい (このレポートのすべての図は、LightmatterのCarl Ramey氏の発表スライドのスクリーンキャプチャである)

半導体素子の微細化に横たわる熱問題
1990年頃からトランジスタのスイッチエネルギーの低減のペースが鈍ってきている。常温で動作させる素子のスイッチエネルギーは常温の熱エネルギーより小さくはできないので、スイッチエネルギーには下限があり、これは微細化のスローダウンのだけのせいではない。
-

トランジスタのスイッチのエネルギーは微細化に伴い減少してきたが、1990年ころからは低減の速度が低下してきている。スイッチエネルギーは熱エネルギーよりは大きい必要があり、トランジスタのスイッチ効率が悪化するのはやむを得ない

スイッチのためのエネルギーが小さくならないで、素子の密度が高くなると、チップは熱くなる。その結果、熱のせいで全部のトランジスタを動作させられないDark Siliconの問題、クロック周波数を上げられないとか、特別なエキゾチックな冷却が必要となるという問題が出てくる。
1つのパッケージに入るチップの消費電力としては400W程度が実用的には限界と考えられる。
-

シリコンチップの発熱が大きくなると、全体を使えないダークシリコン、クロック周波数の飽和、エキゾチックな冷却などが必要になる

AIの増加する計算量を光で処理するメリット
次の図は、AIの計算量の推移を示すものであるが、AI計算の増加ペースはムーアの法則の5倍であり、エレクトロニクスでは、このペースについて行けない。
-

AIの計算量の増加はムーアの法則の5倍の速度で、エレクトロニクスでは追いつけない

光情報を処理するシストリックアレイは、データの伝送に必要となるエネルギーが小さくて済み、光を使うテンソルコアは電子回路より高速で動作し、小さいエネルギーで動作する。そして、光は波長多重や偏波多重という技術を使うと、1つの回路で多重度倍の並列処理を行うことができる。
電子回路の場合のレーテンシは100ns程度であるが、光を使えば100ps程度と1000倍のスピードで処理ができる。信号処理の速度も電子処理では2GHz程度であるが、光を使えば10倍の20GHz程度で処理ができる。消費電力も電子回路では回路当たり1mW程度であるが、光なら1μWで済む。それで、処理回路のチップ面積は同程度であり、フォトニクスでの処理には大きなメリットがある。
-

オプティカルなデータ伝送は少ないエネルギーで高速である。オプティカルなテンソルコアは動作クロックが高く、消費エネルギーも小さい。波長多重や偏波多重を使えば並列処理ができるなどのメリットがある

電気での信号伝送は信号線の寄生容量の充放電にエネルギーが必要で、エレクトロニクスでの信号伝送には数十Wの電力が必要になる。一方、光での伝送なら電子回路のような信号線のRCによる遅延は発生せず、伝送に必要なエネルギーも小さくて済む。
-

光でのデータ伝送はRCに起因する遅延も無く、低エネルギーで伝送ができる。