NTTレゾナントは4月24日、「gooラボ」にて、話し言葉に近い文章での検索やチャットボットなどの対話サービスに応用可能なAPIを公開すると発表した。
今回公開するAPIは、2つの文章を比較して意味の類似度を数値化する「テキストペア類似度」APIと、自然な文章から自動的にユーザーの属性情報などを抜き出す「スロット値抽出」APIの2つ。
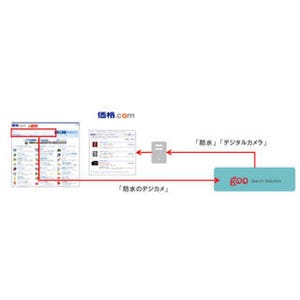
「テキストペア類似度」APIは、任意の2つの文章を比較して意味の類似度を数値化するAPI。たとえばFAQの検索において、「ユーザーからの質問文」とデータベース上のFAQ(質問・回答)にある「質問文」を比較し、類似度を示す数値が高い質問文とそれに紐付く「答え」をユーザーに提案するといった機能を持たせることが可能となる。
同APIは文書ベクトル化技術を活用しており、入力された2つの自然文の意味的な類似度を0~1間のスコアで出力。スコアは2つの文の類似度が高いほど1に近くなる。
-
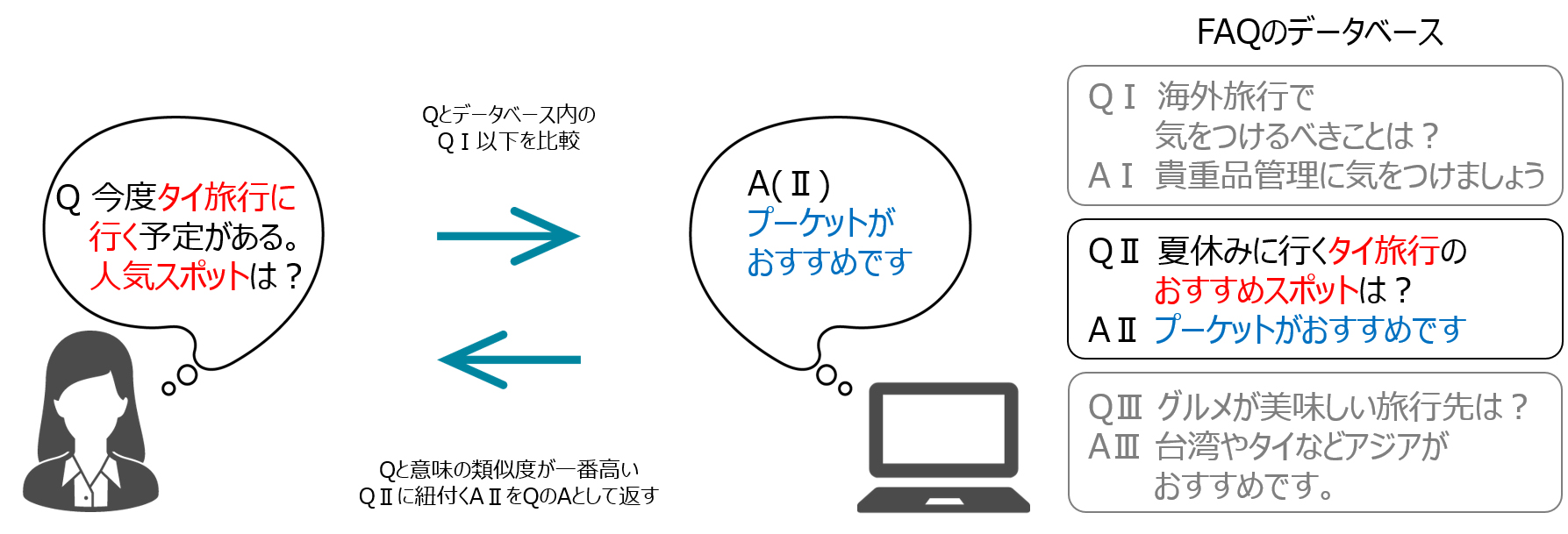
FAQ検索での活用イメージ

「スロット値抽出」APIは、自然な文章から自動的にユーザーの属性情報などを抜き出すAPI。これを活用することで、ユーザーとの自然な対話を行うチャットボットの開発のほか、音声認識システムとの組み合わせで、オペレーターの代わりに会話内容から氏名や生年月日を抽出し、本人確認を自動で行うコールセンターシステムの構築などが可能になる。
同APIはスロット値抽出技術を活用しており、あらかじめ定義した氏名(姓、名)・生年月日などの「基本的な情報」を、ユーザーとの会話など入力された文章から自動的に抽出するほか、それらの情報は企業名や顧客番号など、多様に定義することができる。
-

文章からの自動抽出イメージ