




日本語プログラミング言語「なでしこ」公式サイト
つい先頃(2017年12月)、国際標準化機構(ISO)により、文字コードの国際標準規格ISO/IEC 10646:2017が発行され、漢字など6万字が利用可能になったことで話題になりました。そこで、今回は、なでしこを使って文字コード表を作成し、自分の使っているコンピューターで、どんな文字が表示できるのかを確認してみましょう。
ISO/IEC 10646とは?
そもそも、ISO/IEC 10646(Universal Coded Character Set)というのは、世界中の主要な文字を一つの文字集合(文字セット)で表そうというものです。そのため、日本語だけでなく、中国語や韓国語、タイ語やチベット語など様々な言語で使われる文字、そして、記号や絵文字なども収録されています。
そして、このたび、ISO/IEC 10646:2017(第五版)では、285個の変体仮名、56個の絵文字なども追加されて、日本語の文字は6万字近く収録されることになりました。6万字あれば、特殊な地名や人名などで使われていた漢字もかなり網羅できます。
とは言え、ISO/IEC 10646:2017というのは、ただの規格であって、6万字の漢字をコンピューターの画面に表示するためには、規格に対応したフォントが必要となります。
残念なことに、この原稿を執筆している現在(2017年年末)には、この国際規格に対応したフォントは発表されていません。しかし、規格制定に尽力した情報処理推進機構(IPA)では、順次規格に対応したフォントを提供するとのことです。ちなみに、IPAが既に提供している「IPAmj明朝」というフォントには、6万字の文字が収録されています。このフォントはIPAのWebサイトよりダウンロードできます。
ASCIIコード表を作ろう
まず、基本的な文字コード表として、ASCIIコード表を表示してみましょう。1文字1バイトで表現できるASCIIコードの表です。以下をなでしこ3簡易エディタに入力して実行してみましょう。ここでは、文字コードの0x20から0x7Fまでを表示します。
0x20から0x7Fまでコード表生成してSに代入。# --- (*1)
Sを「#nako3_div_1」へDOM_HTML設定。# --- (*2)
●(NからMまで)コード表生成 # --- (*3)
S=「<table><tr><th>*</th>」
Iを0から15まで繰り返す# --- (*4) ヘッダ出力
H=HEX(I)
S=S&「<th>{H}</th>」
ここまで
S=S&「</tr>」
CをNからMまで繰り返す # --- (*5) 漢字を出力
もし、(C%16)=0ならば
S=S&"<tr><tr><th>" & HEX(C) & "</th>"
ここまで
S=S&"<td>" & HTML変換(CHR(C)) & "</td>"
もし、(C%16)=15ならば、S=S&"</tr>"
ここまで
S=S&"</table>"
Sをトリム
ここまで。
実行すると、以下のような表が表示されます。
-
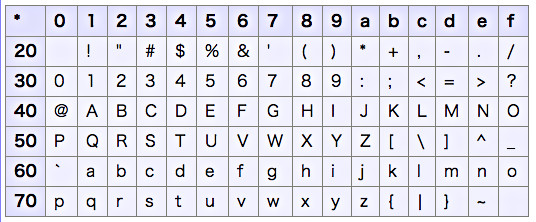
ASCIIコード表を出力したところ

プログラムを確認してみましょう。(*1)の部分では、0x20から7Fまでの範囲を指定して表を作成します。(*2)の部分では、表のHTMLを指定の場所に差し込みます。(*3)の部分では、表のヘッダ部分を作成し、(*4)の部分では、CHR命令を使って漢字を生成します。『繰り返す』構文を利用して繰り返し表を作ります。
ひらがなとカタカナの表を出力しよう
次に、ひらがなとカタカナの表を出力してみましょう。0x3040から0x30FFまでの表を作成すると、ひらがなとカタカナの表になります。先ほどのプログラムとの変更点は、プログラムの一行目だけです。一行目を以下のように書き換えましょう。
0x3040から0x30FFまでコード表生成してSに代入。
すると、以下のような表が生成されます。
-
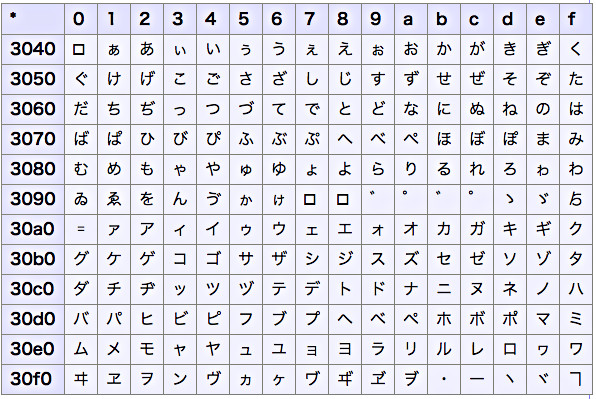
ひらがなとカタカナの表

CJK統合漢字の全範囲の表
続いて、Unicodeで0x4E00から0x9FCFの範囲で表される漢字(CJK統合漢字の全範囲)を表示してみましょう。プログラムの一行目を以下のように書き換えて実行してみましょう。ただし、このプログラムは大量の漢字を出力するので、環境によっては、実行にかなり時間がかかりますので注意してください。
0x4E00から0x9FCFまでコード表生成してSに代入。
以下のような表が表示されます。以下は、その一部分です。実際にはかなり長い表が作成されます。
-

CJK統合漢字の全範囲を表示

漢字領域には、これ以外にも、CJK統合漢字拡張A(3400~4DB5)、拡張B(20000~2A6D6)、拡張C(2A700~2B734)などがあります。
絵文字領域を表示してみよう
次に、漢字ではないですが、絵文字の一覧表を表示してみましょう。冒頭のプログラムの先頭二行を以下のように書き換えて実行してみてください。
0x2600から0x27BFまでコード表生成してS1に代入。
0x1F300から0x1F64Fまでコード表生成してS2に代入。
0x1F900から0x1F9FFまでコード表生成してS3に代入。
S1&S2&S3を「#nako3_div_1」へDOM_HTML設定。
実行すると以下のような表が出力されます。
-

絵文字一覧表を出力します

絵文字領域は表に出すとカラフルで面白いものですね。これらの絵文字を使いたい場合、普通の文字と同じように、表から絵文字をコピーして、テキストに貼り付けることが可能です。
まとめ
以上、今回は、文字コード表を出力するプログラムを作ってみました。出力するコードの範囲を書き換えることにより、さまざまなタイプの表を出力できました。どの範囲にどんな文字が収録されているか調べてみると、面白いのでいろいろ試してみてください。
自由型プログラマー。くじらはんどにて、プログラミングの楽しさを伝える活動をしている。代表作に、日本語プログラミング言語「なでしこ」 、テキスト音楽「サクラ」など。2001年オンラインソフト大賞入賞、2005年IPAスーパークリエイター認定、2010年 OSS貢献者章受賞。技術書も多く執筆している。










