
2022年の幕開けに、パーソナルコンピュータのハードウェア技術の動向を占う「PCテクノロジートレンド」をお届けする。まずは業界のあらゆる活動に大きな影響を及ぼす半導体プロセスの動向について紹介したい。
|
◆関連記事リンク (本稿) PCテクノロジートレンド 2022 - プロセス編 (2022年1月2日掲載) PCテクノロジートレンド 2022 - CPU編 (2022年1月3日掲載) PCテクノロジートレンド 2022 - GPU編 (2022年1月4日掲載) PCテクノロジートレンド 2022 - メモリ・DRAM編 (2022年1月5日掲載) PCテクノロジートレンド 2022 - Flash Storage編 (2022年1月6日掲載) PCテクノロジートレンド 2022 - チップセット編 |
|---|
***
皆様、あけましておめでとうございます。本年もよろしくお願いします。
2020~2021年はコロナに明け暮れた感もあるが、引き続きオミクロン株が猛威を振るっており、まだこの先の動向がどうなるかは判らない。もっとも企業としても、その辺りを勘案しながらビジネスを進めており、その意味ではコロナを気にしつつも製品は投入され続けているわけで、今年も色々動きがありそうである。という事で何時もの通り、今年の予測などを。まずはProcess関連の動きから(Photo01)。
-

Photo01: 今年は預かり猫シリーズ(里子に出した連中)で行こうかと。トップバッターは2003年にやってきた3猫。へその緒が付いた状態で来襲、離乳のタイミングで元々3匹を保護をした友人宅に戻っていった。

TSMC(Photo01)
ご存じの通り現時点では業界最大かつ業界最先端の製造能力を持つTSMC。PC業界で言ってもIntel、AMD、NVIDIA(PC向けはまだSamsung:HPC向けがTSMC)がTSMCに委託または委託予定、というあたりで何をかいわんやである。
2021年は熊本に新工場を作るという話になっているが、こちらは産業向けがメインとなる28/22nmノードである。ただそれ以前にアリゾナに新Fab(Fab 24)を建設予定であり、しかも当初はMegaFab(ウェハ生産量が300mm換算で月産25000枚程度)という話だったのが、いつの間にかそれが6棟に増え、GigaFab(同月産10万枚以上)に昇格しているという騒ぎである。またここに後工程工場を追加するという報道も出てきており、これが実現するとちょっとした規模の生産拠点となる。
といっても、TSMCは既に台湾にGigaFabを5つ(Fab 3/6/12/15/18)持っており、今後Fab 18の増強(Phase 3~6:2022年中に稼働)とFab 20(2024~2025年に稼働予定)が予定されているから、メインは引き続き台湾ということになる。なおFab 24の稼働予定は2024年という話なので、少なくとも現時点では考慮しても仕方ないところである。
なお先端プロセスに関しては、7nm世代がFab 15、5nmがFab 18のPhase 1~3、3nmがFab 18 Phase 4~6(7もある、という話も出ている)、2nmがFab 20の予定である。Fab 21は5nmという話だが、ひょっとすると3nmになるかもしれない。
さてそのTSMCであるが、更にプロセスが複雑化している。一覧で示すと
N7 : TSMCの最初の7nmプロセス。ArF液浸+マルチパターニング。TSMCによれば昨年7月の時点で既に10億個のN7ベースのチップが出荷されたとしている。
N7P : N7の性能向上型。N7とプロセス互換性があるため、N7の設計そのままで移行可能。ArF液浸+マルチパターニング。AppleがA13でN7Pを採用したが、性能向上率はN7比で7%(もしくは同一性能で10%の消費電力減)とそれほど大きくない。
N7+ : N7の製造プロセスの一部(トランジスタ層と一部の配線層)をEUV露光に切り替えたもの。N7と設計の互換性がないので、N7からそのままの移行はできない。そのあたりもあって、あまり多くのチップでは採用されていない。
N6 : N7の一部をEUV化したという意味ではN7+に近いが、N7+との最大の違いはN7と設計の互換性があること。N7あるいはN7Pを利用していたデザインはそのままN6に移行可能とされる。またN7+よりEUV露光を使う配線層が1層多い。2020年から量産を開始しており、2021年末では7nm世代の凡そ半分がこのN6に移行している。
N5 : 7nm世代とは全く互換性の無い新ノード。露光はEUV。こちらも2020年から量産を開始しており、現時点では最新のプロセスノードとなっている。
N4 : 2021年中にRisk Productionがスタートしており、2022年中に量産をスタートする予定だが、意図的にかどうかは知らないが性能などについては語られていない。ただ後述するN4Pの数値から算出すると、N4はN5比で4.7%の性能向上が期待できるとなり、大きくは上がらないといったところか。またN5比でマスクを幾つか減らせる、と説明されているのでおそらくはより配線層へのEUV適用が進んだものと思われる。また設計ルールやSpice(動作のアナログシミュレーション)、IPの互換性を保つと説明されている。ここから見るに、設計そのものは若干の手直しが必要で、N5向けに設計したチップをそのままN4に持ってゆく訳には行かないようだ。またトランジスタ密度そのものはN5と同等と思われる。
N4P : 2021年10月に発表された、N4の改良版。N5と比較して性能を11%改善できるほか、消費電力効率とトランジスタ密度をそれぞれ22%/6%向上させられると説明されている。ちなみにN4比では性能が6%改善となっている。設計そのものはN5/N4と互換性は無いが、容易に移行可能と説明されており、最初のN4PのTape outは2022年後半と説明されている。ということは量産シリコンが出てくるのは早くても2023年前半期と予想される。
N4X : 2021年12月に発表されたN4Pの高性能特化版。N4PはHPCからMobileまで、つまり高性能寄りにも低消費電力寄りにも出来る汎用向けプロセスであったが、N4XはHPCに特化する、つまり性能を上げる事を目的としたカスタム版である。具体的にはCPUとかGPU、それとCloud AI向けプロセッサなどで利用される形で、Mobile向けSoCでの採用は無いだろう(Apple M2以降での採用は微妙なところだが)。そのN4X、1.2V動作の場合にN5比で15%、N4P比でも4%の性能向上が期待でき、1.2Vを超える電圧だと更に性能向上が得られると説明している。またN4XはN5と同じデザインルールでの設計が可能である。つまりN5を使って製造されたCPUとかGPUのプロセスアップグレードパス、として提供される模様だ。もっともその分消費電力はかなりひどいことになりそうだし、トランジスタ密度向上は期待でき無そうである。このN4X、2023年前半にRisk Production開始とされているので、量産開始は早くても2023年末、現実問題としては2024年になりそうである。
N3 : こちらもN7→N5と同様に、5nm世代とは全く互換性の無いノードである。そしてTSMCはSamsungと異なり、この世代でもトランジスタ構造はFinFETのままである。さて、このN3であるが当初発表ではN5比でトランジスタ密度が1.7倍、性能向上が10~15%の予定とされていた。ところが2021年10月に行われたTSMC 2021 Online Open Innovation Platform Ecosystem Forumにおける説明では、トランジスタ密度が1.6倍、性能向上が11%となり、その代わり消費電力は27%削減と説明されている(Photo02)。またこのN3にはHPC向けの構成であるN3 HPCと、更にこれに対してDTCO(Design Technology Co-Optimization:設計・製造協調最適化)を施したN3 HPC+DTCOの場合の性能も示されており、例えば0.9V動作ならN3と比較しても最大12%高速化できるとしている(Photo03)。
-
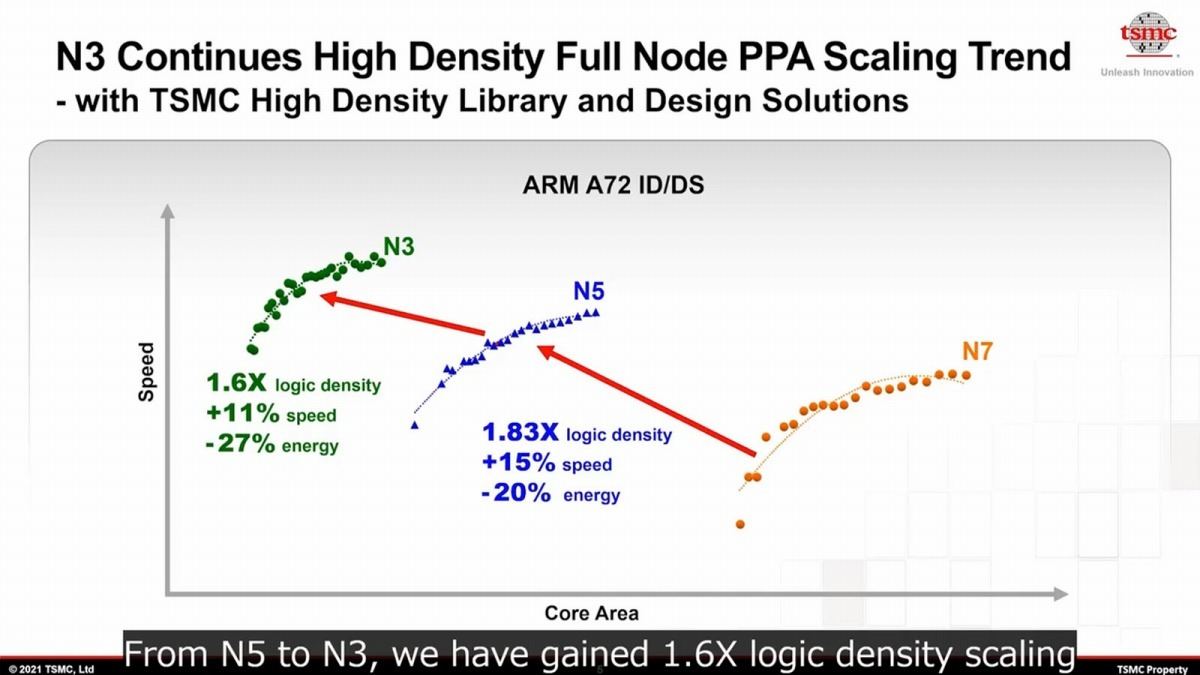
Photo03: 横軸が性能、縦軸が消費電力である。ちなみに、N5とN3の0.9Vの消費電力はほぼ同じだが、N3+DTCOでは結構引きあがっている事に注意。

-
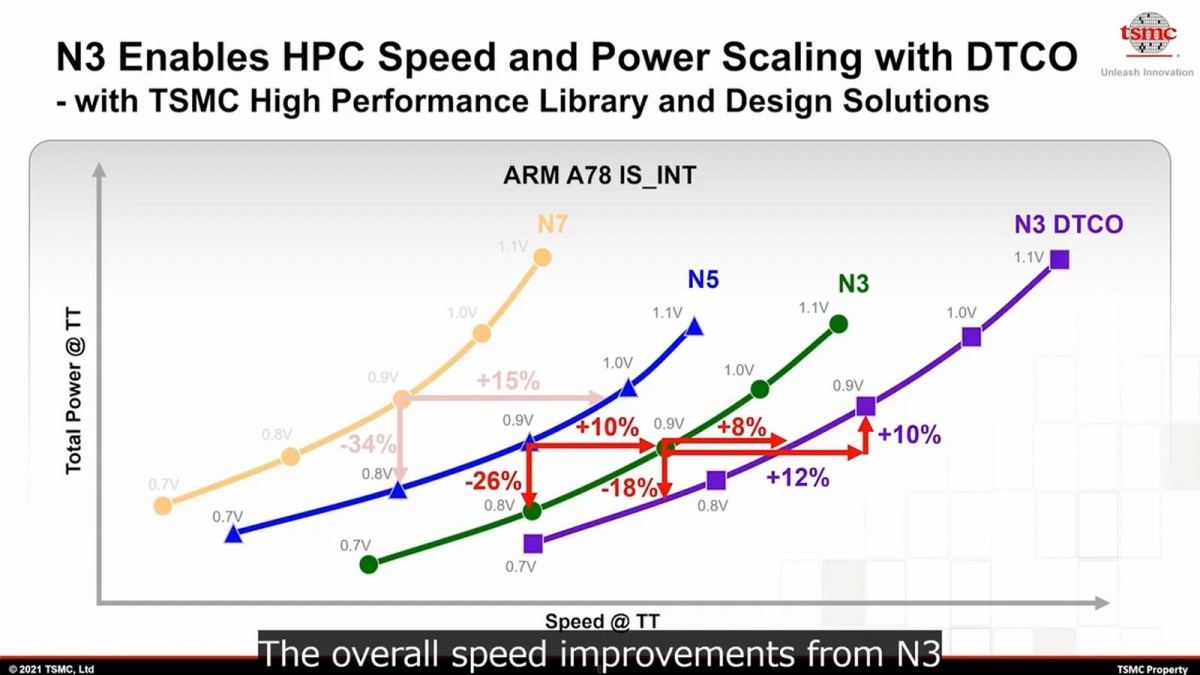
Photo03: 横軸が性能、縦軸が消費電力である。ちなみに、N5とN3の0.9Vの消費電力はほぼ同じだが、N3+DTCOでは結構引きあがっている事に注意。

このN3、こちらでも触れられているが、2021年中にRisk Productionがスタートしており、2022年第2四半期あたりに量産がスタートする、とされている。ただなにしろ当初はそれほどスループットが高くない(なにしろ生産拠点であるFab 18 Phase 4~6は現時点ではまだ完成しておらず、完成して製造設備がフル稼働状態になるまでには軽く1年は掛かるだろう)と予測され、しかも当初はほぼ全量Appleが持ってゆく。なので、Apple「以外」の量産に入るのは2023年以降になると予測される。なので2023~2024年はN5/N4P/N4X/N3が入り乱れる格好で量産が行われることになりそうだ。このN3もまた奪い合いになりそうではある。
N2 : TSMC初のGAAを利用するノードである。こちらは2024年以降の量産開始(当初は2025年という話だったが、これを前倒ししているという話も出ている)なので、Risk Productionは早くても2023年後半とかになるだろう。こちらに関してはまだ「やる」という以上の情報が出てきていないのが正直なところである。
といった具合になっている。また、今のところは一切情報は無いが、過去の経緯で考えるとN3とN2の間にもう一つ二つ、プロセスが挟まっても不思議ではない。N3PなりN3Xなりが後追いで追加され、2023年後半~2024年に量産開始、という事になりそうな気もする。
さてこのTSMCのプロセス、スマートフォン向けSoCやAIプロセッサ向けに奪い合いが始まっている訳だが、当然PC向けにも奪い合いが始まっている。詳しくは後述するが、比較的確実と見られているだけで
- N6: Intel Alchemist、AMD Navi 24、AMD Zen 4 IOD、AMD CDNA 2.0
- N5: AMD Navi 31?、NVIDIA GA200?、AMD Zen 4 CCD、Intel Alder Lake
- N3: AMD Zen 5 CCD、Intel Raptor Lake CPU、NVIDIA GA300?
辺りがぱっと出てきて、恐らく今後は更に増えるだろう。
またTSMCはPackagingに関してもやはり進んでいる。Photo04が現在TSMCが提供しているPackaging技術の一覧である。
-

Photo04: InFOは今のところPC向けの適用は無いが、今後Chromebook向けとかには採用される可能性がある。

ここで、
CoWoS: いわゆる2.5D Stackingで、HBM/HBM2/HBM2E/HBM3などの接続は今のところこれに頼る必要があるし、GPUだけでなくAIチップや一部CPUにも利用されている(富士通のA64fxなど)。基本となるのがCoWoS-Sで、これはすべてのチップを搭載するのに必要な、大型のSilicon Substrateを製造し、この上にチップを載せる構造である。ただチップの大型化に伴い、全てのチップを載せきれるSilicon Interposerを製造するのが難しくなってきた。Radeon Instinct MI200がその代表例で、XCUのダイが735.4平方mmほど×2、HBM2Eが109.5平方mm×8で、合計で2346.8平方mm。なのでパッケージ全体では軽く3000平方mmほどになる。Silicon Interposerは、通常のチップと同じく露光→エッチングという工程で製造されるから、どんなに頑張ても800平方mmほどが寸法の上限であり、なので全体をまとめてカバーするInterposerを製造するのは、少なくともSiliconベースでは不可能である(TSMCは第二世代のCoWoS-2では、露光サイズを1.5倍に引き上げるテクニックを導入した事で最大1200平方mmまで可能とはなったが、それでもRadeon Instinct MI200には全然足りない)。
そこでSilicon Interposer(CoWoS-S)に替え、低損失の有機基板を利用したCoWoS-Rがラインナップされた(Photo05)。こちらはSilicon Interposerに比べると損失が多いといった欠点はあり、なので信号速度の上限などは低くなるが、その代わり3000平方mmの巨大なInterposerも製造可能になる、いわば低コストのソリューションである。
-
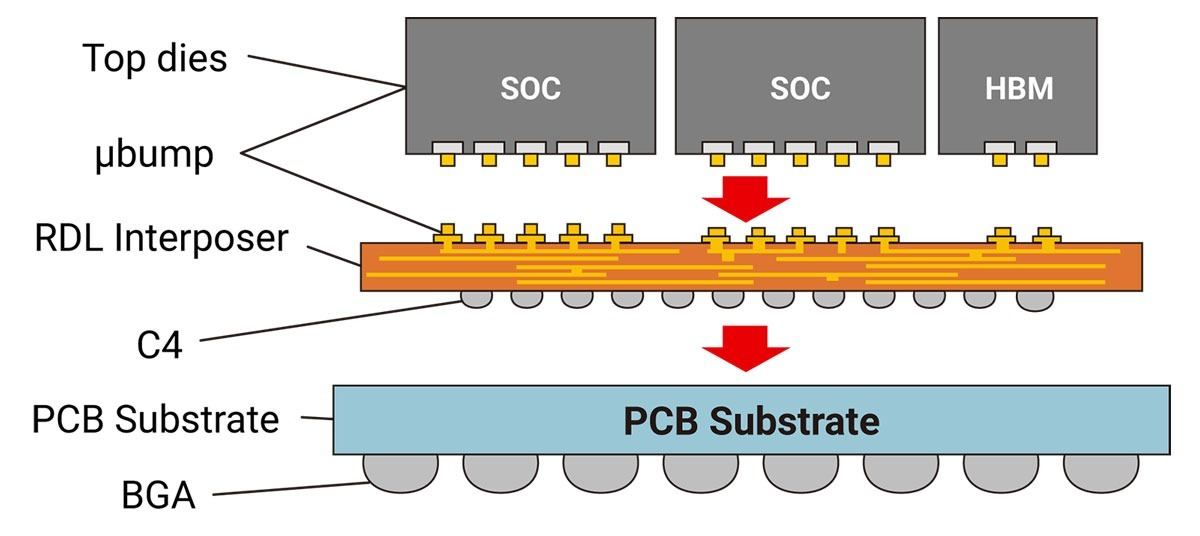
Photo05: CoWoS-RのRDL Interposerは6層基板構成になっている。

第3のSolutionがCoWoS-Lである。Local Si Interconnetと呼ばれる方式で、要するにチップ全体をカバーするのでなく、チップ間Interconnectが必要な個所だけにSilicon Interposerを充て、他の箇所はRDLでカバーするというやり方だ。これを応用したのがAMDがRadeon Instinct MI200で採用したElevated Fanout Bridgeである。AMDはRDL層の代わりにCu Pillerを立ててパッケージと直結する、という形にしているが、まぁ方法論としては一緒である。
-
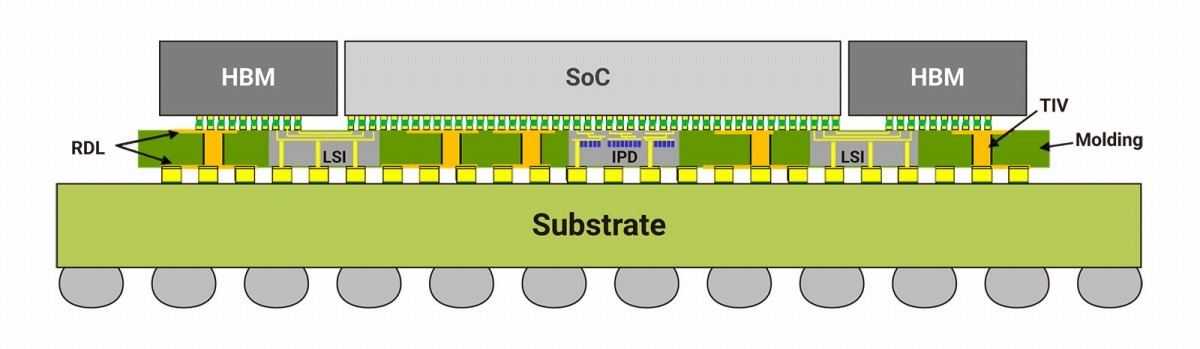
Photo06: この例ではSoCとHBMの間にLSIが入り、その他の場所には普通のRDLが入る形。SoC真下のIPDはIntegrated Passive Deviceの意味で、要するにパスコンなどが配される格好。

InFO: 主にMobile SoCに多用されている方式。要するにSoCの周囲にCu Pillerを立てて、SoCの上にDRAMを積層する(Photo07)という方式である。勿論DRAMでなくSoCを実装する事も可能であり、実際に3層とか4層構造の例もある。こちらも、途中のInterposerをSiliconベースにするか有機基板ベースにするかでINFO-LかInFo-Rかに分かれるが、構造としては同じだ。また、特にMobile向けの場合、4Gとか5Gのモデムを集積する場合があり、ノイズ対策などからこれを立体ではなく平面置きにしたいというニーズがあったことから、InFOをベースにチップを平面置きとしたInFO-oSという派生型もあるが、PC向けではそこまで統合されることは無い(5Gモデムは大体PCIe M.2モジュールの形でシステム実装であり、CPUに統合されたりはしない)ので、ここでは割愛する。
-
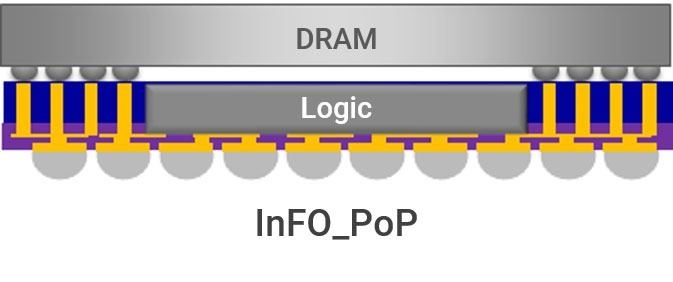
Photo07: この図ではDRAMの信号ピンが左右に寄っている様に見えるが、実際にはDRAMの真裏にくまなくピン(というか、ball)が出ているので、DRAMとPillerの間にもInterposerを挟むことが多い。

SoIC: 真の3次元実装。SoICの詳細は昨年ここで詳細に説明したので、今回は割愛する。最初の実装はAMDの3D V-Cacheである。ちなみにSoICには、その3D V-Cacheに採用されたSoIC-CoW(Chip on Wafer)以外に、ウェハのレベルでStackingを行うSoIC-WoW(Wafer on Wafer)という技術もあるとされているが、今のところ適用された事例を聞かない。今年あたり、AIチップ向けなどで出てくるのだろうか?
-
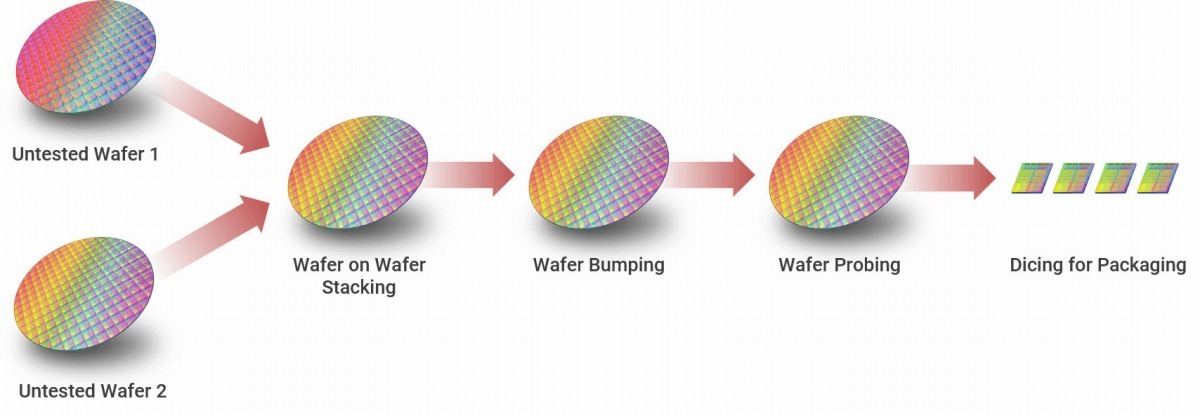
Photo08: 単にDicing(チップをWaferから切り出し)してから重ねるか、Dicing前に重ね合わせて切り出すかの違い。重ね合わせの手間がコスト増加要因になるので、SoIC-WoWにすればコストは減ることになる。ただこの場合上側と下側のチップの面積が当然同一になる訳で、3D-Vcacheの様に大きなダイの上に小さなダイを重ねる場合には向かない。

そんなわけで2022年もTSMCは大忙しである。AMDはZen 4とCDNA 2、後半にはNavi 30シリーズを投入してくるだろうし、IntelもAlchemistに加え、Alder LakeのLow end SKUをここに移すという話がある。NVIDIAもGeForce RTX 4000シリーズをTSMCの5nmにするらしいし、現在のGA100(NVIDIA A100シリーズ)の後継をTSMCに委託したいようだ。PC業界にとっては、TSMCの重要度が更に増す1年になりそうである。








