
Samsung(Photo09)
-

Photo09: この写真を撮った数日後に里親さんのところに移動。その後黒白(左)は見事なナルシストに、キジ白(右)は立派な大福もちに、キジトラ(中央)はすてきなお姫様に、それぞれ成長しました。

TSMCに比べるとPC業界ではやや影が薄い(現状はNVIDIAのGeForce RTX 3000シリーズのみ)Samsungであるが、2022年は適用範囲がグンと増える予定だ。最大の理由はTSMCがOver Capacityだから、という話である。後述の様にIntelのFoundry Serviceが立ち上がるまでにはもう少し時間が掛かる以上、現時点で選択可能なのはTSMCかSamsungしかないからだ。
そのSamsungであるが、既に4nm世代までの量産に入っており、いよいよ今年はGAA(Gate All Around)を採用した3GAAの量産がスタートする(Photo10)。ということで、まずはSamsungのラインナップを改めてご紹介するとこんな感じになる(Photo11)。
-
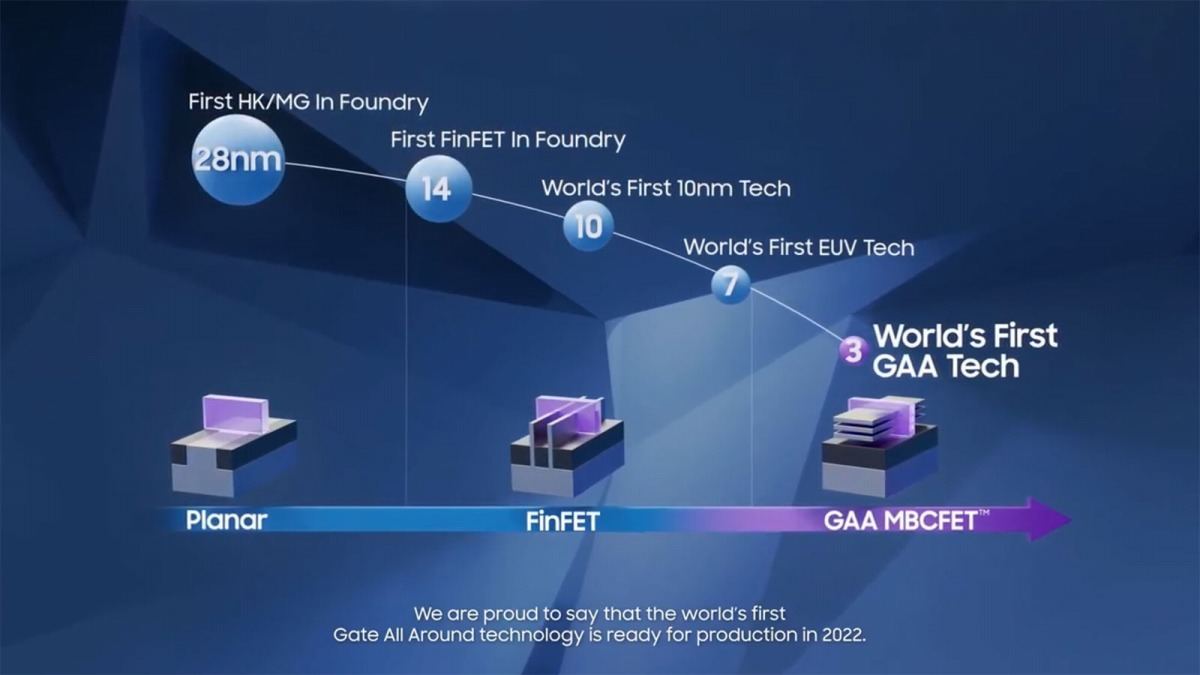
Photo10: 大まかなSamsungのロードマップ。とりあえずSamsungがGAA一番乗りは間違いなさそうだ。

-
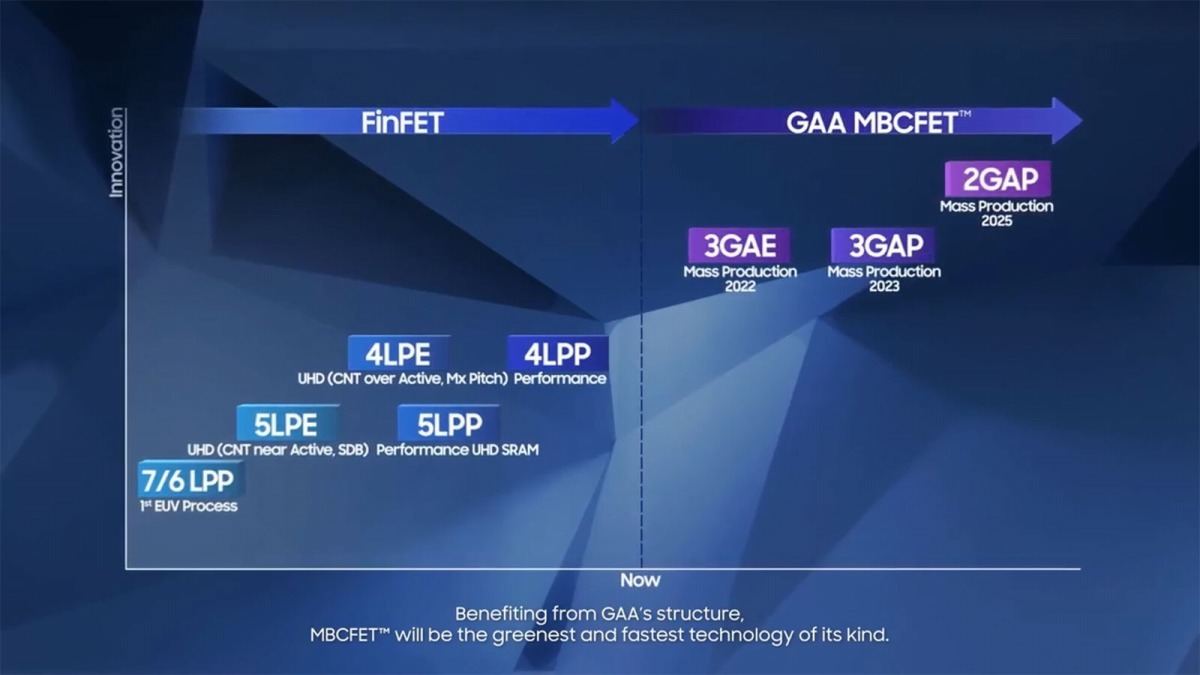
Photo11: 詳細ロードマップ。3GAPと2GAPの間がちょっと空くあたり、間に何か追加される可能性もある。

順に説明すると
7LPP(7nm Low Power Plus) : 7nm世代の基本。EUV露光を利用する最初のプロセス。既に量産中。
6LPP(6nm Low Power Plus) : 7LPPの改良版。SDB(Single Diffusion Block)を利用する事でトランジスタ密度を向上させている。また7LPPと比較して消費電力効率を向上させているという説明であった。ただ性能に関しては変わらない模様。
5LPE(5nm Low Power Early) : 6LPPをベースにしながら、性能向上(7LPP比で11%)とエリアサイズ削減(同30%)、消費電力削減(同20%)を実現したもの。もっともエリアサイズに関しては(以前ここでも説明したが)Cell Libraryの変更(7.5T→6T)とかCNT near Active Gateなどが搭載される。このCNT(Contact) near Active Gateとは、トランジスタ層とその上の配線層への接続(Contact)を、回路のすぐそばに置くことでエリアサイズを縮小する技術。これを更に進めたのが次の4LPEで採用されるCNT over Active Gate(回路の真上にContactを配する)で、更にエリアサイズが小さくなる。IntelだとこれをCOAGと呼んでいるが、そもそもIntelの10nmが立ち上がらなかった理由の一つがこのCOAGの実装が大変だった、という話でもある。SamsungはいきなりCOAGをぶっこむのではなく、5nmではゲートとContactの位置を非常に接近させ、4nmでやっとCOAGを実装した格好だ。このあたりの慎重さは、TSMCに通じるものがある。
5LPP(5nm Low Power Plus) : 5LPEの高速版とされるが、どの程度性能が上がったのか今一つはっきりしない。一応Samsungによれば、より低い電圧でより動作周波数が引き上げられる、としている(Photo12)。QualcommがSnapdragon 888をこのSamsung 5LPPで製造を行っている。またにUHD SRAM(高密度SRAM)も利用可能になっており、大容量L3などの実装が容易になったようだ。
-

Photo12: 横軸が電圧、縦軸が動作周波数であるが、数字も目盛りもないので実際に何%程度向上しているのかがいまいち判断できない。

4LPE(4nm Low Power Early) : 5LPEの高密度版とでもいうべきもの。上で説明したCOAGのほか、メタルピッチの縮小でエリアサイズ縮小に伴うトランジスタ数増加を狙ったもの。AMDがこの4LPEを利用してAPUを製造するという話も出ており、もし実現すると2022年後半に市場投入の可能性がある。
4LPP(4nm Low Power Plus) : 4LPEの高速版。具体的に何をどうやって高速化するかとか、どの程度高速化されるのかといった数字が出てこないので何とも言いにくいものではあるが。ただSamsungとしては最後のFinFETプロセスである。ちなみに以前の記事では4LPPは2022年に量産スタートという話であったが、このスライドが示されたSamsung Foundry Forum 2021(2021年10月開催)の段階では既に4LPPがAvailableになっているというのは、少し予定が前倒しになったのかもしれない。
3GAE(3nm GAA Early) : GAAというかMBCFETの最初のプロセス。以前のロードマップでは4nm世代でGAAを利用する予定であったが、その後3nmに移行したという話はこちらで触れている。昨年のロードマップでも触れたが、そのGAEを当初は2021年中に投入という話だったのが少し後退している。加えて言うと、この3GAE、プロセスとしては存在するが、これを顧客向けに本当に提供するのかはちょっと疑わしい。というのは社内での評価用に製造は行うが、顧客向けには次の3GAPから提供という話が出ているためである。GAAという前例のない構造であり、競合であるTSMCやIntelは2024~2025年にGAAを導入となっているから、3GAEをスキップしても、次の3GAAが2023年から出れば十分競争力があると言える。
3GAP(3nm GAA Plus) : というわけで最初のGAA量産プロセスではないかと言われているのがこの3GAP。性能などについては後述する。
2GAP(2nm GAA Plus) : 今回初登場のプロセスである。丁度Intel 18Aと同じタイミングであるが、こちらの詳細は不明である。
といった感じになっている。
さて、3GAE/3GAPについてもう少し紹介したい。そもそもGAAの構造は例えばこちらに示すように、チャネルの周囲を完全にGateで覆い被せる(というか、Gateの壁をチャネルが貫通する)ような構造にすることでリークを減らし、スイッチング速度を引き上げようというものだ。MBCFETもGAAFETもその意味では間違いなくGAAの一種で、違いはチャネルがナノワイヤかナノシートかの違いしかない。ちなみにSamsungだけでなく、Intel 20Aもやはりナノシートを積層する構造になっており、これが一般的になりそうである(TSMCはまだN2の詳細を公開していないので不明)。
まずGAAのメリットである。FinFETの場合、Finの数を増やして駆動電流を上げるが、その割に性能が上がりにくい(Photo13)。これに対し、GAA(というかMBCFET)の場合、シートの数にほぼ比例する様に動作周波数が上がるとする(Photo14)。またチャネルの抵抗も、GAAにすることで減らすことが可能になるとしている(Photo15)。またここには書かれていないが、FinFETの場合Finの数を増やす事になるから、その分トランジスタの横幅が増え、つまりエリアサイズが大きくなる。ところがGAAだと縦方向に積み上げられるから、いくら積んでも底面積は増えない。つまり高密度の実装が可能になる事もメリットの一つである。
-
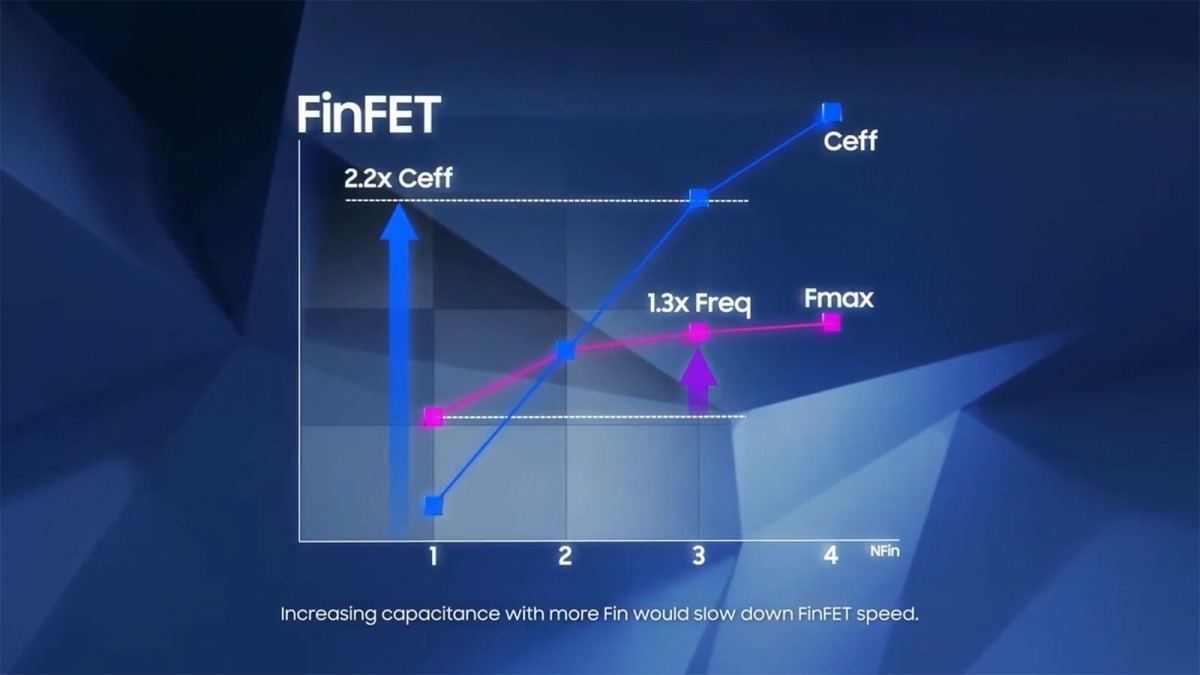
Photo13: Finを3枚に増やすと駆動電流は2.2倍になるが、動作周波数は1.3倍にしかならない。

-
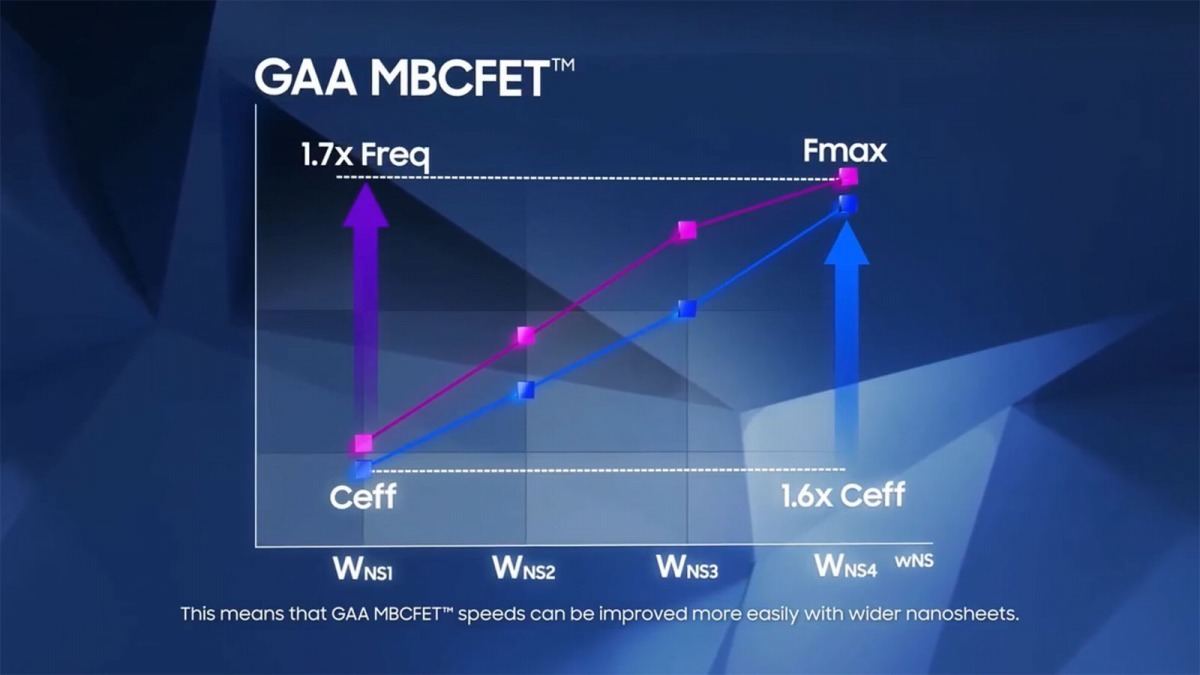
Photo14: シートを4枚にすると駆動電流は1.6倍に、動作周波数は1.7倍に向上するとする。

-
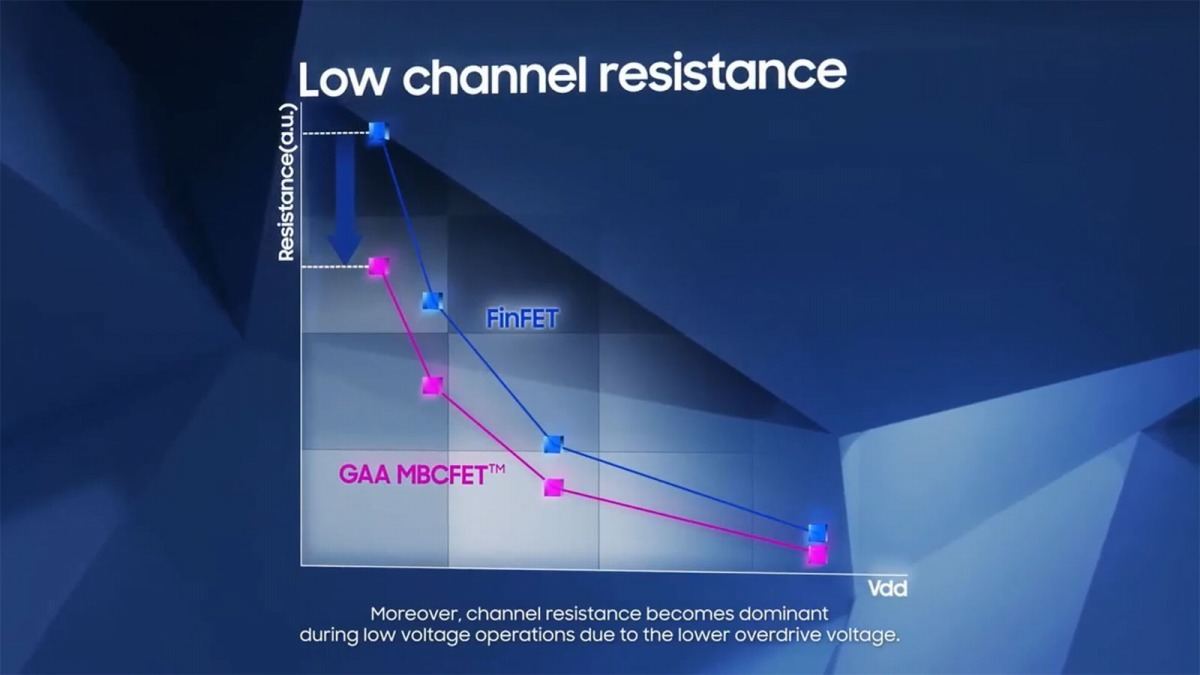
Photo15: 当たり前であるが、これはオン抵抗値の話である。

ここからは実際のプロセスの話(おそらく3GAEのものだろう)だが、まずSpeed Yieldは順調に上がっているとしており(Photo16)、またYueldそのものも順調に上がっている(Photo17)としている。実際に量産に入るにはまだ時間が掛かるだろうが、今のところは2023年の量産サービス提供に向けて順調であることをアピールした。
-
Photo16: 予定を上回るSpeed Yieldを実現できているとしている。予定ならそろそろ目標のSpeed Yieldを実現できている「筈」。

-
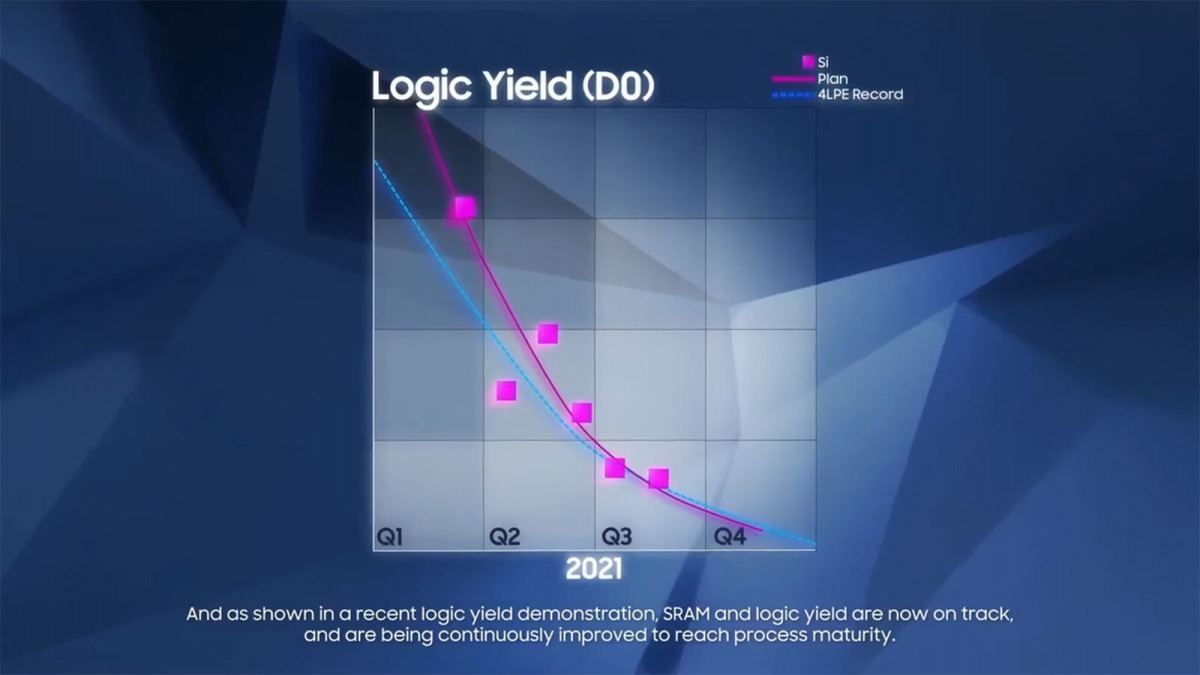
Photo17: 4LPEに比べても悪くないペースでDefectが減っている、とする。

ちなみにその次の2GAPであるが、Logic Densityはそこそこの向上で、ただし性能(というか、トランジスタの駆動電流)を大きく引き上げる方向に舵を切っている様だ(Photo18)。ちなみにPhoto19を見ると、まるでシートの数を1枚増やした(3GAPはナノシートが3枚までの様だ)のが2GAPの様に見えるが、実際にはシートの寸法も小型化されているものと思われる。
-

Photo18: もう昨今ではLogic Densityに関してはトランジスタよりもむしろ配線層の構成が支配的になっているので、そうそう引き上げるのは難しいとは思うが、それでも4LPE→3GAAの時と同程度には向上する見込みとされる。

-
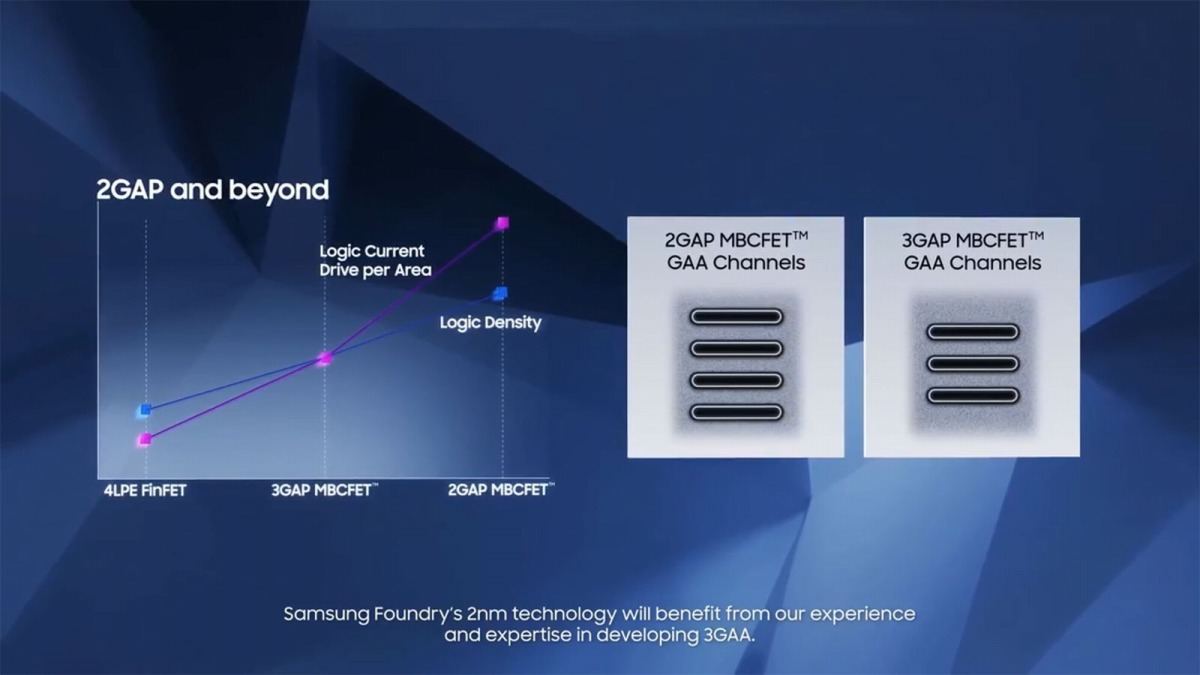
Photo19: なんというか、Photo18以上の情報が何もないスライドである。

ついでにPackagingに関してもご紹介しておきたい。TSMC及びIntelに比べると、正直言って現状のSamsungのラインナップはちょっと遅れをとっている。既に3D Stacking Solutionを提供しているといってもそれはチップ内部に留まっており(Photo21)、複数チップの統合に関してはSilicon Interposerベースの2.5Dに留まっている(Photo22)。ただ今後搭載できるHBMの数を2022年末には8つまで増やすとしている。もっと長期的に言えば、Samsungも当然3D Stackingの方向を示しており(Photo23)、まず最初に現在のX-Cubeをベースに、丁度TSMCのInFO的な3D Stacking Solutionを開発中としている(Photo24)。
-
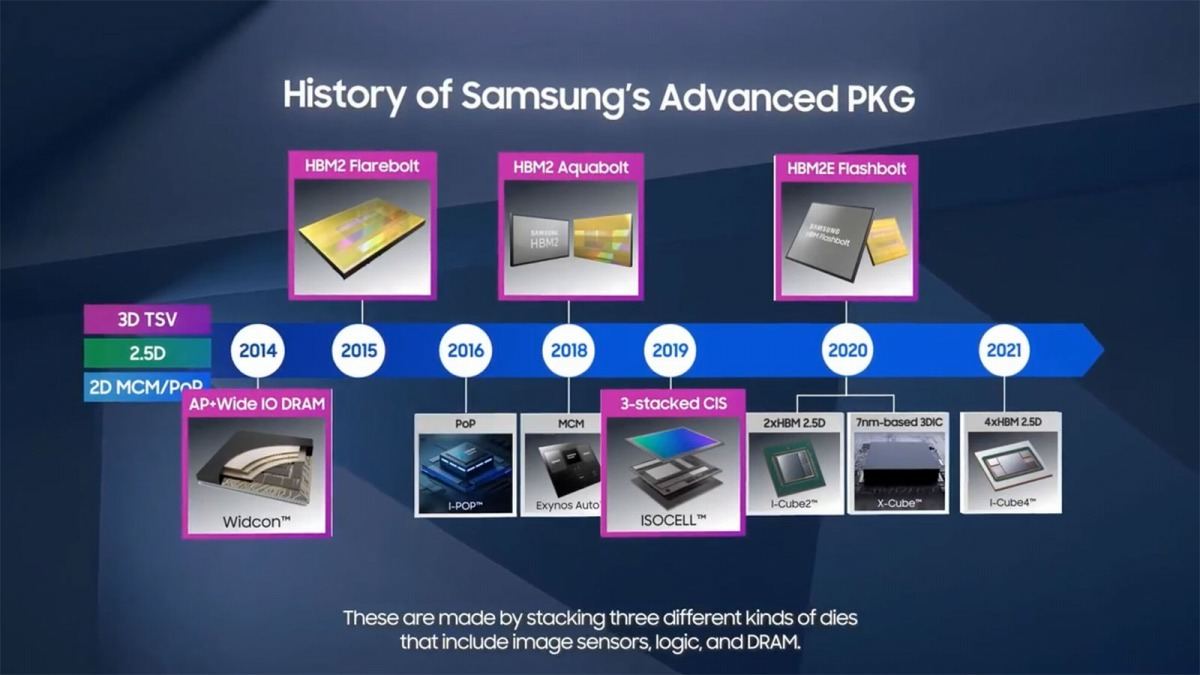
Photo20: ISOCELLは同社のCMOSイメージセンサで背面透過型センサーにISPを組み合わせたもの。HBM2は内部でTSVを使って積層しているという話である。

-
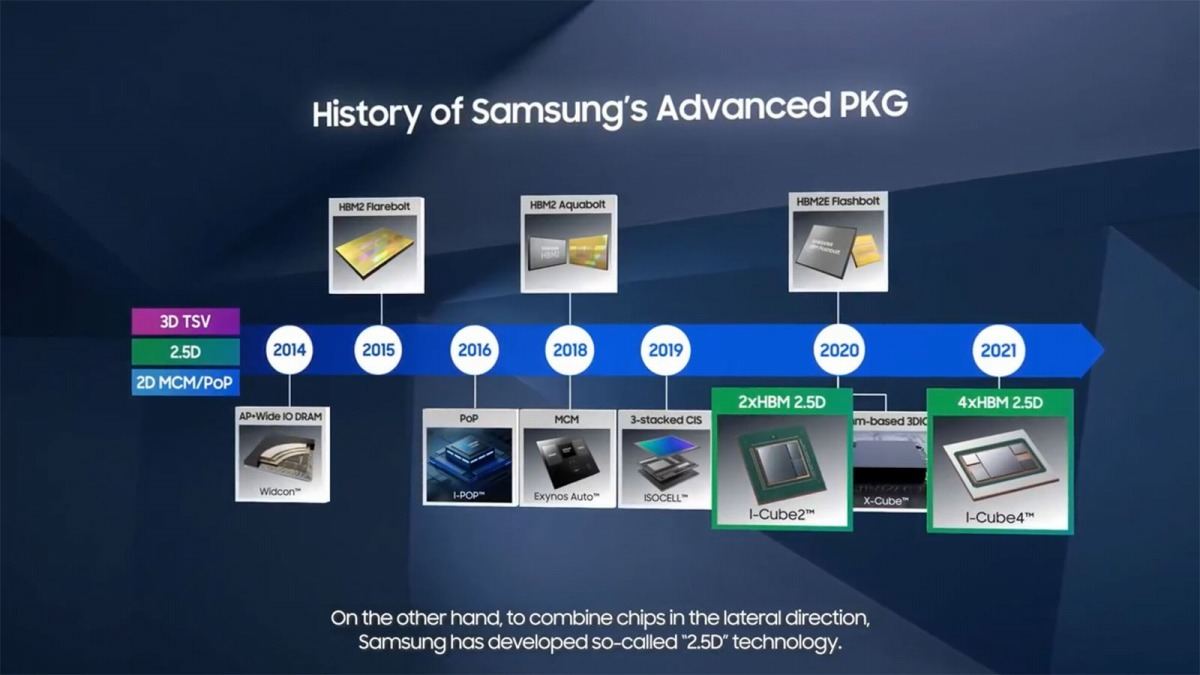
Photo21: 当初はHBMが2つのI-Cube 2のみで、昨年4つ搭載できるI-Cube 4が量産に入った。

-
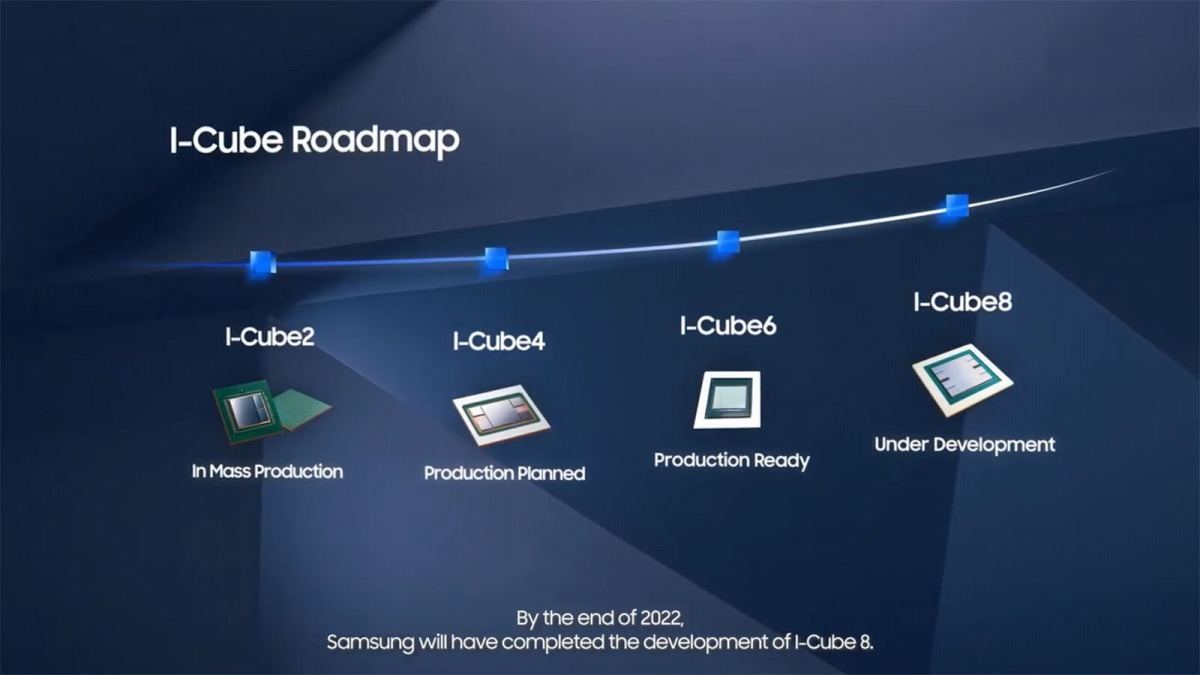
Photo22: I-Cube 6は量産準備は出来ているが、顧客がついていない。I-Cube 4はこれを利用した製品を設計中という話。

-
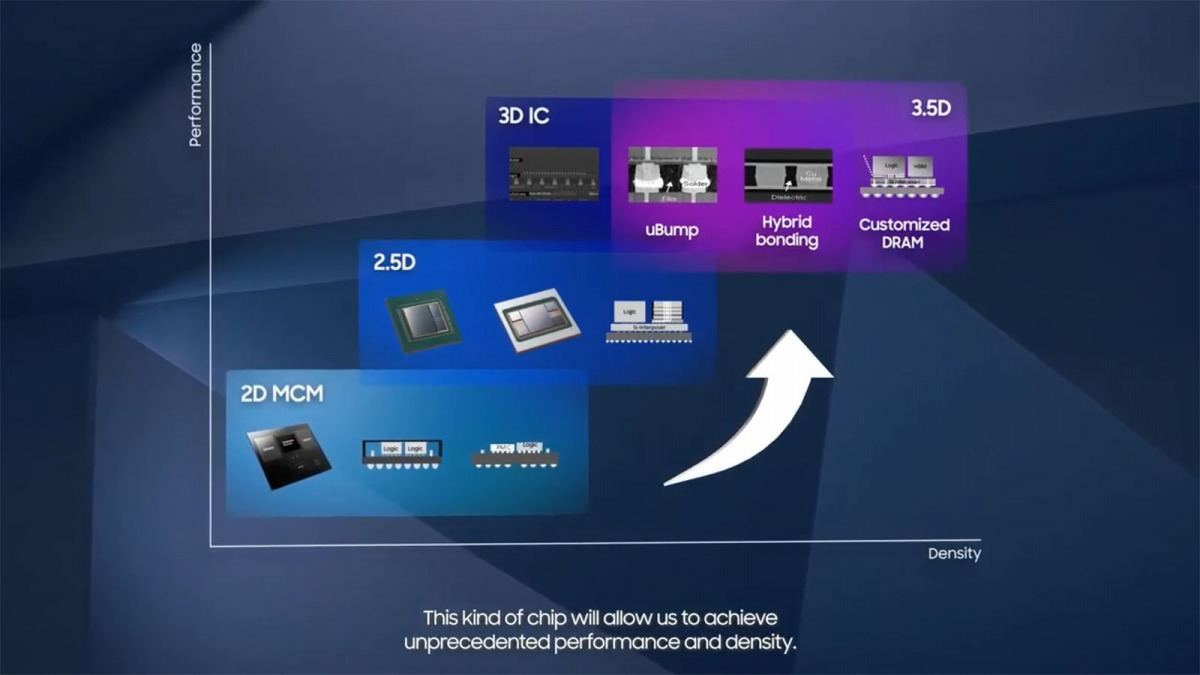
Photo23: まぁ3D Stackingに行くのは当然である。

-
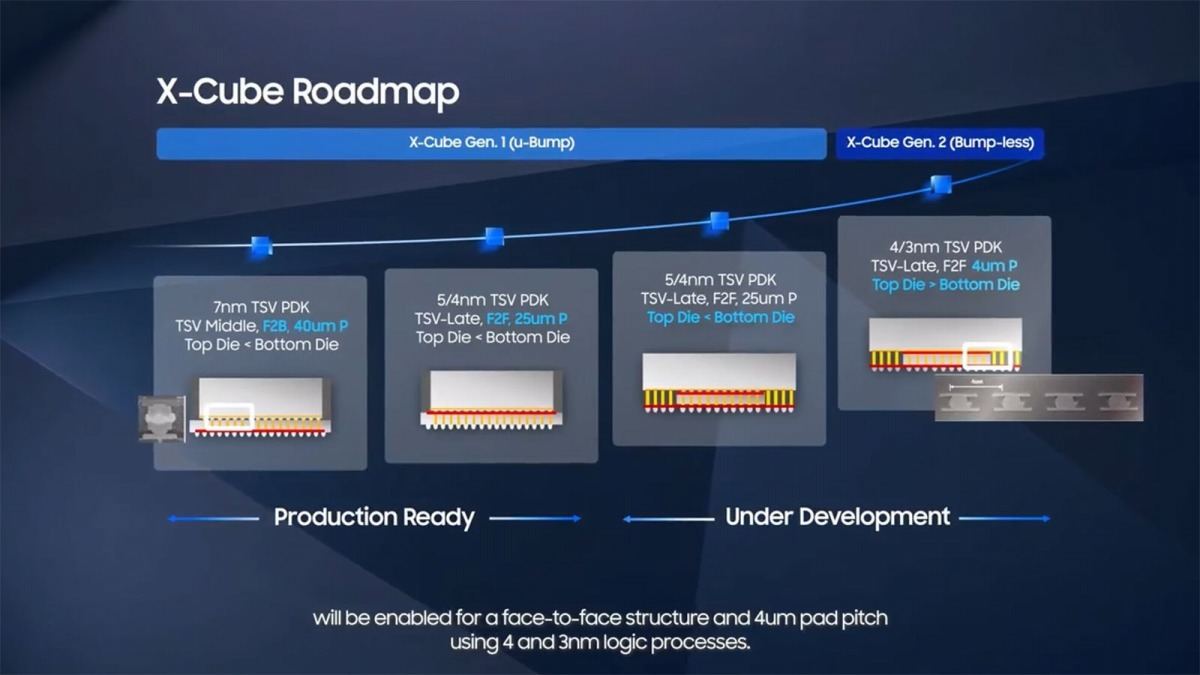
Photo24: 小型のBase Chipの周囲にTSVを立て、Daughter Chipを搭載するという方式。

Chip-on-Chipに関しては、2020年のHotChipsで発表されたSaint-S(Photo25)が説明されたが、これ見かけはSoICと似ている。ただ実際にはSoIC(というか、AMDの3D V-Cache)とは異なり、L3そのものを拡張するというよりは、SRAMダイをL4的に接続するといったI/Fになっており、まだ量産向けとするには厳しい感じである。長期的には実装オプションの一つとして提供されるかもしれないが、短期的にはこれを利用した製品は出てこなそうだ。
-

Photo25: そもそも発表もHotChips 32のPoster Sessionというあたり、まだ量産向けの技術の発表とは言い難い。

なおX-Cubeに関しては、2021年11月にInterposerをSiliconではなく有機基板に切り替えたH-Cubeの提供を発表している(Photo26)。要するにCoWoS-LのSamsungバージョンと考えれば良いだろう。
-
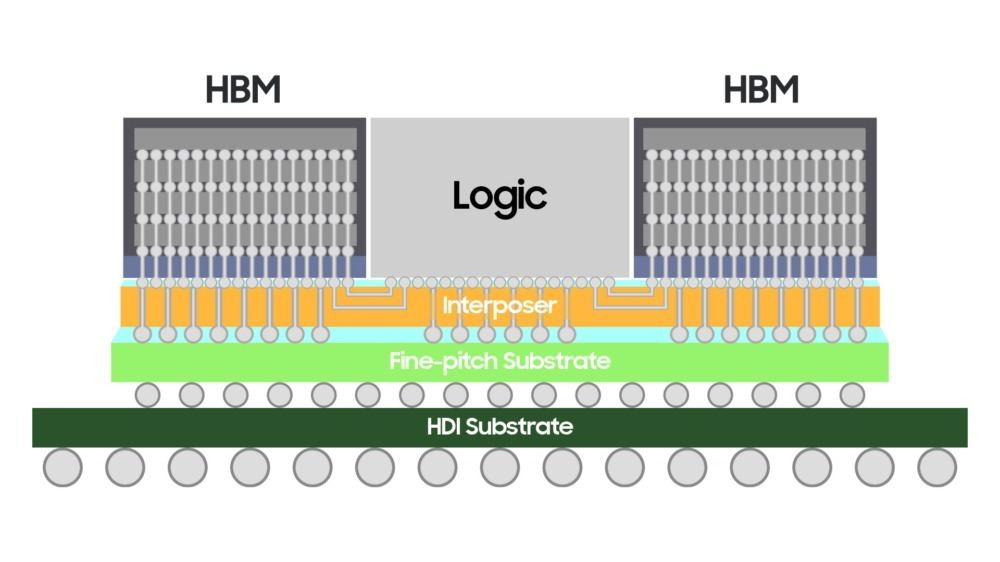
Photo26: Silicon Interposerに替えてHDI(High-Density Interconnection) substrateを利用する事で、大型のパッケージにも対応できるようになるとしている。

ということで話を戻す。GAAに関しては2023年以降なので、2022年はFinFETベースとなるが、上でちょっと書いたようにAMDはChromebook向けのAPUをSamsungの4LPEないし4LPPで製造するという話が出ている。TSMCの5nmは高価格帯向けのZen 4(や後追いでZen 4e)の製造で逼迫しているから、相対的にキャパがあるSamsungに逃がす、というあたりだろう。このマーケットも、ArmベースのSoCと競合するから、古いプロセスのままでは競争力が足りないという判断であろう。またAthlonについてもSamsungを利用するという話がある。
GPUに関しては、メインストリーム以上はNVIDIA/AMD/Intelに関しては全部TSMCの5/6nmに移行すると見られるが、例えばNVIDIAのGeForce RTX 4000シリーズのローエンドに関しては、やはりTSMCのキャパシティの問題からSamsungを使う可能性は結構高い様に思われる。








