
新年の幕開けに、パーソナルコンピュータのハードウェア技術の動向を占う「PCテクノロジートレンド」をお届けする。本稿はCPU編として、IntelとAMDの2軸でCPUロードマップを紹介したい。
|
(1/1掲載) PCテクノロジートレンド 2020 - プロセス編 (本稿) PCテクノロジートレンド 2020 - CPU編 (1/3掲載) PCテクノロジートレンド 2020 - GPU編 (1/4掲載) PCテクノロジートレンド 2020 - DRAMとFlash編 (1/5掲載) PCテクノロジートレンド 2020 - チップセット編 |
|---|
***
◆Intel CPU
-

Photo12: 激しく動き回るポン太先生。これが記事に載せられる最後の機会だろうか?
(編集注:「PCテクノロジートレンド」では例年、記事中に度々猫が登場します。これは単に猫が好きというだけではなく、著者の助手(?)の猫たちが仕事を手伝う(?)様子を適宜差し込むことで、閑話休題的に話題を区切るという猫大好きな記事構成上の演出です)

さて、IntelのCPUについて。Processの所(PCテクノロジートレンド 2020 - プロセス編)でご説明した通り、10nm+(や10nm++)を使ったCPUは、原則としてTDP枠が28W位までの範囲に収まる事になる。要するにこの程度の消費電力(≒動作周波数)の範囲であれば、14nm++プロセスと互角以上の性能が出せるからで、逆にこれ以上動作周波数を上げようとすると、消費電力が急増してしまう。それもあってMobile向けにはラインナップ出来るIce Lakeであるが、そのMobile向けですらCPU性能を重視する用途には14nm++のComet Lakeも並べてラインナップせざるを得ない、という有様であった。
ということで2020年のCPUについて。まずDesktop向けのCore iであるが、こちらは全面的にComet Lakeが投入される。言ってみればCoffee Lake Refreshとでもいうべき製品で、現状把握できている主な相違点は
- 最大10コア構成。ダイとしては10+2(後述)と6+2の2つのダイが用意される「らしい」
- 製品ラインナップは10/8/6/4/2コアまで。ローエンドのCeleron向けはHyperThreadingが無効化されて2core/2thread構成だが、その上位の製品(Core i9/i7/i5/i3/Pentium)は全てHyperThreadingが有効化される
- L2は最大20MB(10コアの場合)
- TDPは125W/65W/35Wの3つ構成
- メモリはDDR4-2933止まりでDDR4-3200の定格サポートは無し。またPCI ExpressのサポートもGen3止まり
- GPUは基本的にはCoffee Lakeと大差なし(Gen9ベース)
- パッケージは新しいLGA1200に切り替わる。寸法的には従来のLGA1151と変わらないが、機械的形状(パッケージの切り欠き)及び電気的形状(信号の配置)はLGA1151と互換性が無い
- チップセットとしてはIntel 400シリーズが用意される
といったあたりである。まだ動作周波数など正確なところは判明していないが、特にハイエンドの10コア構成となるCore i9シリーズの場合、Baseは3GHz台、Boostが5GHzオーバーというあたりに位置する。現状の製品で言うと、(ヤケクソ動作のCore i9-9900KSはまた別と考えれば)Core i9-9900KがBase 3.6GHz/Boost 5GHzというあたりで、これを若干上回る程度に設定されると思われる。
ちょっと意外だったのはGPU。筆者が以前聞いていた話だと、10+0と6+2というコア構成になる筈だった。理由はダイサイズである。以前こちらに書いたが、8コアのCoffee Lake Refreshで既に178平方mmものダイサイズになっており、このまま更に2コアを足すと、ダイサイズは200平方mmを超えてしまう。そうでなくても14nm++の供給が間に合わないと言っている状況で、更にダイサイズを大きくしたら、更に供給と歩留まりが悪くなるのは明白だからだ。また、Core i3とかのグレードだと統合グラフィックが重要視されるが、Core i9で統合グラフィックを使うというケースはむしろ稀で、普通はDiscrete Graphicsを使う。であればいっそのこと、ハイエンドはCPUコア+Uncore(PCI Expressその他)のみにしてしまえばダイサイズを6コアのCoffee Lakeよりちょっと大きい程度に留められる。一方でメインストリーム~ローエンド向けは6+2コアにすれば、これはCoffee Lakeとほぼ同サイズだから、現状よりも供給が悪化したりしない、という訳だ。これは非常に説得力のあるストーリーで、筆者も「さもありなん」とか思っていたのだが、どうも実際には10+2コアになる模様で、正直ちょっと驚いている。現状はGPU無しのFモデルについては特に聞こえてきていないが、実際にはFモデルも併せてラインナップされる、なんてことになりそうな予感がする。加えて、2020年も引き続き14nmの生産が逼迫しそうな予感がひしひしとする。
実は2019年12月に入り、Intelが22nmのHaswellベースのPentiumの販売終了をキャンセルした、という話が出てきている。実際、このリンク先を見るとStatusが"Launched"に戻っている。要するにCeleron/Pentiumグレードに関しては、もはや14nmでは供給が間に合わないので、22nmのHaswellベースの「新製品」を投入してカバーしよう、という思惑あるらしい。確かにここまですれば、14nmの供給不足改善には効果がありそうだが、「HaswellでもComet Lakeでもどっちでもいい」という顧客がどの程度いるのかはよくわからない。ついでにいえば、そこまでしてComet Lakeに統合GPUを搭載したい理由も今一つ不明のままではある。
このComet Lakeは当初今年第2四半期中に投入という話だったが、ちょっと前倒しされて今年第1四半期に投入される(発表そのものはCESの可能性もある)模様だ。運が良ければCESでマザーボードメーカーからIntel 400シリーズを搭載したComet Lake向けマザーボードの展示が見られるかもしれない。
さてその次である。現状の後継製品として
- Ice Lake→Tiger Lake(10nm++)
- Comet Lake→Rocket Lake(14nm++)
がそれぞれ予定されている。ただTiger Lake/Rocket Lakeに関しては、デスクトップ向けは現時点での投入予定は2021年第1四半期~第2四半期という話で、2020年中の投入は考えられていない。一方Mobile向けに関しては、こちらも当初は2021年からの投入という話だったのが少し前倒しされ、2020年中の投入になったようだ。タイミング的には2020年の第4四半期あたりであろうか?
まずTiger Lakeであるが、こちらはおそらくCPUコアがSunny Coveから、以前こちらに出ていたWillow Coveに切り替わると思われる。そしてGPUコアは発表にもあった、第一世代のX^e(Xe)ベースになる組み合わせだ。ただこのTiger Lake、Y-SKUはTDP 9Wのままだが、U-SKUは15Wから28WにTDPが引き上げられる模様である。Ice LakeでもConfigurable TDPで28Wまで引き上げ可能だったが、Tiger Lakeではこの28Wが必須になるらしい。理由はおそらく、現状のComet LakeとIce Lakeの二本立てという構成を一本化するためにはCPU性能を高くする必要があり、必然的に消費電力が増えるというあたりかもしれない。また、まだX^e(Xe)ベースのGPU(EU数が96になるという話もあるが、真偽は不明)の消費電力も相応に増えるから、と言う事もあるだろう。逆に言えば、Rocket Lakeがこの世代でもMobileに投入されるかどうか、現時点では定かではない。そしてTiger Lakeは今のところH-SKU(モバイルのTDP45W)やS-SKU(TDP65W)に投入予定が全くないのは、やはり10nm++でもそれほど動作周波数は引き上げ出来ないのだと考えられる。
一方Desktopは、そんな訳でRocket Lakeが入る事になるが、このRocket Lakeの素性が今一つ不明なままである。実は当初、Rocket Lakeは最大10コアになるという話であり、その上Gen 12(つまりX^e(Xe))ベースのGPU統合という話だったので、ダイサイズから考えると、引き続きSkyLakeベースのアーキテクチャになるかと思われていたのだが、ここに来て新たにRocket Lakeは最大8コアという話が出てきた。こうなると、ダイサイズを同程度に留めればより大きなダイが利用可能になる。つまりSkyLakeではなく、Sunny CoveあるいはWillow Coveの可能性も出てきた訳だ。現状詳細な話は一切不明なままだし、まだ登場まで時間があるので、このあたりは引き続き追いかけてゆきたい。なお、このRocket LakeがComet Lakeとプラットフォーム互換性があるかどうか、も現状不明である。普通に考えるとありそうなものではあるのだが。
次いでServer(とCore-X)の話。2019年はSkylake-SP→Cascade Lake-SPへの移行が行われた。また2019年8月にはCascade Lakeの後継であるCooper Lakeを2020年に投入する事を明らかにしている。ただCooper Lakeの特徴は
- Ice Lake-SPとのプラットフォーム互換性を保つ
- BFLOAT16のサポートによりAI Training/Inferenceの性能を大幅に向上
- 最大56コア製品を用意
といったあたりが主要な違いで、Xeon向けには用意されるものの、Core-X向けにはあまりメリットが無いので、こちらは「基本」見送りになるのではないかと思われる。ちなみに56コア製品はCascade Lakeの時にもCascade Lake-APという形で用意されたが、こちらはI/Fが独自と言う事もあってパッケージそのものがCascade Lakeと互換性がなかった。Cooper Lakeも、56コア製品に関しては内部的にはMCMを利用した2ダイ構造と思われるが、マザーボードに関しては1ダイのCooper Lakeのものがそのまま利用できる様になると思われる。ただこれ、AMDが2020年に投入予定の64コアThreadripperと互角に戦えるほぼ唯一の製品でもあり、それもあってCooper Lakeの2ダイ製品のみCore-Xにラインナップされても不思議ではない。
さて、Cooper Lakeまでは基本的にSkyLake-SPのコアをベースに、AVXユニットなどに改良を加えていった、いわば「継ぎはぎ」製品であるが、恐らく2020年の後半にIce Lake-SPが投入される。Processの章や上段でも10nmの素性について色々説明してきたが、Xeon向けの場合はとにかくコア数を多く取りたいし、コアそのものも肥大化の傾向にあるから、動作周波数を低めに抑えてもコア数を増やす傾向にある。実際第2世代Xeon Scalableの一覧を見ると、コア数が多い製品はBaseが2GHz台(中には1.90GHzなんて製品もある)であり、3GHzを超えているのはコア数が4とかの少ない製品に限られる。こうした用途であれば、10nm+あるいは10nm++でも何とか利用可能という話である(実際にはBaseは2GHzを切るかもしれない)。コア数は現状最大38コアとされている。ちょっと中途半端に見えるかもしれないが、Xeon Scalableの場合はMesh構成になり、かつMemory Controllerも入る。Skylake-SPの構成がこちらにあるが、Meshそのものは6×5の30コア分で、うち2つがMemory Controllerに割り当てられている形だ。同様にIce Lake-SPも、Mesh自体は恐らく8×5の40コア分で、うち2つがMemory Controllerに割り当てられる形になっていると考えられる。
現在聞こえてきている話では、Ice Lake-SPは2020年第3四半期に投入予定となっている。
さて、ここまで一切7nmの世代の話をしていないが、実際この7nmに関しては全く情報がない。ロードマップ的に言えばGolden Coveがこの7nm世代を利用する(CPUのコード名としてはSapphire Rapids)筈だが、7nmそのもののLaunchが2021年の恐らく後半になるから、投入されるまであと早くてあと1年半、下手をすると2年ほどかかる計算になる。このあたりはもう少し7nmが現実的に量産可能になるあたりで詳細が語られ始めるのではないかと思う。
最後におまけでLakefieldの話を。LakefieldはもともとはFoverosとという3D Stacking技術と対になって登場したものである。2018年末に発表された際の話は、10nmで製造されたCompute Coreを搭載するDieと14nm++で製造されたLow Power Core+I/O Die、それとDRAMを立体積層するというコンセプトであった。両方のDieにCPUコアが乗り、これをArmのbit.LITTLE風に切り替えて使うというもので、アイディアはともかくとして実装には色々道のりが遠そうだと思われた。ところが1月のCESでは、この構成が変化し、Atom+CoreのCompute Dieが10nm、I/Oが14nmでそれぞれ製造され、これとDRAMをFoverosで積層するという話になった。まだこの時点ではCoreがSunny Coveベースであることが明らかにされただけであったが、Atomの方が何かは不明なままだった。このあたりが多少発表になったのは、2019年8月のHot Chips 31である。"Lakefield: Hybrid cores in 3D Package"というセッションで、Sunny Cove×1+Tremont×4、それにGen 11.5のGPUが統合されることが明らかにされた(Photo13)。Tremontの名前は2018年末に明らかにされたが、その詳細は全く不明なままだった。HotChipsの講演でも、内部構造には一切触れないままにその性能(正確に言えば性能/消費電力比)のみが公開された(Photo14)。これだけ見ていると、Single Thread動作のアプリケーションはSunny Coveで、Multi-Thread動作のアプリケーションはTremontで動作させる方が効率が良いという話で、そういうスケジューラが搭載されるのかもしれない。昨年、Windowsにbig.LITTLEが利用できるのか? と書いたが、よく考えるとWindows on Arm、つまりQualcommのSnapdragonベースのWindowsは、そのSnapdragonがbig.LITTLE構成になっているから、当然Windowsもこれに対応している筈である。勿論Qualcommの場合とは異なったScheduling Schemeが必要になるから、この実装はおそらくIntelとMicrosoftのチームが共同で行っていると思われるが。
-

Photo13: SNCがSunnyCove、TNTがTremontの略。

-
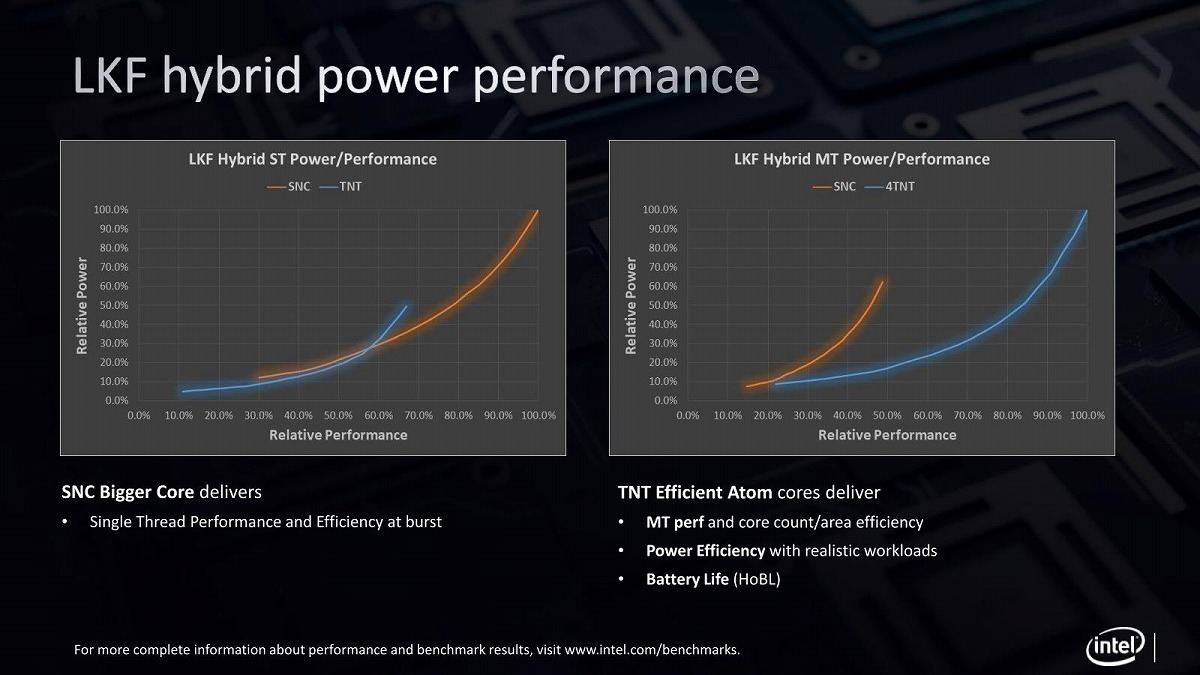
Photo14: TremontとSunny Coveのクロスするポイントが、性能で言えば60%弱、消費電力で言えば25%あたりというところが興味深い。

さてこのLakefield、MicrosoftのSurface Neoに搭載されることが発表されて俄然注目を集めた訳だが、そのタイミングを見計らうように2019年10月23・24日に開催されたLinley Fall Processor Conference 2019でその詳細が明らかにされた。まず全体の構造だが、なんと6命令同時Decode、10命令同時発行のOut-of-Order/SuperScalarという、強烈に重厚なコアになっている(Photo15)。まずフロントエンドだが、Instruction Cacheのみ共通だが、実際には2組の3命令のデコーダが搭載されるような格好になっている(Photo16)。これはHyperThreadingを前提に、2つのThreadのFetch→Decodeを同時に行わせよう、という仕組みであり、なので原則として1 ThreadあたりのDecode性能は3命令/cycleに限られている(Photo17)。分岐予測の強化やOut-of-Order Fetchの搭載なども施された(Photo18)。実行ユニットはトータル10だが、うち整数部が7つである。構成的にはSandy Bridge/Ivy Bridge(ALU×3+AGPU×2+Store Data×1)とHaswell(ALU×4+AGPU×3+Store Data×1)の中間位の規模となっている。浮動小数点/SIMD演算(Photo20)については、AVXのサポートは無く、あくまでもSSEどまりになっている。恐らく"AVXが必要なアプリケーションはSunnyCoveを使え"という事であろう。
-

Photo15: デコーダは実際には3×2、と言う構成になる。後述。

-
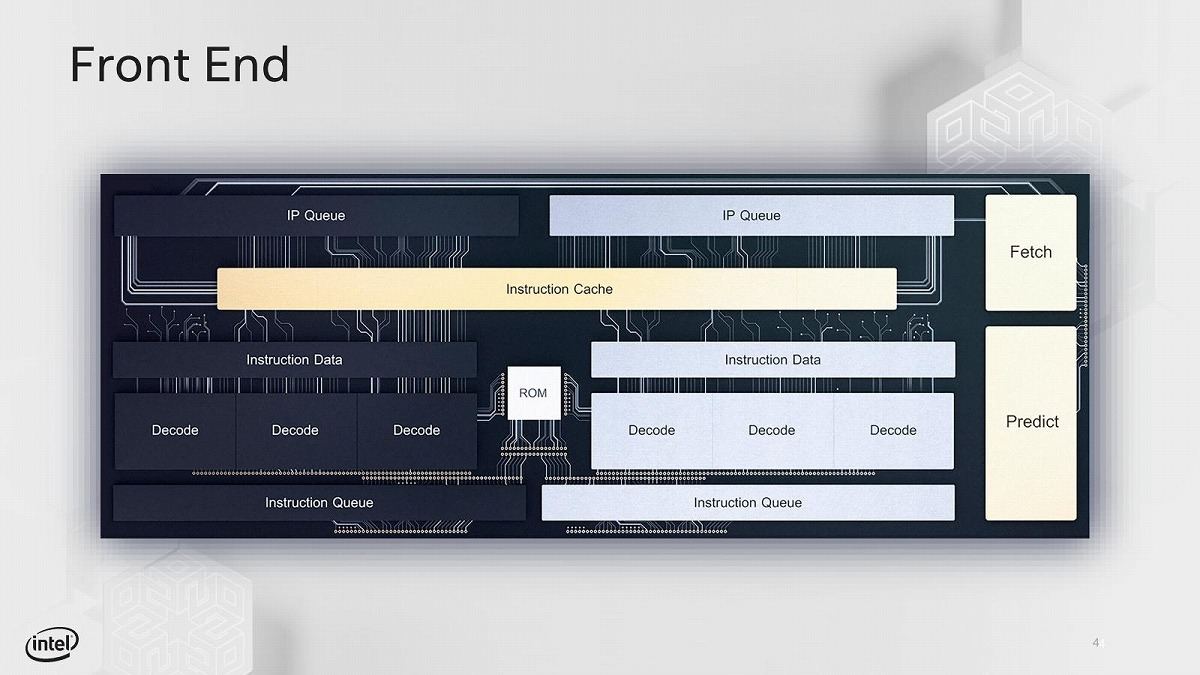
Photo16: IP QueueとかInstruction Queueも別々になっている。

-

Photo17: 問題は"Optinal single cluster mode"で、このモードだとHyper Threadingが無効化されることを前提に、2つのDecoderやQueue類が連携して動くようにも見えなくはないが、こちらの詳細は不明。

-

Photo18: "Core class"というのは、恐らくはSandy Bridgeあたりに相当するものと考えられる。また2つのThreadのPrefetchが必要だから、当然Out-of-orderでの発行が必要になる。

-

Photo19: SandyBridge/IvyBridgeに比べて分岐ユニットが分離され、またALUとFPU別のIssue Portを使う形になっている。またBranch UnitもIssue Portが分けられた。

-
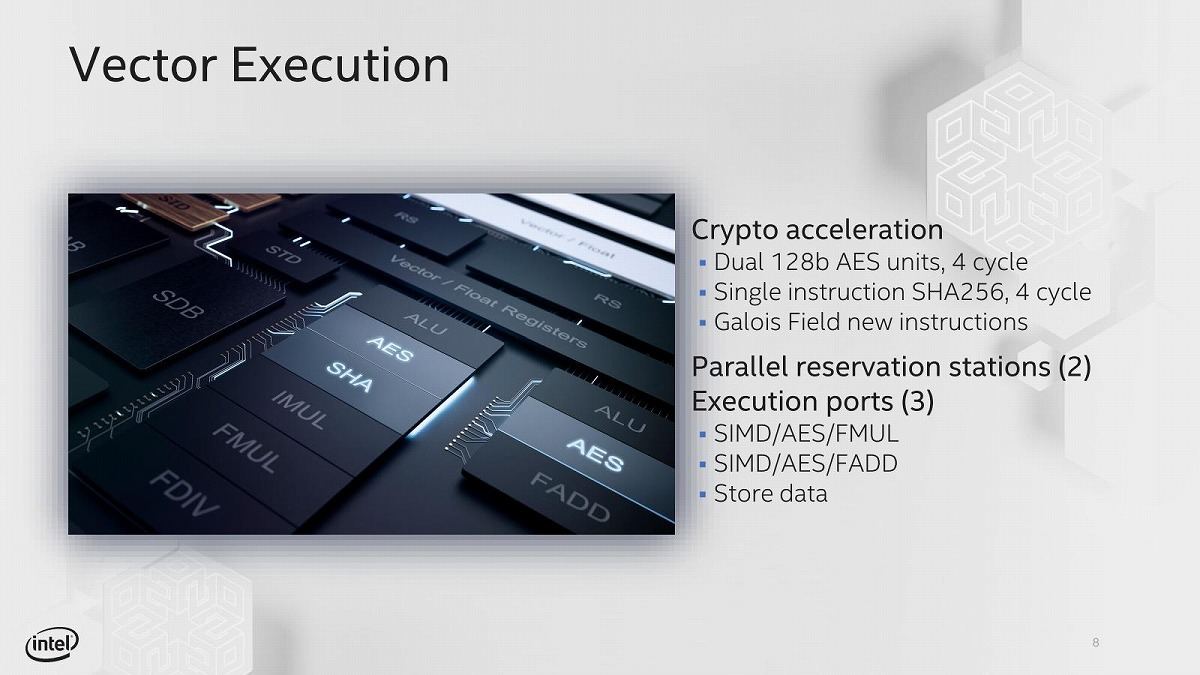
Photo20: その代わり、異様に暗号化処理関係の性能が強化された。ガロア体演算に関しては、Tremontが実装する最初のプロセッサとなる。

Load/Store(Photo21)はデュアル構成だが、これは2つのSSEユニットを同時に動かすために必要になるためだ。なので帯域そのものは128bit幅でしかないが、AVXをサポートしなければこれで十分、という事なのであろう。これと組み合わせるL2キャッシュは最大4コアで共有で、それはいいのだがサイズが1.5MB~4.5MBとやけに中途半端な数字になっているのがちょっと興味深い(Photo22)。
-

Photo21: L2 TLBのサイズが1024とかなり増やされているのも特徴的。

-

Photo22: 先のSingle Cluster Modeもそうだが、L2/L3へのQoSあたりは、Lakefield向けというよりは、今後登場するTremontベースのNetwork機器向けSoCなどに向けた機能と思われる。

ちなみに性能ということで現行のGoldmont Plusとの性能比較をおこなったのがこちら(Photo23)で、最低10%強、最大80%弱、平均30%の性能改善が見られるとする。Goldmont Plusの30%増という程度だと、同一動作周波数であればそれこそSandy Bridgeクラスに近い気はするが、先のPhoto14の様に、比較的動作周波数が低いところで利用されることを考えると、絶対性能そのものはそう高くないだろう。ただLakefieldの潜在的な競合製品はSnapdragon 8cxとかその下のSnapdragon 8c/7cであり、これと競合できる性能があれば良いという考え方もある訳で、実際10nmプロセスの美味しいところを使って動作する、というコンセプトの製品と考えられる。
-
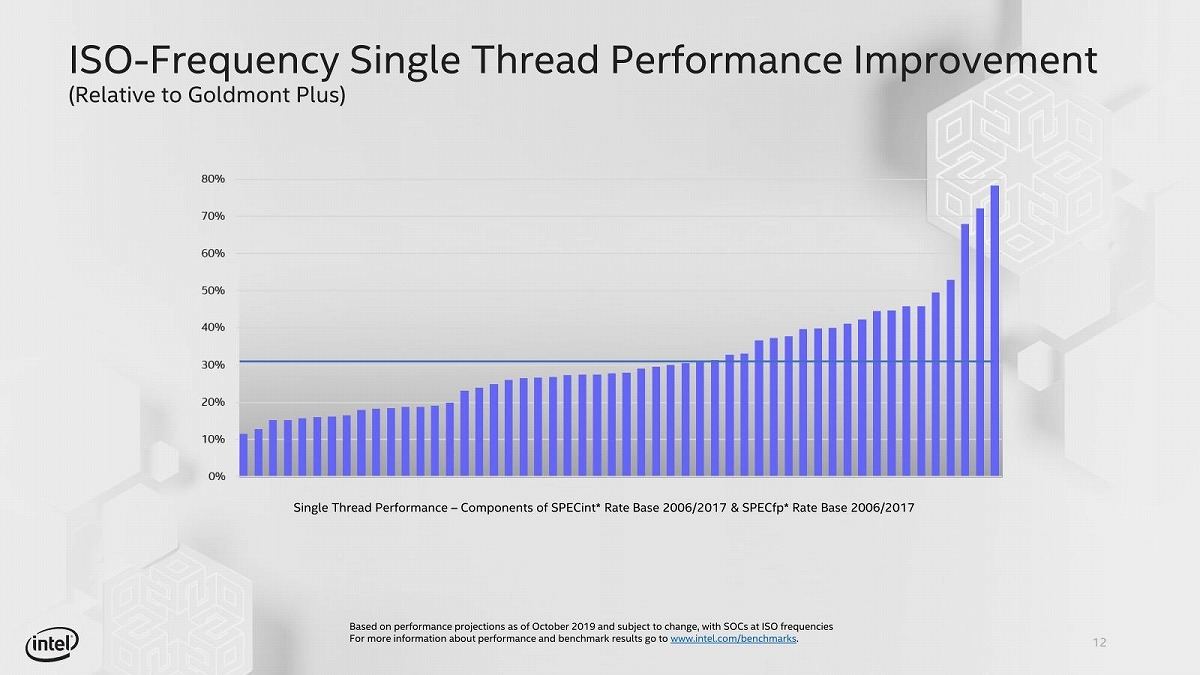
Photo23: 比較はSPECint Rate Base/SPECfp Rate Baseの複数のテスト項目を、性能向上順に並べている形なので、どんなテストで性能が上がるか、までは読み取れない。一応同一動作周波数におけるSingle Thread性能比なので、ほぼIPCの比として良いかと思う。

この推測が正しければ、TremontベースのPentiumとかCeleronの可能性はちょっと低そうな感じではある。勿論GPU性能はそれなりに高そうなので、NUCなどには使われるかもしれないが。








