RightMark Memory Analyzer 3.8その3「I-Cache Latency」(グラフ61~85)
cpu.rightmark.org
http://cpu.rightmark.org/
次はCacheの様子を確認してみることにする。グラフ61~68はI-CacheのLatencyを、Near JumpとFar Jumpでそれぞれ測定したものだ(Bandwidthはグラフ42~55で、最大16Bytes/cycleと判明している)。
まずはNear Jump(グラフ61~64)。L1領域においては、Richland/Kaveriは完全に同じだし、Haswellも同程度である(1.5KμOpsの範囲ではμOp Decoded Cacheがさらに効く分HaswellのLatencyは低いのは先に説明した通り。
ちなみにこれはNear Jump(64KB範囲内)での数字なので、64KBを超えるとややLatencyが増えるのはどのプロセッサも同じである。これを超えると次はL2でのアクセスになるが、ここでKaveriはRichlandよりもやや低めのLatencyとなっている。これがL2 Missになると、今度はKaveriが一番Latencyが大きいのはこれまでも見てきた通りだ。
ではこれがFar Jump(グラフ65~68)だとどうか? というと、特にForward Accessのグラフ65がわかりやすいが、妙にL1の範囲でLatencyが大きくなっているのが分かる。もっともRandom(グラフ67)あるいはPseudo-Random(グラフ68)だとRichlandも同様な傾向を示すので、一概にKaveriだけがおかしいという訳ではないが、特にL1 Cacheに関してはちょっと制御アルゴリズムが変わったように思える。これは3-wayという変則的な構造になったことと無縁ではない様に筆者には感じられる。
ではD-Cacheはどうか? ということで、グラフ69~71がCache Bandwidhtである。まずRead(グラフ69)を見てみると、L1はほぼ32Bytes/cycleでこれは3つとも同じく。L2に関してはHaswellが20Bytes/cycle、Kaveriが12~13Bytes/cycle、Richlandが10Bytes/cycle強といったところで、2Bytes/cycleほどRichlandから強化されているのが分かる。
ではWrite(グラフ70)は? というと、L1は16Bytes/cycleで善製品共通。L2はHaswellが10.5Bytes/cycle、Kaveriが6.8Bytes/cycleほど、Richlandが5.2Bytes/cycleほどで、ここも1.5Bytes/cycle弱の強化がなされている。
結果としてCopy(グラフ71)の結果はWriteの結果に引っ張られるような形になるのは当然だが、L2の範囲(171KB~1MB前後)までHaswellとKaveriがほぼ同じ帯域を示しているのは、随分頑張ったのだと思う。
ではLatencyは?ということで、グラフ72~75に結果を示す。全般的にKaveriのスコアはRichlandよりも若干改善(L1/L2領域)した程度で、大きくは変わっておらず、Haswellとは大差がある形だ。
ところでこのD-Cacheについては、D-Cache Bandwidth(グラフ76~83)もちょっと確認してみた。まずはL1-L2 D-Cache Bandwidth(グラフ76~79)で、これは名前の通りL1-L2 Cache間のBandwidthを計測するものである。
ReadはL2→L1方向の転送で、Forward(アドレス順)/Backward(アドレス逆順)共にHaswellが32Bytes/cycle、Kaveri/Richlandは16Bytes/cycleとなっており、これはセオリー通りである。これが大きく変わるのはWrite(L1→L2方向の転送)で、Haswellが10.5Bytes/cycle強、Kaveriが9.9Bytes/cycle弱、Richlandは5.4Bytes/cycle弱といった具合で、Writebackに関してはKaveriで大幅な強化が見られる。
一方L2 D-Cache-RAM Bandwidth(グラフ80~83)で見ると、ReadはHaswellが5Bytes/cycle前後、Richlandが2.4Bytes/cycle前後で、Kaveriは若干改善され2.7Bytes/cycle弱と、まだHaswellには差があるもののそれなりに健闘している。
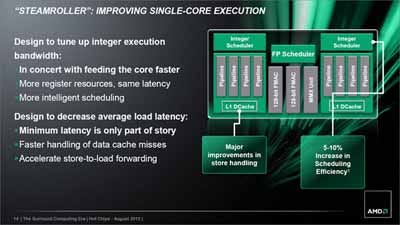
これはWriteでさらに明確で、Richlandが1.1Bytes/cycle弱なのに対してKaveriは1.5Bytes/cycle弱まで性能を上げている。Haswellには及ばないとは言え、このあたりが性能改善の底上げになっているものと思われる。実際資料でも"Major improvements in store handling"としており(Photo06)、これは説明と辻褄があう結果である。
|
Photo06:他にIntegerのスケジューリングでも5~10%の効率改善としている |