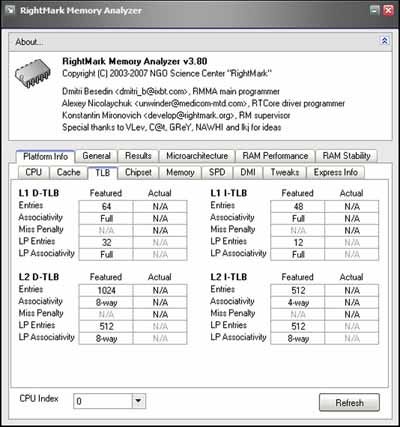
RightMark Memory Analyzer 3.8その6「D-TLB」(グラフ129~143)
cpu.rightmark.org
http://cpu.rightmark.org/
同様に、D-TLBについても確認しておく。グラフ129~131がD-TLB Sizeの比較である。面白いのはHaswellとRichland/Kaveriが非常に好対照なことで、Richland/KaveriはI-TLBが高速ながらD-TLBはやや遅い。逆にHawellはI-TLBが遅いがD-TLBが高速ということになっている。
それはともかくとして、こちらもPhoto07に示された傾向がきちんと反映されている。L1 D-TLBは4cycleでアクセス、これを超えるとL2 D-TLBに31cycleほどでアクセスできている。
|
Photo07:L2 TLBが命令/データで分離しているのが判る |
ただし構成が8wayなので、ある程度以上になると検索が余分に入る事になる。実際256 entriesあたりからLatencyが増えるが、Richlandが40cycleのところ、Kaveriは39cycleでアクセスできるあたりが若干改善されているとはいえる。
Associativity(グラフ132~143)もまた印象的であるが、64 Entriesまでは完全にフラットで、128 entriesからガンと増える傾向はRichlandと完全に同じで、ただし微妙にLatencyが削減されているあたりがKaveriの特徴といえる。
ということで駆け足でRMMAの結果を一通り見てみた。このRMMAの結果をまとめると
- Decoderは分割されたが、性能の改善はそのDecoder分割によるものとは言いがたく、ピーク性能そのものは変わらない。
- ただ細かな工夫により、実効IPCは若干改善している。
- Load/Storeが大幅に改善している。ただしLoadに関してはもっぱらメモリコントローラによる部分が大きく、逆にStoreはCPUコア側の改善と思われる。
- ほかにも細かな改善は見られるのだが、その一方で明らかに増えたMemory AccessのLatencyとか、キャッシュ周りの不可解な仕様変更(Cache Assosiativityでこれが顕著)など、性能を下げる方向のインパクトがある部分も見受けられる。もっともMemory AccessのLatencyは、Steamroller CoreそのものというよりはMemory Controller側(というか、Photo01~03で説明したInterconnect周り)がその主要因ではないかという気もする。
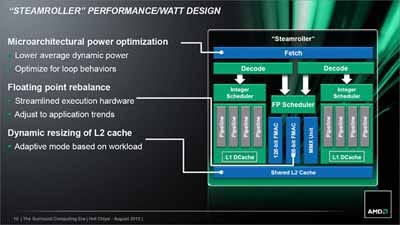
というあたりだろうか。ちなみにRMMAのテストでは確認できなかったが、このほかの変更として
- L2キャッシュのサイズを動的に変更できるL2 cache Dynamic resizing
- FPU構造の若干の変更
- Fetchの改善
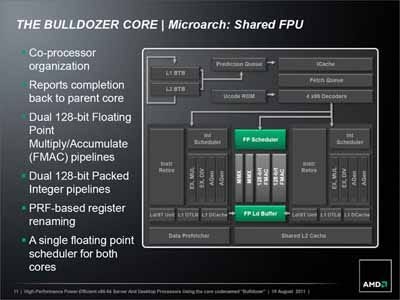
が挙げられている(Photo08)。このうちFPU構造であるが、もともとBulldozer/Piledriverでは、FPUは4つの実行ユニット(MMXと128bit FMACがそれぞれ2つ)が存在し(Photo09)、これに対応してSchedulerは4つの命令発行ポートをそれぞれの実行ユニットに割り付けていた。
これがSteamrollerでは命令発行ポートを3つに減らした、としている。ただし実行ユニットそのものの数は減っていないとしており、図を見る限り2つのMMX Unitが1つの命令ポートに重複して割り当てられるように切り替わったのではないかと思われる。
|
Photo08:FPUは実行ユニットそのものの数は変わっていないとしている |
|
Photo09:これはBulldozerのFPU周り |