VersalのDSPはFP32、あるいはFP16で計算ができるXilinxの呼び方ではDSP58というDSPである。このDSPはINT8/16/24で計算することもでき、また、固定小数点18bitの複素数での計算もできる。VersalチップはこのDSPを1968個搭載しており、FP32でのピーク性能は2.8TFlops、INT8でのピーク性能は11.8TOPSとなる。
-

VersalのDSPはFP32/16、INT8/16/24とCMPLX18で計算ができる。このDSPを1968個集積し、FP32では2.8TFlops、INT8では11.8TOPSのピーク性能を持つ

AIエンジンのノードは、ベクタコアとメモリからなり、それらが2次元メッシュトポロジでつながっている。さらに、上下、左右に隣接したノードには専用の接続が設けられている。
AIエンジンの数は400個で、INT8では133TOPSの性能を持つ。メッシュはノンブロッキングのデータ転送ができる。
L1メモリは、各ノードに分散されたメモリとなっており、全体の合計は12.5MBの容量がある。他のノードのメモリには直接アクセスできないが、専用リンクのある4方向の隣接ノードのメモリには直接アクセスできるようになっている。
-
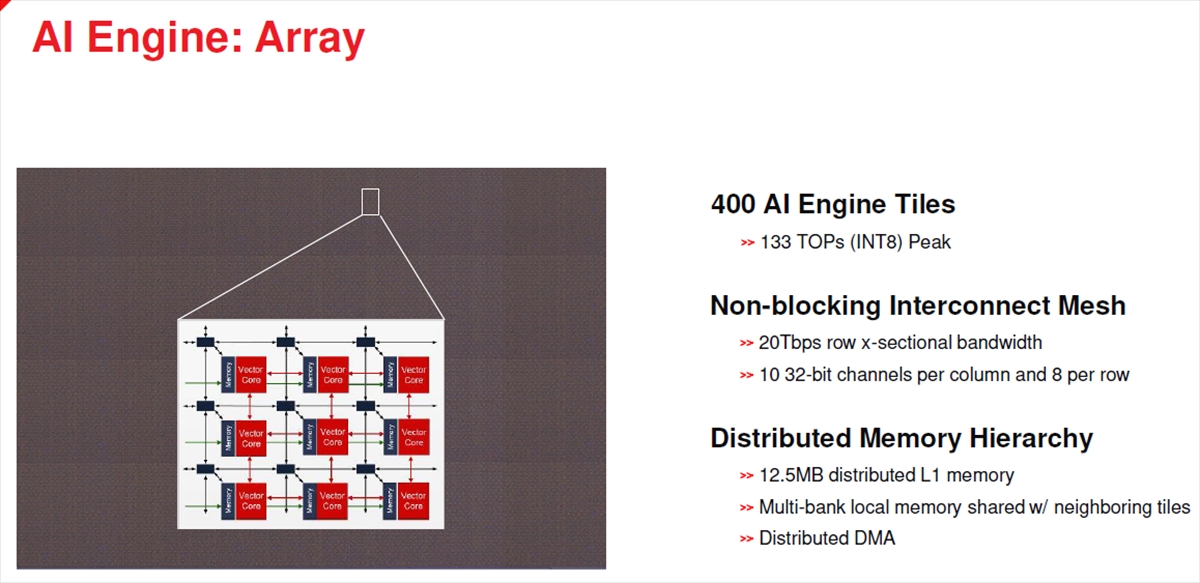
AIエンジンはノンブロッキングの2次元メッシュネットワークで接続されている。合計で12.5MBの分散メモリを持つ。分散メモリであるが、自ノードのメモリ以外に直結リンクのある隣接する4ノードのメモリもアクセスできる

AIエンジンのコアは32bitのスカラのRISCプロセサに512bit SIMDのベクタユニットが付いている。
-
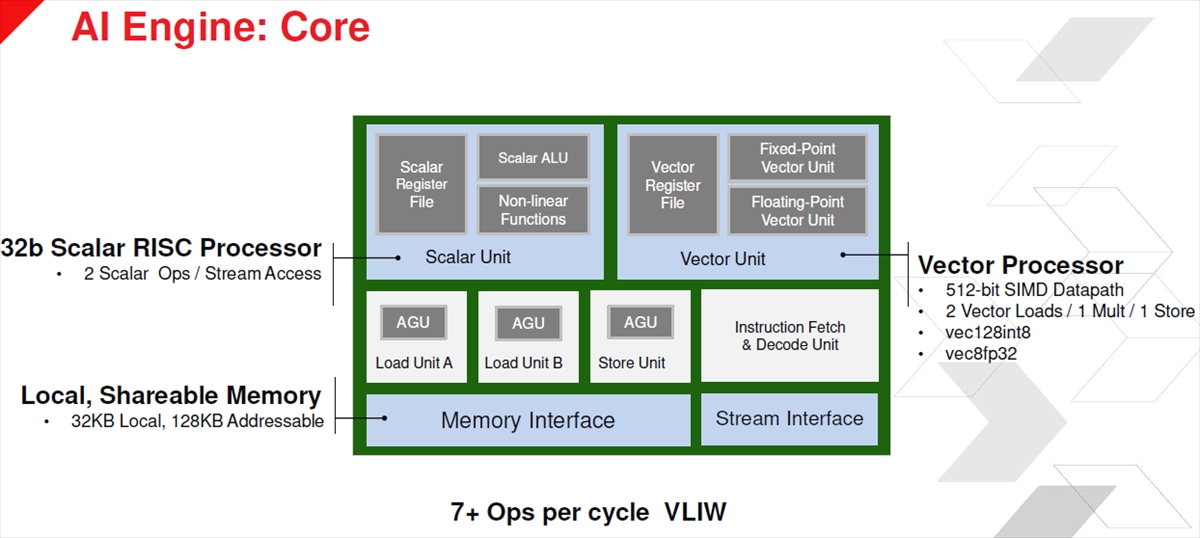
AIエンジンのコアは7+演算のVLIWコアになっている

AIコアは32×32の単精度FP、32×32のREAL、32×16のREAL、16×16のREAL、16×8のREAL、8×8のREALの演算に加えて32×32の複素数、32×16の複素数、16×16の複素数、16複素数×16REALの計算を行うことができる。次の図の棒グラフはこれらの演算が、それぞれ1サイクルに何回の積和演算ができるかを示している。
-
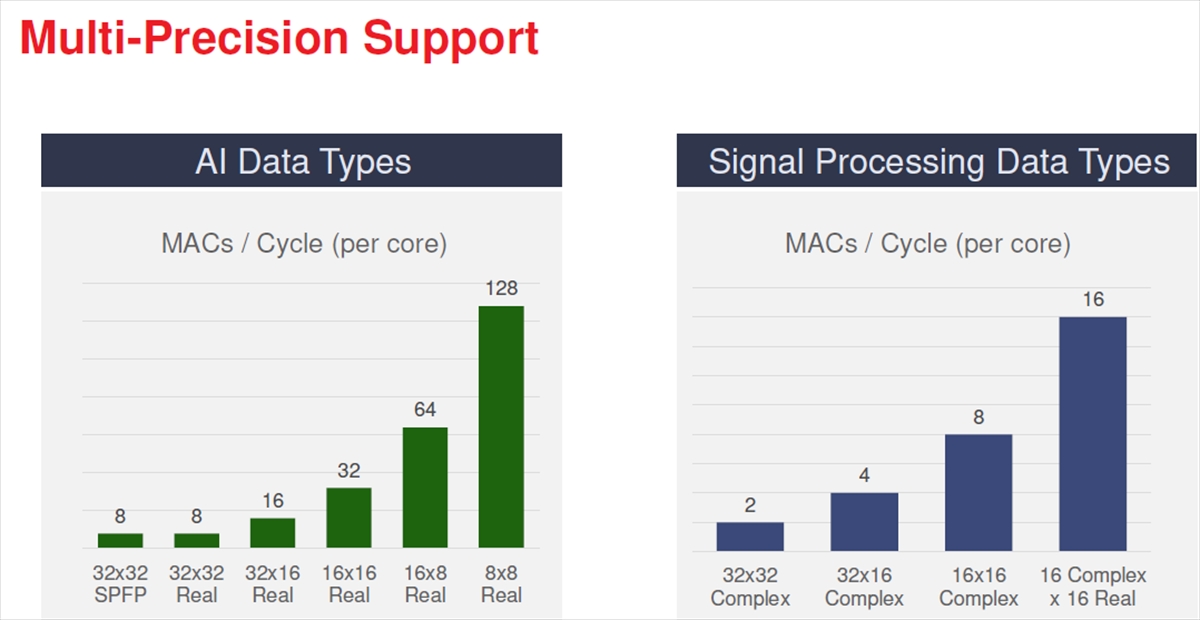
Versalの扱えるデータタイプと、それぞれのデータタイプでの1サイクルあたりの積和演算能力を示す

AIエンジンはL1 SRAMにつながっており、L1 SRAMからL2 SRAMにつながり、L2 SRAMはDRAMにつながるという階層構造になっている。また、L2からL1 SRAMへの転送では、マルチキャストやブロードキャストができる。
-
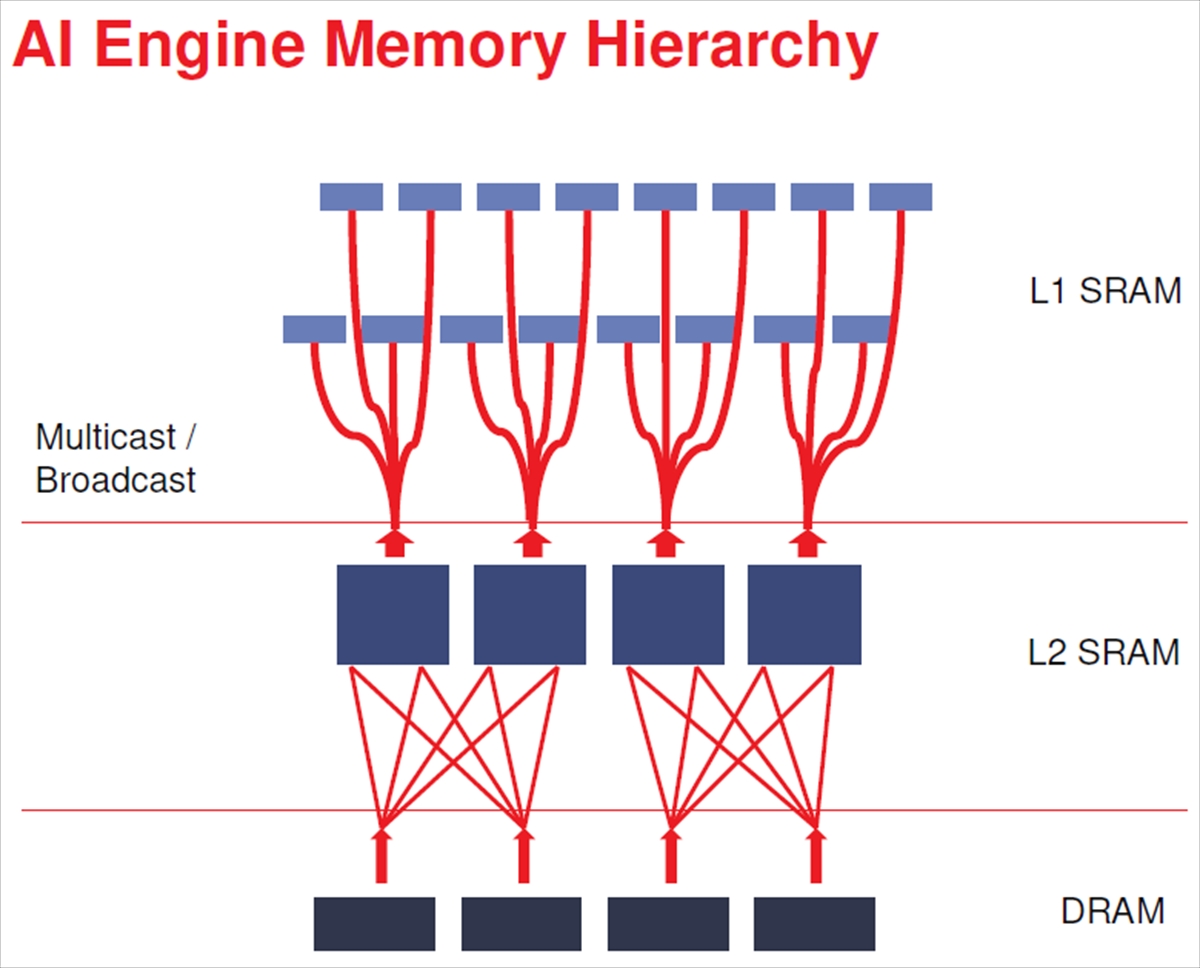
AIエンジンのメモリ階層。L1 SRAM-L2 SRAM-DRAMという階層である。Cacheではなくローカルメモリである。L2 SRAMからL1 SRAMへの転送にはマルチキャストやブロードキャストができる

DRAMの容量は>64GBで、Versalチップへのメモリバンド幅は102GB/sである。そして、16.3MBの容量のL2 SRAMのメモリバンド幅は1.6TB/sとなっている。そして、12.5MBのL1 SRAMは4コアクラスタに128KBのメモリが付くという形になっており、総バンド幅は38TB/sである。
-

Versalのメモリの階層と、各階層のメモリの容量とバンド幅

インタコネクトはノンブロッキングで、ボトルネックにならないように作られており、 キャッシュではなくローカルメモリであるので、キャッシュミスは発生しない。そして、計算とオーバラップしてDMAを行うことができる。
右の棒グラフはベクタプロセサの性能であり、AIエンジンの性能とは直接関係ないと思われる。
-

Versalのインタコネクトはノンブロッキングである。分散DMAを持ち、各コアの演算と転送をオーバラップできる

次の2つの棒グラフは、XilinxのUltraScale+ FPGAとVersalの推論性能を比較するものである。ただし、Versalは実測ではなく、VC1902 AIエンジンを使った場合の予測値である。
左はGoogleNetでの画像認識のスループットで、UltraScale+は4087イメージ/秒であるのに対して、Vaesalは29250イメージ/秒と7倍強の性能となっている。右の図はResNet-50での画像認識でのスループットの比較で、UltraScale+は2043イメージ/秒に対してVersalは11812イメージ/秒と約5倍の性能である。なお、Versalの性能は実測ではなく予想値である。しかし、最初の方のスライドにはすでに早期の顧客には出荷していると書かれており、チップが無いわけではなく、単に実測していないということのようである。
-
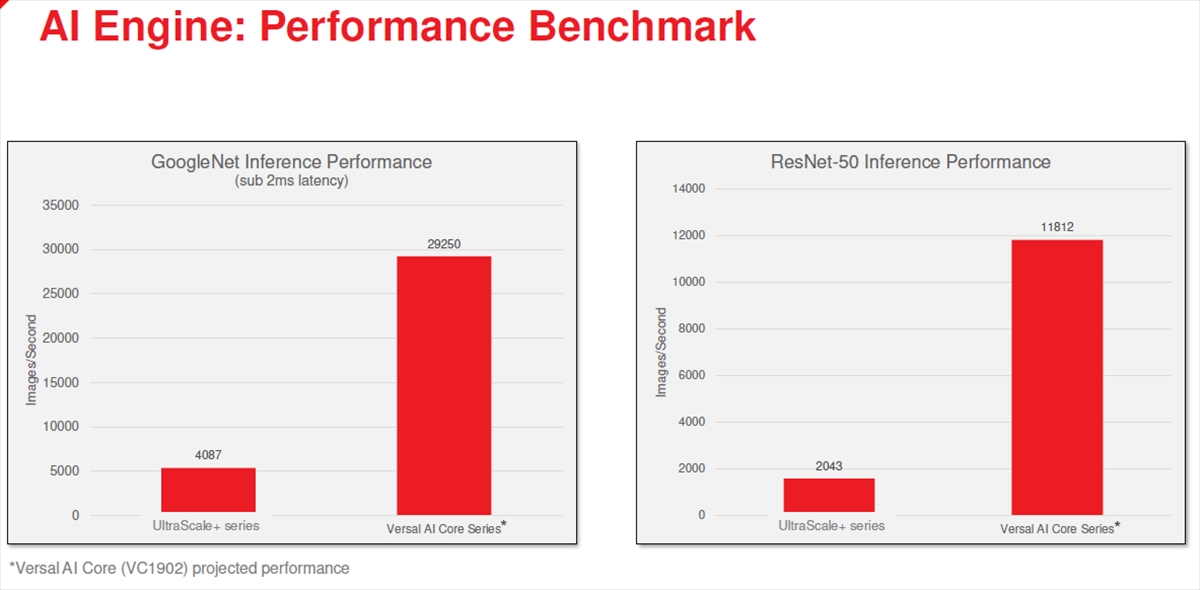
AIエンジンの性能。GoogleNetでのイメージ認識では7倍強の性能で、ResNer-50でのイメージ認識では約5倍の性能となっている

次の図はVersalを使ってAIアプリを加速する例である。AIエンジンとプログラマブルロジックの間の接続はTB/sのバンド幅があり、AIエンジンはBRAMやURAMもアクセスして処理を進めることができる。
-
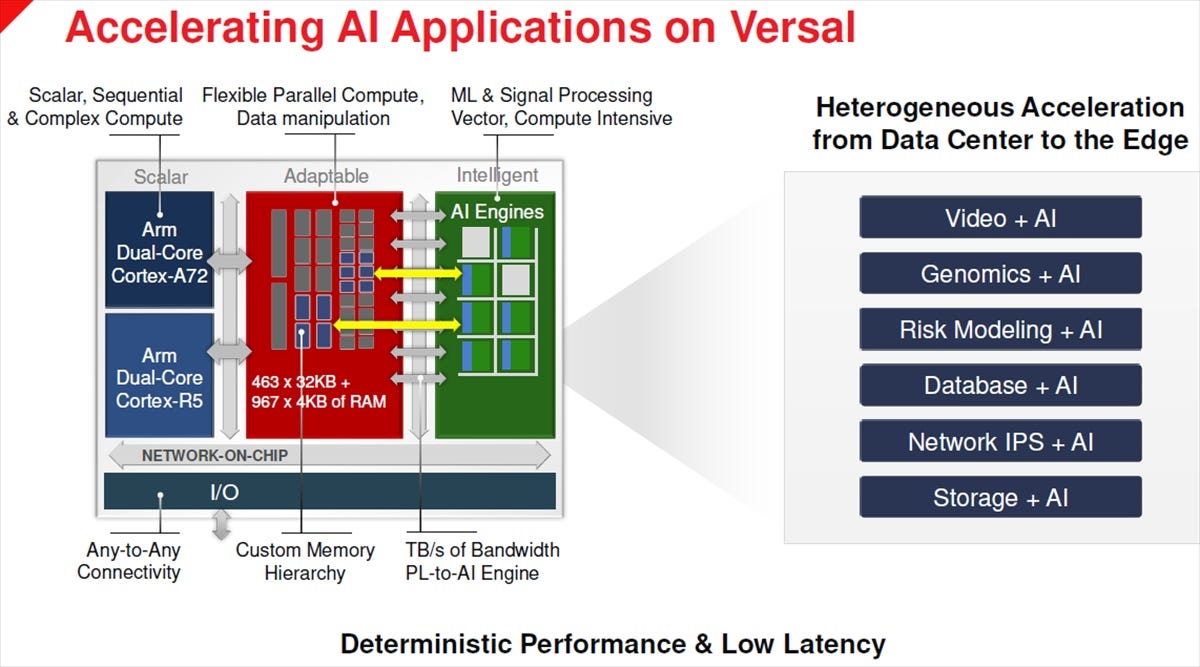
VersalでAI庶路を加速する例。AIエンジンはBRAMやURAMも使って処理を行うことができる。すべての処理が1チップに収まっているので、通信オーバヘッドを小さくできる

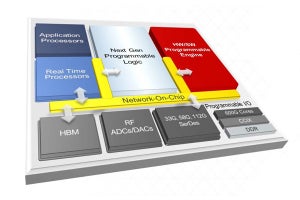
Adaptive Compute Acceleration Platform(ACAP)はXilinxの提供する新しいクラスのデバイスであり、Versalは第1世代のACAPデバイスである。Versalは新開発のソフトウェアプログラマブルなAIエンジンを装備し、新開発の高バンド幅ネットワークと強化したDDRメモリサブシステムを備えている。またFPGAのプログラマブルロジックもアーキテクチャを見直している。
VersalはXilinxの初の7nmデバイスであり、133TOPSのAIエンジン、12TOPSのDSPと90万個のLUTを集積している。
そして、256bitのDDR4/LPDDR4メモリが接続でき、最大25GbpsのPCIe Gen4あるいはCCIXポートをサポートしている。
-

VersalはACAPという新カテゴリのデバイスである。VC1902チップは7nmプロセスを使うXilinx初の製品である。VC1902は133TOPのAIエンジン、12TOPSのDSP、90万個のLUTを集積している

AIが多くのアプリケーションで利用されるようになってきており、Versalは、FPGAにAIエンジンを加えて欲しいというカスタマの要求にこたえる製品であると考えられる。VC1902のAIエンジンは133TOPSと今回のHot Chips 31での発表の中でもトップクラスの性能であり、応用範囲は広いと考えられる。
ただし、データセンターで広く採用されるかどうかには、消費電力や価格なども大きく影響する。
(次回は10月3日の掲載です)