構成によるチップ面積、性能、電力の変化
構成とチップ面積と性能、電力への影響を考えてみよう。小規模構成はINT8のデータパスで、DRAMへのインタフェースだけ、高度な機能は無しという最低限の構成を考える。一方、大規模構成はINT8に加えてINT16やFP16をサポートし、DRAMに加えて内蔵の高速SRAMを持ち、専用のマイクロコントローラを備え、重みの圧縮機能も持つというようなものを考える。
-

小規模構成は、INT8だけのサポートで、DRAMへのアクセスパスだけで、高度な機能をもっていないものを想定。大規模構成は、INT8に加えてINT16とFP16をサポートし、メモリはDRAMに加えて高速のSRAMを持ち、命令の実行を制御するマイクロコントローラを持つ。さらに、重みの圧縮などの高度な機能をもつものを想定する

なお、NVDLAはプロセサがコントロールバスを通して命令の実行を指示し、命令の実行が終わったら割込みでプロセサに通知し、プロセサは次の命令の実行を指示するというメカニズムとなっている。命令はConvolutionを計算するとか、Poolingを行うとかの単位で、個々のMAC演算を実行するというような小さな粒度ではないが、それでもかなりの頻度で割込みが上がることになる。
小規模構成では専用のマイクロコントローラを持っていないのでCPUが割込みを受け取って次の命令の実行を指示する。このため、高い性能のアクセラレータを作ることはできない。一方、大規模構成では専用のマイクロコントローラを持ち、個々の命令の実行指示や割込みの受け取りはマイクロコントローラが行い、アプリケーションに通知する必要があるハイレベルの命令の完了割込みだけをCPUに通知する。このため、高頻度の割込みを扱うことができ、高性能のアクセラレータを作れる。また、DRAMだけでなく、高速のSRAMに中間結果を格納して再利用することで性能を上げたり、消費電力を減らすことができる。
次の表は、16nmプロセスで1GHzクロックで動作する小規模構成のNVDLAのMAC数、Conv.Buffer容量、メモリバンド幅のパラメタを変えるとチップ面積や性能がどのようになるかを示すものである。
最大規模のMAC数が2048でConv.Bufferは512KB、メモリバンド幅は20GB/sのNVDLAは3.3mm2のチップ面積を必要とし、ResNet50で画像認識を行う場合の性能は269フレーム/秒、消費電力は388mWで電力効率は5.4DLTops/Wと見積もられる。一方、この表で最小の規模のMAC数64、Conv.Buffer容量は128KB、メモリバンド幅は1GB/sとの構成では、チップ面積は0.55mm2となり、画像認識性能は7.3フレーム/秒で消費電力は28mW、電力効率は2.0DLTops/Wとなる。
このように、パラメタの設定で7.3フレーム/秒から269フレーム/秒までの40倍近い性能レンジをカバーするアクセラレータが作れる。この場合、占有チップ面積は3.3mm2から0.55mm2と6倍の違いがあり、消費電力は388mWから28mWと約14倍の違いがある。
-

小規模NVDLAのMAC演算器数、Conv.Buffer容量とメモリバンド幅を振った場合の、チップ面積と性能の比較。最大のMAC数2048、Conv.Buffer512KB、メモリバンド幅20GB/sと最小のMAC数65、Conv.Buffer128KB、メモリバンド幅1GBを比較すると、40倍近くのフレーム処理速度をカバーするチップ面積は6倍、消費電力は約14倍の範囲をカバーする

16nmプロセス/1GHzのチップ性能はどの程度か
16nmプロセスを使い1GHzクロックで大規模構成のNVDLAを作る場合のチップ面積、性能、電力を考える。構成は、INT16/FP16のMAC数が512個、INT8のMACが1024個、Conv. Bufferが256KBで、チップ面積は2.4mm2で、DRAMバンド幅は15GB/s。そして、高速のSRAMのR/Wバンド幅は25/25GB/sとする。
性能を比較する設計のバリエーションは、演算がINT8かFP16かと高速SRAMの有無である。
演算がINT8でSRAM無しの場合は、画像認識性能は165フレーム/秒、消費電力は267mW、電力効率は4.8DLTops/Wと見積もられる。演算をFP16で行う場合は性能は59フレーム/秒で消費電力は276mW、電力効率は1.6DLTops/Wとなる。
2MBの内蔵SRAMを付けた場合は、演算がINT8の場合は230フレーム/秒、消費電力が348mWで電力効率は5.1DLTops/Wとなる。FP16演算の場合は、115フレーム/秒の認識性能で、電力は475mW、電力効率は1.9DLTops/Wとなっている。なお、大規模構成の場合のチップ面積と消費電力にはSRAMの分が含まれていないという注があり、2MBのSRAM付きのケースは実際は、この表の値よりもチップ面積、消費電力が増えることになると考えられる。
FP16は、整数演算よりずっと複雑な浮動小数点の演算を行うので、電力効率が下がるのはやむを得ない。SRAMを付けると性能が上がるのは当然であるが、SRAMの消費電力が入っていないので、電力効率が上がっているのか、下がっているのかはこのデータでは分からない。また、チップ面積の増大も気になる点である。
-
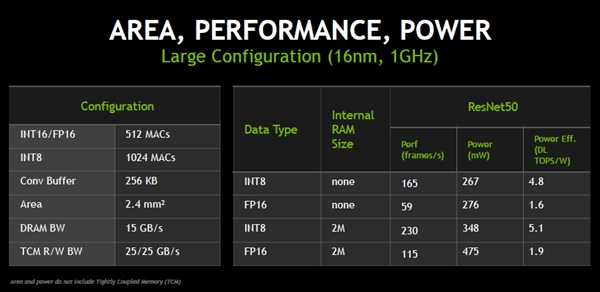
INT16/FP16 MACを512個、INT8 MACを1024個持ち、Conv.Bufferは256KB、メモリバンド幅は15GB/sで、SRAMのバンド幅はR/Wともに25GB/sという構成を考え、INT8で計算した場合とFP16で計算した場合、SRAM無しと2MBのSRAMを搭載した場合の比較。ただしSRAMの占めるチップ面積と消費電力を含んでいない比較であり、SRAM付きの構成が有利になっている

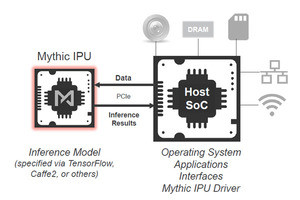
ソフトウェア環境は、NVDLAを使う場合は、Caffeなどで書かれたCNNのモデルとコンパイラパラメタをコンパイラに入力する。パーサとコンパイラはNVDLAにロードするNVDLA Loadableというモジュールを出力する。コンパイラは入力されたパラメタで作られるハードウェアで最適なレイヤモデルや計算方法を選択してロードモジュールを作る。
コンパイラから出力されるロードモジュールは、Run Timeに入力される。Run Timeの最初の箱がApplicationと書かれているが、次の例ではYOLOv3というオブジェクト検出アプリケーションが使われているが、このようなNVDLAを使うアプリケーションを指すものと思われる。
ユーザモードドライバ(UMD)はアプリケーションと合わせてLoadableモジュールを読み込み、推論処理の実行をカーネルモードドライバ(KMD)に指示する。
KMDは、NDVLAでの各層のオペレーションをスケジュールし、また、コントロールレジスタにアクセスしてNVDLAの各アクセラレータユニットの構成を設定したりする。
-

NVDLAのソフトウェアはCNNモデルとパラメタからLoadableモジュールを作るCompile時に環境と実行時のRun Time環境がある。コンパイラは、指定されたパラメタで作られるハードウェアでの実行に最適なLoadableを作る。Run Timeはアプリケーションと組み合わせ、UMDとKMDでNVDLAハードウェアでの実行を行わせる,ANVDLAのソフトウェアアーキテクチャ

現在、FPGA版のNVDLAの小規模モデルとSiFiveのRISC-V CPUを組み合わせたSoCの設計をオープンソースで提供している。NVDLAのMAC数は2048で、Conv.Bufferの容量は512KBである。
なお、Hot Chips 30の会場のSiFiveのブースでは、YOLOv3を使うリアルタイムのオブジェクト検出のデモを行っていた。
-
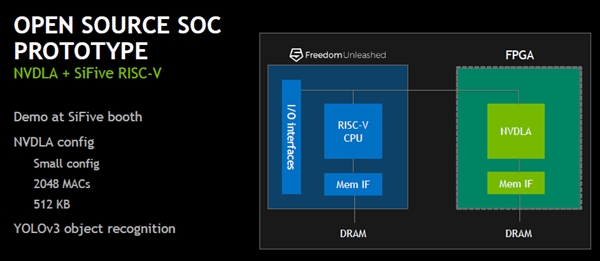
現在、オープンソースで提供を行っているFPGA版のNVDLAとSiFiveのRISC-V CPUを組み合わせたシステム。NVDLAは小規模構成で、MAC数は2048、Conv.Buffは512KBで、Hot Chips 30では、YOLOv3を使ってリアルタイムのオブジェクト検出のデモを行っていた