Hot Chips 30 - 自動運転などの頭脳となるNVIDIAのSoC「Xavier」(前編)はコチラ
新開発のDLAの構造
新開発のDLA(Deep Learning Accelerator)の構造は次の図のようになっており、単なる畳み込み演算を行うMAC(Multiply-ACcumlate)アレイだけでなく、入力や重みを供給するブロックやMAC演算の後のポストプロセスを行うブロックが付いたユニットとなっていて、チップ面積あたりの性能や消費電力あたりの性能を最適化しているという。
Xavierは2個のDLAを搭載し、INT8では11.4DLTops、FP16では5.7DLTopsの性能を持つ。先に書いたように、DLAだけの発表もあるので、詳細は、別のレポートで述べることにする。
-
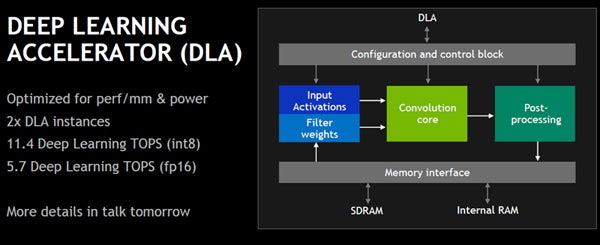
新開発のDLAは面積当たりの性能、電力当たりの性能を最適化しており、INT8では11.4DLTops、FP16では5.7DLFlopsの性能を持つ (出典:このレポートの図は、Hot Chips 30におけるNVIDIAのDitty氏の発表スライドのコピーである)

PVA(Programable Vision Accelerator)は2個のベクタ処理ユニットと2個のDMAエンジンを持ち、イメージ処理やコンピュータビジョンアルゴリズムの処理を行う。なお、Xavierは2個のPVAを搭載している。
-
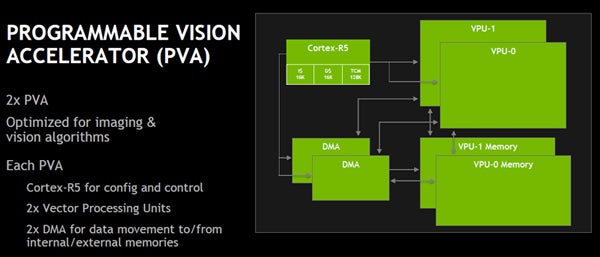
PVAはコンピュータビジョン処理を行うアクセラレータであり、Xavierは2個のPVAを搭載している。各PVAは2個のベクタ演算ユニットと2個のDMAエンジンを持っている

PVAは7命令スロットを持つVLIWアーキテクチャで、1つのVLIW命令は、2つのスカラ命令、2つのベクタ命令、3つのメモリアクセス命令を含むことができ、これらの命令を並列に発行できる。ベクタの長さは256bitで、32×8bit、16×16bit、あるいは8×32bitのベクタとしてデータを扱うことができる。そして、単純なベクタ演算だけでなく、テーブルルックアップ、ヒストグラム、スキャッタなどを行う命令を備え、ハードウェアのループや多次元のアドレス発生機なども備えている。
-

PVAはスカラ2、ベクタ2、メモリアクセス3の合計7つの命令スロットを持つVLIWアーキテクチャのプロセサである

ユニットをどのように使い分けるのか
これだけユニットがあるとどれを使えば良いのか迷いそうであるが、次の図にNVIDIAの推奨の使い分けを示している。PVAはコンピュータビジョンのアクセラレートを行い、DLAはディープラーニングの推論をアクセラレートする。GPUはグラフィックスと汎用の計算を担当する。SOFEは立体視とオプティカルフロー(画像の中の同じ位置の点が次のフレームでどこに移動したかを追跡する)の処理に特化し、ISPとVICは高ダイナミックレンジのカメラ画像処理とレンズひずみの補正の処理に特化している。
なお、ユニットの名前の記述が不統一であるが、SOFEはMM-Acceleratorで、高ダイナミックレンジ処理などは前の図の分担ではISPが担当する。
-

Xavierのそれぞれのユニットの使い分け。PVAはコンピュータビジョンアルゴリズムの実行、DLAはディープラーニングの推論、SOFEは立体視やオプティカルフロー、ISPとVICはHDRやレンズひずみの補正などカメラ画像の処理を行う。GPUは画像表示であるが、他の処理の計算も引き受けるようである

Xavierの性能はどの程度のものか
Xavierの性能を前世代のParkerと比較したのが、次の棒グラフである。左端のCPU性能の比較では、Carmelコアを使うXavierの性能は2倍になっている。そして、ディープラーニングの推論の性能は34DLTopsと25倍に向上している。なお、この34DLTopsという値は、GPUのTensor Coreの部分とDLAのINT8での推論計算の性能の合計である。
3番目は浮動小数点演算性能の比較で、XavierはParkerの12倍となっている。このXavierの性能はIPSとPVAとSMのCUDAコアの性能の合計である。
4番目は立体視やオプティカルフロー、LIDARなどで作られるポイントグラフィックスの処理に使われるLDC(Layered Depth Cube)などの処理ユニットで、その性能は11倍になっている。そして、最後のグラフはDRAMメモリのバンド幅の比較でXavierは137GB/sとParkerの2.3倍になっている。
-
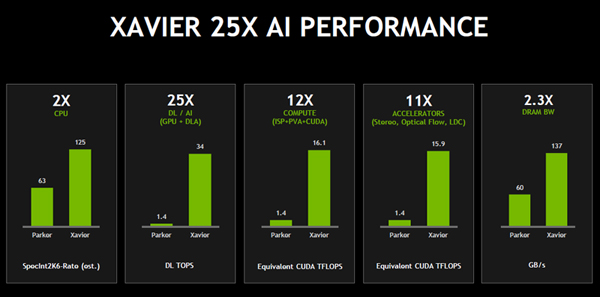
XavierとParkerの処理能力の比較。演算系では11倍~25倍と大幅な向上であるが、CPUは2倍、メモリバンド幅は2.3倍の向上である

Xavierでは20GB/sのNVlinkが追加され、I/Oの性能も大きく向上している。NVLinkはディスクリートGPUの接続と書かれているが、どのように使うのかは明らかではない。そして、PCIeはGen4となり16GT/sと転送速度が倍増した。USBもUSB3.1が3ポート、USB2.0が4ポート、ディスプレイもDP/HDMI/eDPに対応するポートが4ポートとなった。
そして、自動運転で重要なカメラは、シリアル入力のCSIがParkerの12チャネルから16チャネルに増加した。
-

Xavierでは20GB/sのNVLinkがサポートされ、I/Oバンド幅が大きく向上した。そして、PCIeのGen4化、カメラ入力の16チャネルサポートなど、全体的に能力が上がっている

最後にXavierの製品ラインアップであるが、次のように「Jetson Xavier」、「Drive Xavier」、「Drive Pegasus」の3つの形態がある。Jetson XavierはXavierを搭載しただけに近い開発用ボードであるが、Drive XavierとDrive PegasusはNVLinkを始め各種のI/Oポートがコネクタに出ており、自動運転システムが構築できるようになった製品である。Drive PegasusはXavierを2個とハイエンドGPU(Turingかと思われる)を2個搭載した製品で320Topsの性能を持ち、自動運転タクシーなどLevel 5の自動運転が実現できるレベルの性能を持つという。
-

Xavierの製品ラインアップは、開発ボードのJetson Xavier、自動運転用のDrive Xavierと2個のXavierと2個のハイエンドGPUを搭載したDrive Pegasusがある。Drive Pegasusは320Topsの性能を持ち、完全自動運転のレベル5が実現できる処理能力を持つ