NVDLAの構造
NVDLAのハイレベルの構造は次の図のようになっている。上側のControl BusはCPUやマイクロコントローラにつながっており、入力データなどをプロセサから受け取り、NVDLAの処理ブロックに供給する。
Input Activationsと書かれたブロックは、受け取った入力をConvolution Coreに供給する。また、Filter WeightはMemory Interfaceを通してDRAMなどからフィルタ要素の値を読み込む。そして、Convolutionを計算し、その出力にPost-Processingを施す。その出力はメモリに書き込まれ、次の層の入力になる。
NVDLAは、この入力とフィルタの値を一時的に格納するConvolutional Bufferを持っており、このバッファにあるデータはメモリから読むよりも高速に読み出すことができる。
-
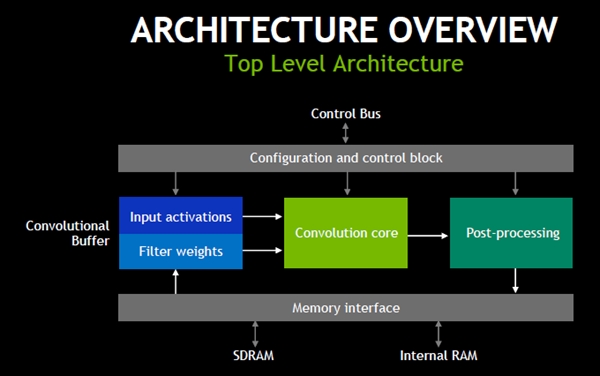
NVDLAのハイレベルのブロックダイヤ。Conv.Bufferは入力とフィルタの要素の値を格納し、畳み込みを計算するデータをConv.コアに供給する。Conv.コアは畳み込みを計算し、その結果をポストプロセスに送る。構成とコントロールブロックはプロセサにつながり、命令の実行や、構成の制御を行う。Memory IFはフィルタの要素の重みの情報やポストプロセスの結果をSDRAMに格納する

NVDLAの構成手法
NVDLAはパラメタ化されたRTLで提供され、Convolutional BufferのサイズやConvolution Coreの持つMAC演算器の数、Post-Processingで扱える処理の種類、メモリの量などをメニューの中から選んでアクセラレータを作ることができる。
Convolutional Bufferの容量を大きくすれば、アクセスするデータはバッファに入っており、SDRAMメモリをアクセスしなくても済むという場合が増える。結果として、うまくバッファを使えば必要なメモリバンド幅を小さく抑えることができる。
Convolutional Bufferが重み全体の1/Nの容量であると、Convolutionを計算するには入力データをN回読む必要がある。例えばGoogleNetのinception 4aという層の処理では、要素のデータは16bitの精度でフィルタは3×3要素である。そして、入力データは1.2MB、重みデータは360KBのサイズである。バッファサイズが128KBの場合、重みは3回に分けて読み込む必要があり、Convolutionの計算には1.2MBの入力を3回読み込む必要がある。つまり、SDRAMには、1層の処理の間に3.6MBのデータが読み込めるバンド幅が必要になる。
なお、Convolutional Bufferは入力と重みを同時に読み出す必要があるので、チップ面積を食うマルチポートメモリセルが必要である。一方、RAMは1ポートでも良く、コンパクトなメモリセルが使える。
-

Conv.Bufferが小さいと、重みを分割して読み込む必要があり、その都度、全部の入力を繰り返して読むことになるので、高いメモリバンド幅が必要になる。しかし、Conv.Bufferは面積を食うマルチポートメモリが必要となるのに対して、メモリはコンパクトなシングルポートでよい

Convolutionalコアの考え方
入力が64要素で、64要素のフィルタを4個使う場合は、64MAC演算を4回行う必要がある。この演算をアトミックに行うため256個のMAC演算器が必要になる。
-
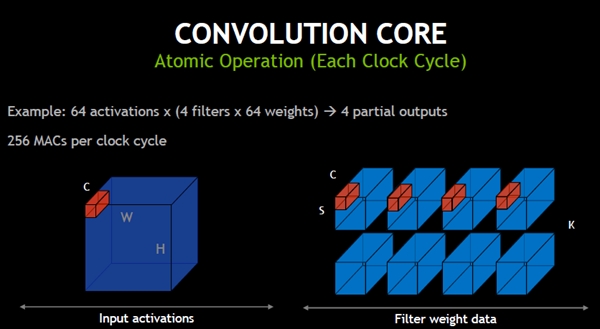
入力が64要素で、4つのフィルタがある場合、256回のMAC演算が必要となる。これをアトミックに実行するには256個のMAC演算器が必要である

Convolutionalコアは、次の図に示すように、フィルタを適用して畳み込みを計算し、次にフィルタを適用する入力位置を矢印のように右へ動かす。これを繰り返して、横一列の畳み込み計算を行う。そして、それが終わったらSwitch Cと書かれているように、奥行き方向にフィルタの適用位置をずらせて行く。
-
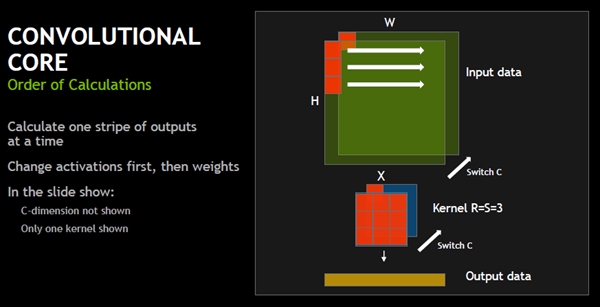
畳み込みコアは、まず、入力の左上にフィルタを合わせて畳み込みを計算し、右へフィルタの位置をずらせながら横一列の畳み込みを計算していく。それが終わると、奥行きのCの方向にフィルタ位置をずらせ、また、横一列を計算しという畳み込み計算を繰り返す

C方向に要素の数が多くなると、より多くの乗算を同時に行い、より多くの積を同時に加算する必要があり、幅の広いWallace Treeが使えるが、境界が整合していないと、より多くのMAC演算器が無駄になると書かれているが、どのような状況を想定しているのか、それがArea and Powerにどのように影響するのか、説明がなく理解できない。
次の、積和演算では重みの方を何回も使いまわして、入力を変えて行く順序で計算すればデータ転送が減り、消費電力を減らせるは理解できる。また、和の計算では、全部の合計を計算してからまるめを行う方が精度が高い。和を何度かに分けて計算するとそれぞれの和を高精度で計算する必要があり、無駄が出るというのも理解できる。
-

C方向の要素数が多ければ、幅広のWallace Treeが使えるが、データの位置が整合していなければムダになるMACが増える。計算の順序としては,重みをConv.Bufferに入れて複数回使う方がデータ転送量が減り、効率が良い。また、全部の和を計算してからまるめを行う方が、演算精度の要求が低く、計算効率が良い

(次回は9月20日に掲載します)