Hot Chips 30で3つの発表を行なったNVIDIA
今回のHot Chips 30において、NVIDIAは3つの発表を行った。その第一が、これから紹介する「Xavier(エグゼビア)」で、2番目がXavierにも組み込まれているディープラーニングアクセラレータの「DLA」。そして3番目がVolta GPUをつなぐネットワークを作る「NVSwith」である。
-

Hot Chips 30においてXavierを発表するNVIDIAのMichael Ditty氏

NVIDIAのXavierは、次の図のような自動運転の車両やドローン、医療機器、ロボットなどの頭脳として使うことを意図して開発された高い画像処理能力と高い推論計算性能をもつSoCである。
-

NVIDIAのXavierは、これらの自律動作するマシンの頭脳として使われることを狙って開発されたSoCである (出典:このレポートの図は、Hot Chips 30におけるNVIDIAのDitty氏の発表スライドのコピーである)

Xavierは、次の図に示すように、CPU、GPUに加えてディープラーニングのアクセラレータであるDLA、プログラマブルな視覚処理アクセラレータのPVA、イメージ処理を加速するISP,さらにマルチメディア処理のアクセラレータと各種のアクセラレータを搭載したSoCである。
それらがTSMCの12FFNプロセスで作られるチップに載っており、さらに強化されたセキュリティ機能やISO 26262やASIL-Cに準拠する安全性や抗堪性を持っている。そして、合計40GB/s以上の高バンド幅のI/Oで外部と接続できるようになっている。
人間の脳の場合は、大脳皮質の部位ごとに処理する情報が異なっているように、Xavier SoCもチップ上の位置で各種の異なる機能のアクセラレータが作られているのは人間の脳に近づいてきたような感じがする。
-

XavierはCPU、GPU以外にDLA、PVA、ISP、MM-Acceleratorという用途別のアクセラレータを搭載し、自動運転用のセキュリティや安全性にも配慮している。

12nmプロセスを採用するXavier
Hot Chipsでは、Xavierチップの諸元が書きこまれた次の図が示された。かなりディテールが描き込まれていて本物かも知れないが、Voltaチップの写真などとはレイアウトを見た感じがまったく異なる。しかし、アクセラレータごとに別の設計チームが担当して、与えられた長方形の領域にレイアウトすると、このようなチップになる可能性は否定できず、本物のチップ写真かアーチストが製作した偽物か判別できない。
もちろん、チップはFace Downでパッケージ基板に取り付けられるので、蓋を取ってもこのようにチップのパターンが見えるのはウソである。
それはともかく、TSMCの12FFNプロセスを使い、チップサイズは350mm2で90億トランジスタを集積する。設計には、おおよそ8,000人年の工数が掛かったという。仮に5年間での開発とすると1,600人のエンジニアチームということになる。これは多すぎるような気もするが、多種のアクセラレータの設計を必要とし、アルゴリズムからプログラミング環境、デバグ環境などの開発を考えると膨大な工数が掛かったことは間違いない。
これだけの開発工数を掛けられる会社は非常に限られるので、この分野でのNVIDIAの優位を覆すのは非常に難しいという感じである。
-

Hot Chipsで発表されたXavierチップ。本物の写真か偽物か分からないが、CPU、GPUや各種アクセラレータの区画が書き込まれ、性能などが書き添えられている

まず、CPUであるが、NVIDIAの自社開発の「Denver」の後継の「Carmel」というCPUコアを使っている。10Wideのスーパスカラで、推定であるが、SpecInt 2006で21の性能を持つという。Intelの4コアのi7-965がSpecInt2006のピーク性能で35程度であるので、このCarmelコアの性能が8コア合計であるとしてもかなりのものである。
Carmelコアの命令アーキテクチャはArm V8.2でRASサポートを含んでいる。自動運転などに用いるチップであるので、RASの充実は必須である。
Xavierでは2つのCarmelコアに2MBのL2キャッシュを付けたクラスタを4個搭載し、チップ全体では8コアとなっている。スマホ用であれば、高性能コア4個と低電力コア4個というような設計になるのであるが、自動運転用のXavierではすべてが同じ高性能コアを8個搭載している。そして、8コアのCPUコンプレックスに4MBのL3キャッシュを装備している。L2キャッシュの合計が8MBであるので、当然、L3キャッシュはInclusiveではなく、Exclusiveキャッシュである。
-

Carmel CPUは2コアに2MBのL2キャッシュを付けたクラスタが4個で作られている。それにExclusiveの4MBのL3キャッシュが付いている

XavierのCPUの性能であるが、現在のDrive PX2に使われているParkerの性能を1.0とした比較が次の図に示されている。それによると、推定値であるが、SpecInt2006-Rateでは2.0倍、SpecFP2006-Rateでは2.8倍となっている。そして、実測のAnTutu6では1.6倍、GeekBench4 multicoreでは1.8倍の性能となっている。
-
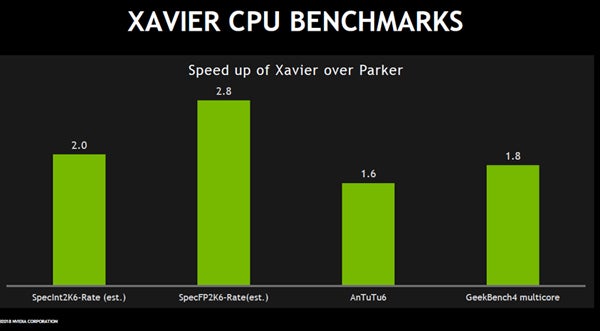
SpecInt2006-Rate、SpecFP2006-Rate、AnTuTu6、GeekBench4でのXavierのParkerとの性能比較。1.6倍から2.8倍に性能が向上している

XavierのGPUは8個のVolta SM(Streaming Multiprocessor)を持っている。ハイエンドのV100 GPUは80個のSMを搭載しているので、Xavierのグラフィック性能はV100の1/10程度ということになる。
L1キャッシュの容量は8倍になり、L2キャッシュのアクセスは4倍速くなったと書かれているが、これはParker世代のGPUとの比較である。
そして、XavierのVolta SMではTensorコアがINT8での積和演算ができるようになり、INT8でのディープラーニングの計算性能は22.6Topsとなっている。なお、FP16での計算性能は2.8 CUDA TFlopsとなっており、これはV100の1/40弱である。
-

XavierのGPUはVolta SM 8個で構成されている。TensorコアはINT8での計算ができるようになり、22.6Topsの性能を持つ

(後編は9月14日に掲載します)