DPU-Vでの処理の流れ
MobileNetでは、まず、層ごとに分解したDepth-wise Convを行い、その後に層間の1×1のPoint-wise Convを行っている。そしてPoint-wise/Depth-wiseのワークロードの比率は棒グラフを見ると3~228まで変動している。このため、DeePhiはDepth-wise ConvとPoint-wise Convの入力バッファを分離し、Depth-wiseは1個のPEで処理し、Point-wiseは4個のPEで並列に処理するアーキテクチャを使うことを考えている。
-
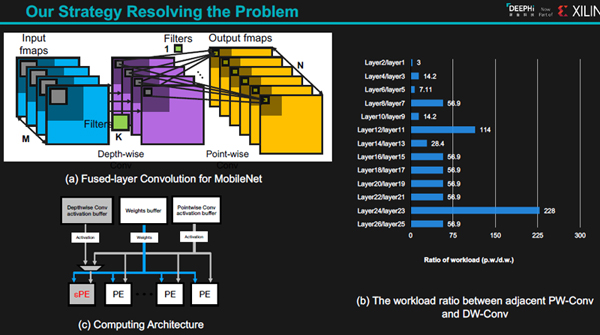
(a)MobileNetなどでは、Depth-wise Convの直後にPoint-wise Conv処理を行っている。(b)各層でのPW/DWの処理量比率。平均的にはPWはDWの50倍程度。(c)DeePhiはDWには1個のPE,PWには全部のPEを割り当てる

DeePhiのZU9を使うアクセラレータには2個のコアが載っており、それぞれのコアが1024KBのBRAMを使っている。VGG-16の場合は87.3%の平均リソース使用率であり問題ないが、Inception-v1では36.7%、ResNet-50では39.3%、MobileNet-v1で45.8%とリソースの利用率が低い。しかし、2048KBのBRAMが使えるとして、Depth-wise層とPoint-wise層を融合して処理を行うと、シミュレーションの結果では、Inception-v1は72.1%、ResNet-50は63.9%、MobileNet-v1は63.9%までリソース使用率を高めることができる。
-

上のグラフは各コアが1024KBのメモリが使える場合のリソース利用率。VGG-16は87.3%と利用率が高いが、その他の3つのネットは40%前後の利用率に留まっている。これが各コア2048KBのメモリを使えると、処理の融合ができ、リソース利用率を大きく改善することができる

DeePhiではDNNDKという開発環境を提供している。DNNDKは、精度に大きな影響を与えない範囲で、非常に重みの値が小さい枝を削除するプルーニング(枝刈り)や重みの値を量子化し、FP16での処理をINT8での処理に変更するようなネットワークの簡素化を行う。これで必要なメモリを削減し、計算速度が向上し、消費電力も減らせる。
-

DeePhiは、枝刈りや量子化などで重みの数はビット数を減らす圧縮を行う。そしてコンパイラでメモリ割り付けなどを最適化したコードを生成する。そして、コードの実行やトレースを見るツールなどをDNNDKに入れて提供している

DNNDKの中にあるコンパイラは、次の図に示すようにいろいろな形の層の処理を融合して最適化を行う。また、メモリ割り付け、スケジュール、再利用を促進して実行性能を改善する。
-

コンパイラは、垂直、水平の処理層の融合や組み換えを行って実行効率を改善する。また、メモリのアロケーションなどを変更して実行効率を改善する

これからのディープラーニングに有利なFPGA
まとめであるが、ディープラーニングのアルゴリズムの進化の速度は加速している。最近のMobileNetなどでは、昔のネットワークに処理に特化したアクセラレータではうまく高速化できないタイプの処理が増えてきている。
このため、DeePhiはコンパイラの最適化でDepth-wiseとPoint-wiseの畳み込みの処理を高速化するというアプローチを提案する。また、今後出てくる新しいネットワークに対しても新しい最適化法を考える必要がある。
ASICのアクセラレータは、設計や製造に時間が掛かるので、進化の速度は遅くなってしまう。これに対してFPGAを使うアクセラレータは構成を変えるたけで最新のディープラーニング技術を利用することができる。
-

ディープラーニングのアルゴリズムは急速に進歩しており、古いネットワークの処理を高速化するアクセラレータではうまく高速化できない。ASICの開発、製造は時間が掛かるので、アルゴリズムの進化に追従できない。その点、FPGAはプログラマブルで最新のDL技術に追従できる。性能の改善技術として、DeePhiは処理層の融合が効果的であると考える

DeePhiは新しいアルゴリズム、新しいアクセラレータを追求する会社であり、急速なディープラーニングの進歩に追従できるFPGAの方がASICやGPUなどを使うよりも効率的であると考えている。