NVSwitchの詳細が公開
NVIDIAは8個のV100 GPUを搭載するDGX-1サーバに続いて、2018年3月のGTC 2018で16個のV100 GPUを搭載するDGX-2サーバを発表した。このDGX-2サーバの高いスケーラビリティを実現した影の主役がNVSwitchと呼ぶNVLinkを接続するスイッチチップである。
NVIDIAはHot Chips 30において、このNVSwitchについて発表を行った。これはNVSwitchに関する初めての学会での詳細な発表である。
-

Hot Chips 30においてNVSwitchの発表を行うNVIDIAのAlex Ishii氏

NVSwitchの概要
次の図に示すDGX-1の8個のV100 GPUの間の接続は、4個のGPUの範囲では、NVLinkの直結の接続があるが、反対側の4個のGPUの間では直結の接続が無く、本来無関係なGPUを1個経由しないとデータが送れないGPUがある。また、GPUペア間に2本のNVLinkが並列にあるところや1本しかないところがあり、通信環境が一様ではない。このような構造では、一番弱いところが性能の制約になることが多い。
-

DGX-1の接続図。緑の太い接続がNVLinkで紫の接続はPCI Expressである。4個のV100の接続はキューブであるが、左右の4個のペアの接続はメッシュになっている (出典:https://www.nvidia.com/ja-jp/data-center/nvlink/

DGX-2で16個のGPUの間を、より均等でバンド幅の大きい接続を実現するためにNVIDIAが開発したのがNVSwitchである。
次の図はDGX-2サーバの概要を示すもので、16個のTesla V100 GPUを10Uのサーバ筐体に収容し、10kWのピーク電力を必要とするサーバである。そして、新開発のNVSwitchを12個使用して2.4TBpsのバイセクションバンド幅のファットツリーネットワークを実現している。
-

NVIDIAのDGX-2サーバの概要。32GBのメモリをもつV100 GPUを16個搭載するサーバで、NVSwitchで16個のGPUは全GPUのメモリをアクセスすることができる (出典:この連載の図は、Hot Chips 30におけるNVIDIAのAlex Ishii氏の発表スライドのコピーである)

CPUに1個のGPUだけが接続されている場合は問題ないが、次の図のように2個のGPUが接続されると、GPU0がGPU1に接続されているHBM2メモリをアクセスするにはPCIeを経由する必要がある。このアクセスはCPUが行っている他の処理に影響を与え性能をばらつかせる。
-
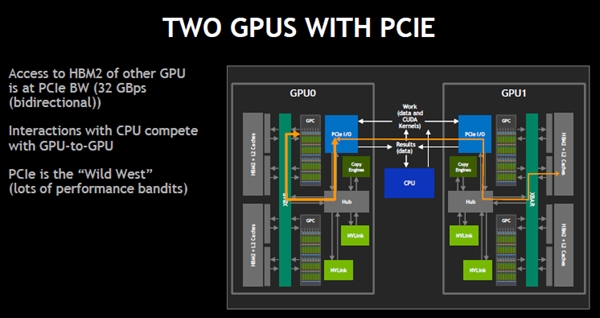
PCIeで2台のGPUを結合した場合は、GPU0がGPU1のHBM2をアクセスすると、そのデータ転送はPCIe経由になり、GPUの処理に影響を与え、性能のばらつきなどが生じる

ここでNVLinkを追加すると、次の図のように、他方のGPUに接続されたHBM2のアクセスは300GB/sという高バンド幅のNVLink経由になり、PCIeのトラフィックには影響しない。実効的に、NVLinkがHBM2をつなぐXBARの間のブリッジになっている。
-
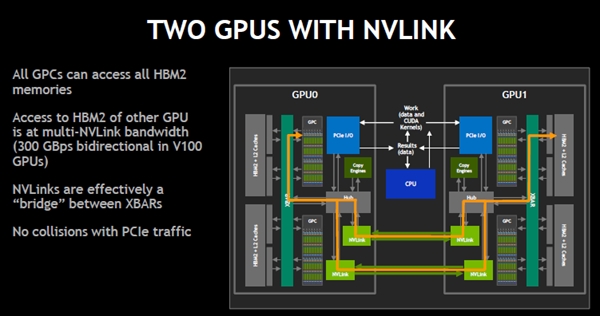
NVLinkを使って2つのGPUを接続すると、両方のGPUのXBAR間を接続するブリッジとなり、HBM2へのデータ転送はCPUのPCIeのトラフィックの邪魔にならない

つまり、NVLink接続とXBARとHBM2全部が一体となった大きなメモリとなり、それを16台のGPUがアクセスするという理想的な形態になる。
-
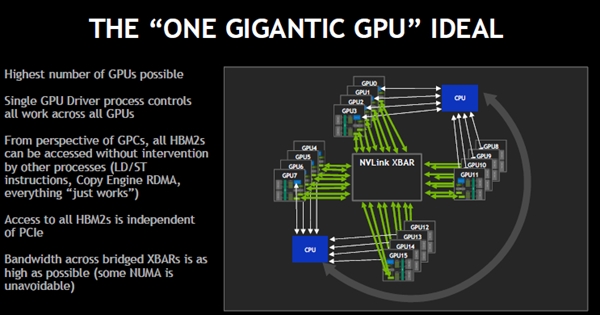
NVLinkが全部のGPUの内部のXBARを接続して大きな一体のメモリを形成している

NVSwitchの構造
次の図の上側にある非常に横長の写真がNVSwitchチップのダイ写真である。左右に8ポートずつのポートのSERDESなどがあり、中央にXBARがある。そして中央の上の部分に2ポート分のSERDESなどがあり、合計で18ポートのスイッチになっている。
チップはTSMCの12FFNプロセスで作られており、チップサイズは106mm2で20億トランジスタを集積する。NVLinkの1リンクのバンド幅は51.5GBps(双方向合計)となっている。
-

上がNVSwitchチップのダイ写真である。左右に8ポートずつのSERDESがあり、中央にXBARがある。なぜか中央の上のところに2ポート分のSERDESがあり、18ポートのスイッチになっている。TSMCの12FFNプロセスで作られ、チップサイズは106mm2である

NVSwitchのブロックダイヤを次の図に示す。NVSwitchはGPUのXBARの間をブリッジするスイッチとして設計されたものであり、汎用のネットワークのスイッチではないという。ポートロジックの中のPacket Transformは複数のGPUからのトラフィックを1つのGPUからのトラフィックのようにまとめて扱う。
XBARはノンブロッキングで、送れないパケットがあってもそれを仕掛りにして、後続のパケットの処理を先に行い、伝送効率を高めている。
-

NVSwitchのブロックダイヤ。物理層からトランポート層までを含むLinkモジュールとルーティングやエラーチェックなどを担当するポートロジックを18対持ち、それらが18×18のクロスバにつながっている。

NVLinkはGPUの中のGPCが持つアドレス変換機能を使って、物理アドレスに変換を行っており、物理アドレスのシェアードメモリとなっている。そのため、NVLinkのパケットは物理アドレスの情報を含んでいる。
-

NVLinkはシステム内でユニークとなる物理アドレスを使っている。アドレス変換は、GPCの中にあるアドレス変換機能を使って行われる

NVLinkは筐体内の非常に短距離のリンクで、10-12以下という低いビットエラー率であるので、FECのような訂正能力は高いがオーバヘッドの大きいエラー訂正は必要ない。このため、CRCによるホップごとのエラーチェックを使い、エラーが見つかった場合は再送で訂正を行う。
-

NVLinkは筐体内の短距離伝送であり、ビットエラー率が低いので、CRCによるエラー検出と再送による訂正で信頼度を確保している

NVSwitchのチップ形状
普通、チップは正方形に近い方が配線長が減るので望ましいが、NVLinkチップは極端に扁平な長方形になっている。このチップは、ポートの部分がチップの大部分を占めており、面積に対して周辺長を長くした方がパッケージ基板上の配線がやり易いので、このような形状のチップになっている。
-

I/O回路が大部分を占めるチップであるので、チップ面積に対して周辺長の長いチップの方が、パッケージ基板の配線がやりやすい。このため、NVSwitchチップは扁平な長方形になっている

スイッチを使うと、次の図のような接続が可能となる。この図は3個のNVSwitchを使って8個のGPUを2本ずつのNVLinkで接続している。この接続では、すべてのGPU間は2本のNVLinkで結ばれており、最初に示したGDX-1のスイッチチップを使わない設計に比べてよりバランスのとれた設計になっている。
-
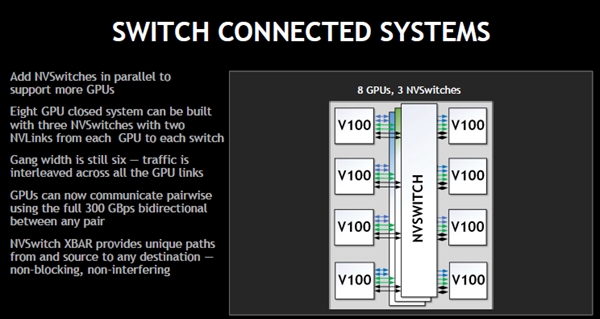
NVSwitchを使うと、どのGPUペアの間も2本のNVLinkで接続することができる。さらにNVSwitchはノンブロッキングであるので、他の通信を邪魔しない

DGX-2のNVLinkネットワークは、 次の図のように接続されている。前の図のようにNVSwitchの両側にV100 GPUを接続すれば、6個のNVSwitchで良いのであるが、2枚の同一のボードに分割して作るために、各ボードに6個のNVSwitchを搭載し、対応するNVLinkのポートは直結している。
-

DGX-2では2枚の同一の8GPUボードで16GPUシステムを作るため、各ボードに6個のNVSwtichチップを搭載する設計となっている

(次回は9月21日に掲載します)