プログラマブルなポストプロセス処理部
Arm MLPでは、ワークセットをSRAM内に保持するようにスケジューリングを行ってDRAMへのアクセスを減らしている。
また、複数の出力を同じ入力から計算したり、MACとPLE(Programmable Layer Engine)の処理をパイプライン化して中間結果のメモリへの格納を省いたりして必要なバンド幅を低減している。これらは静的なスケジューリングを行っているから可能になっている。
-
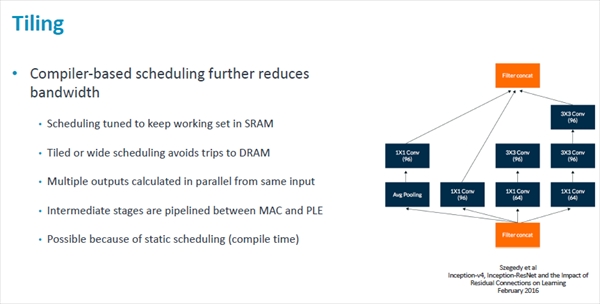
タイリングは、SRAMへのデータの格納をタイル単位で行い、SRAMの利用率を高め,DRAMアクセスの回数を減らす。また、同じ入力データを複数回使ったりMACとPLEをパイプラインで動かして中間結果のSRAMへの格納を除くなどで、必要なSRAMバンド幅を減らす

ニューラルネットワークの進歩は続いており、現在とは異なる形のネットワークが使われるようになる可能性がある。このため、ポストプロセスを行う部分をプログラマブルな機能を持つProgrammable Layer Engine(PLE)としている。
-
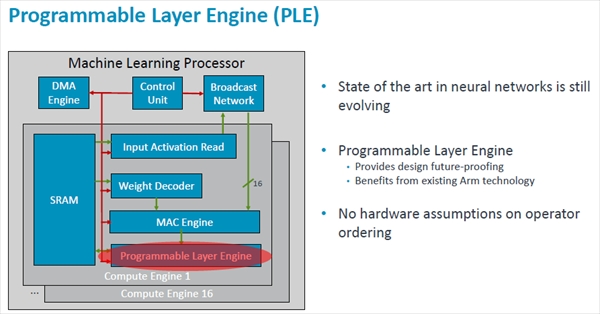
ニューラルネットの進歩は続いており、将来、新しい計算が必要となる可能性がある。これに対応するため、ポストプロセスを処理する部分はプログラマブルなエンジンとしている

柔軟な性能向上が可能なMLプロセサ
Arm CPUのアーキテクチャをベクタ処理とニューラルネットワーク処理のために拡張を行ったとのことで、ニューラルネットワーク関係では、プーリングやRelu処理などの畳み込み以外の処理を行えるように拡張したという。
次の図のように、PLEはCPUを持ち、それにベクタエンジンとSRAMが付いている。処理するデータがMACエンジンから出力されると、割込みでCPUにPLEの処理の開始を依頼する。
大部分の処理は16レーンのベクタエンジンで1サイクルで処理される。しかし、命令によっては複数のベクタエンジン命令を実行する必要がでると思われるが、プログラマブルの柔軟性を実現するためにはやむを得ない。そしてPLEの中のローカルSRAMに格納されたPLEの処理結果は、マイクロDMAを使ってMLPのSRAMに転送されて畳み込みなどに使えるようになる。
-
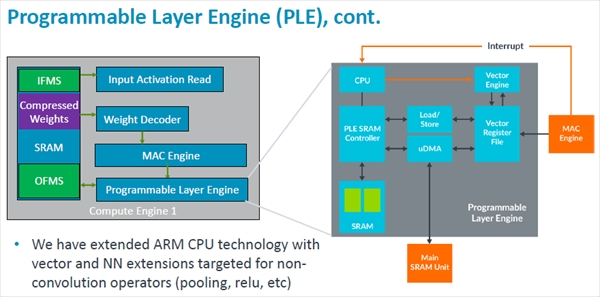
PLEはCPUを持ち、それにベクタエンジンとローカルSRAMが付いている。MACが計算を終わるとその結果はベクタレジスタファイルに転送され、PLEでの処理要求を割込みで通知する。ベクタエンジンは、マイクロコードで処理を行い処理結果をローカルSRAMに格納する

-

PLEによるポストプロセス処理は、大部分の処理は1サイクルで実行できるが、将来の機能拡張では複数サイクルを必要とすることも考えられる。計算結果はローカルSRAMに格納され、マイクロDMAでCEのSRAMに転送される

さらに性能を上げる必要がある場合は、CEの個数を増やす、MACエンジンのスループットを増やす、MLPの個数を増やすという方法が考えられる。
POPの場合は物理設計が終わっているので変更はできないが、Armのライセンスは基本的にRTLレベルであり、CEの数を変えたり、MACエンジンの数を変えたりという変更が可能である。
-
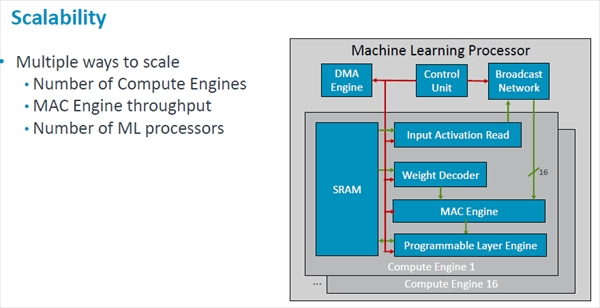
ArmのライセンスではCEの数やMACエンジンの数を変えたりすることができ、性能のスケールアップやスケールダウンができる

第1世代は2018年中のリリースを予定
まとめであるが、ArmのMLプロセサは16個のCE(Compute Engine)を持ち、1GHzクロックで約4Topsの演算性能を持つ。演算は8bit整数で行う。CEに搭載するSRAMは1MBである。
そして、7nmプロセスを使う場合、チップ面積は約2.5mm2で、電力効率は3Tops/Wを超えることを目標としている。
TensorFlowやCaffeなどのフレームワークソフトウェアとのインタフェースはAndroid NNAPIとArmNNをサポートする。
リリース時期は2018年と書かれており、間もなくリリースされると思われる。
-

Arm MLPは~4Topsの演算性能を持ち、3GTops/Wを超える電力効率を目指している。Android NNAPIとARMNNをサポートする。リリースは2018年となっており、間もなく公表されると考えられる

なお、ArmはNVIDIAのNVDLAのサポートを表明しており、第2世代のArm MLPがこのチップの延長になるのか、それともNVDLAになるのか、それとも第3の別物になるのか興味深い。ディープラーニング用の推論コアを開発している会社だけでも十指にあまる状況で、これ以上、種類が増えられても……という気もする。