



クラウドからエッジへ
自動運転は、演算レイテンシの短縮、最小のサイズ、軽量化、省電力化の重要なニーズを理解するのに最適な例です。レーダーやカメラによって検出したオブジェクト(他の車、自転車、歩行者など)は検出後、直ちに特定される必要があります。
-

自動運転の物体検出イメージ

人間が視覚入力に反応する速度は約4分の1秒以内であることが知られていますが、自動運転システムの実現には、少なくともこの人間と同じ、理想的にはそれを上回る速度で視覚認識ができることが求められることになります。そのため、人間のドライバーに匹敵する自動運転システムを実現するためには、たとえば、緊急ブレーキの判断、物体を検出して、認識し、ブレーキを効かせる処理まで1.5秒未満で行う必要があります。
-

CPU/GPUを用いた推論処理のレスポンス時間と、FPGAを用いた推論処理のレスポンス時間の差のイメージ

Xilinxは2018年、メルセデス・ベンツ(ダイムラー社)の研究開発部門と共同で、FPGAベースの深層学習プロセッサを開発し、カメラ、レーダー、LiDARからのデータを解析してドライバモニタリング、車両誘導、衝突回避に役立てることを発表しました。両社の専門家が適応性の高い車載プラットフォームにAIアルゴリズムを実装しており、メルセデス・ベンツのニューラルネットワーク用に深層学習プロセッサテクノロジを最適化する予定です。そのテクノロジは、極めて低いレイテンシと高い電力効率を同時に可能にし、熱的制約の厳しい車載環境において高い信頼性で動作するシステムを実現します。
またデータセンターにおいても、一般的なGPUベースのプロセッサで実現可能なワットあたりの性能のレベルを超えて動作する深層学習アクセラレータがFPGA上にホストされるようになってきています。SK Telecom社では、Kintex UltraScale FPGAをデータセンターのAIアクセラレータとして導入することにより、音声起動アシスタントであるNUGUの性能が向上しました。
これは韓国の通信業界にとって初めてのAI導入であり、SK Telecom社の自動音声認識(ASR)アプリケーションを従来のGPUベースのプロセッサと比べて500%高速化しました。ワットあたりの性能は16倍に向上しています。さらに、既存のCPUのみのサーバにアクセラレータを追加して複数の音声チャネルを処理するようにしたことで、同社の総保有コスト(TCO)の削減にもつながりました。
もう1つの例は、最新のAIベースのホームセキュリティです。FPGAによって高速化された低レイテンシの推論は、この新興市場をリードする企業の1つであるTend Insights社と共同開発したクラウドプラットフォームの一部として、よりスマートな監視や、在宅介護などのサービスを可能にしています。
家中に配置されるカメラの基本的な機能は、有事の可能性がある出来事を含むフレームを特定して、クラウドで実行されるFPGAベースのAIアクセラレータにアップロードすることです。アクセラレータには一連のAPI(この場合はXilinx ML Suiteハードウェアコンパイラ)を介してアクセスできます。
AIアクセラレータは不審な人や動物と、家族の一員やペットとを区別し、脅威が検出されるとアラートを出します。オーナーの許可の下、室内カメラによるフレームも解析され、高齢者が転倒したり、介助が必要であるなど、困難な状況にある家族を特定します。その上で、指定された家族や専門の介護士にシステムから電話をかけるなどして、支援を要請することができます。
この他にも、複雑なパターンマッチングや画像認識を実行して、より迅速に結果を取得するためにAIが利用されている例は多数あります。医療診断や治療をスピードアップするためのゲノム解析もその1つです。この分野では、FPGAを使用してAIの推論を高速化することで、患者のゲノム配列の解析と根本原因の特定にかかる時間は24時間から約30分に短縮されました。そしてさらなる短縮を目指して競争が始まっています。
また、次世代エネルギーである核融合の研究でも活用されています。この実験では、1億ピクセル/フレームにも及ぶ高精細な画像を、約25ms以内にキャプチャする必要があります。これは、低レイテンシ・ニューラルネットワークによる検出が求められますが、従来のCPUベースの推論では難しい課題です。実際のところ、桁違いに短い時間での処理ですが、そうした分野ですでにFPGAベースのAIは活用され、科学者の適切なニーズに応える手助けをしています。
-
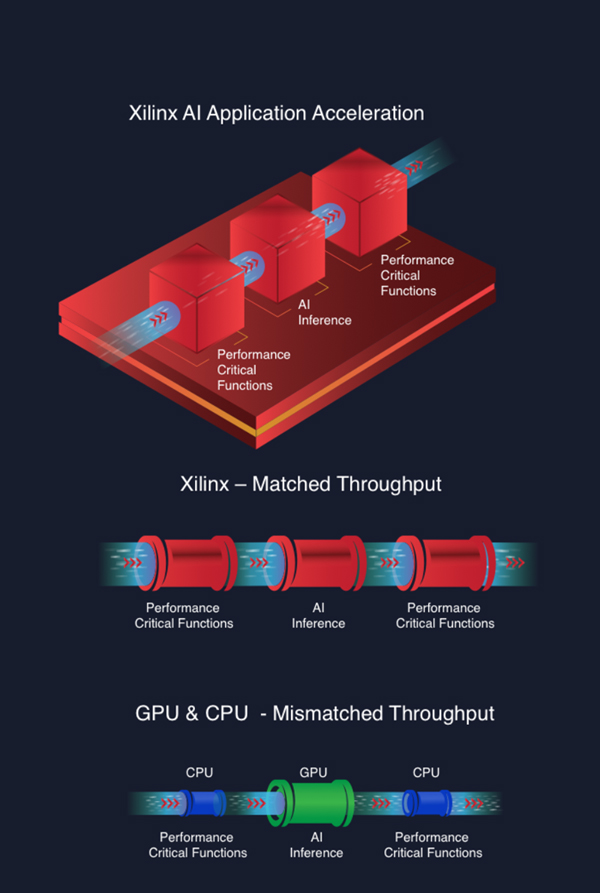
アプリケーション全体をFPGA内で処理することで、AI推論とその他の性能を重視した機能の両方を最適化したアクセラレーションが可能となる

結論
現在、世界から注目を集めているAI技術はつい最近になって実用化されたものばかりであるにも関わらず、すでに人々が日常的に行うサービスを支える技術として使われています。
運用コストの削減、お客様の待ち時間の短縮、新たな付加価値サービスの創出といった展望は企業にとっては非常に喜ばしいことであり、レイテンシ、消費電力、コストを削減してパフォーマンスを向上し続けることへのプレッシャーは高まっています。
そんなAIの開発には2つの側面があります。1つ目は目の前のタスクに最適なニューラルネットワークを学習させること、2つ目は学習済みのネットワークをプルーニングおよび最適化し、適切なプロセッサにホストされた推論エンジンとして実装することです。
FPGAアーキテクチャの有する柔軟性と性能、高性能なツール群(ML SuiteハードウェアコンパイラやDeePhiオプティマイザーなど)によるインプリメンテーションと最適化、シリコン設計のやり直しを待たずに最新のニューラルネットワークアーキテクチャを実装できる柔軟性は、クラウド、ネットワーク、およびエッジにおけるAI推論アクセラレーションを実現するために欠かすことのできない3つの要素となっています。
著者プロフィール
Daniel Eaton(ダニエル・イートン)Xilinx
戦略マーケティング開発
シニア マネージャー












