アヴネットは12月7日、「ハイパフォーマンス・エクストリームコンピューティング・セミナー」を開催。次世代コンピューティングプラットフォームとして注目を集めつつあるFPGAについて、次世代コンピューティング関連のビジネス開発責任者やエンジニアなどに向け、紹介を行なった。
-

ハイパフォーマンス・エクストリームコンピューティング・セミナーの様子

スーパーコンピュータ(スパコン)やクラウドコンピューティングといったハイパフォーマンスコンピューティング(HPC)分野では近年、アクセラレータの活用が進んできている。よく知られているところでは、AI(人工知能)の学習にGPUを活用するといったものがあるが、アクセラレータとしてはGPU以外にもFPGAや各社が独自に起こしたASIC(例えばGoogleのTPU)なども活用されつつある。
FPGAは、かつては通信基地局市場を主な市場としてきており、同市場は5Gに向け、変わらず主要な市場として君臨しているが、近年、その適用範囲を拡大させつつある。HPCもその1つで、Intel(旧Altera)は2018年4月に、サーバ向けにPCIe経由でFPGAの活用を可能とする「PAC(Programmable Acceleration Card)カード」をアナウンス。遅れてXilinxも2018年10月に、これまで水面下ではパートナーのメガクラウドベンダーなどに提供してきたPCIeタイプのアクセラレータカードを、正式に「Alveo」という名称をつけて提供していくことをアナウンスするなど、市場の浸透に向けて、ソリューションの整備が進められつつある。


セミナー会場にて行なわれていたAlveoを用いたデモの様子


「自分たちのアプリケーションをアクセラレーションしたい理由はいろいろと考えられるが、大きく分けて2つ理由がある。1つは、データ爆発。もう1つはAI技術の活用のため」(ザイリンクス担当者)であり、こうしたニーズへ対応することを目的にAlveoが開発されたとする。
FPGAは、動作周波数事体はCPUやGPUのようなGHzオーダーではなく、頑張ったところで数百MHzオーダー程度であるが、並列度はロジックが許す限り増やすことができる。また、アーキテクチャもノイマン型にこだわる必要はなく、特定の処理のみを専門に行なうコアを複数種類用意して、コンベアのように、それらが次々と処理を流れ作業で行なっていくことで、高速演算が可能になることが特徴となっている。
-

CPU、GPU、FPGAの違い

この特定の処理を行なう専門コアの存在が重要で、要件に応じて自由にカスタマイズすることができることが、アルゴリズムが日進月歩で進化するAI分野で、回路そのものを変えて試すことを可能としている。
-

FPGAの機械学習分野におけるメリット。日々進化するAI分野のさまざまなアルゴリズムを柔軟に対応できるほか、1チップからシステムレベルまで、幅広いシステムに対して同一アーキテクチャで対応することができる

元々FPGAはVerilogやVHDLなどのハードウェア記述言語で回路を設計する必要があった。しかし、近年、適用アプリケーションの拡大に併せて、FPGAに触れるエンジニアもソフトウェア関係の人が増えてきたということもあり、より高位な言語での記述を可能としたSDxといったソリューションをXilinxでは提供するようになってきたほか、ディープラーニングをより簡単に実現できるようなツールキットやIPの拡充も図ってきたという。
例えば「xfDNN」と呼ばれるツールキットにはPythonのAPIやコンパイラ、ランタイムなどが含まれており、命令コードの作成や、レイヤを統合する最適化、浮動小数点演算から8/16ビットの整数演算への変換などを可能としている。
-

「xfDNN」ツールキットの概要

こうした機能を活用し、FPGA上に実装されたxDNNプロセッシングエンジンを用いて(xDNN自体はAWS EC2などのクラウド環境でも利用可能)、GoogleLeNetによる推論を実行した場合、一例だが、Alveo U200にて、1秒間に3000枚の画像を処理することができたという。
-
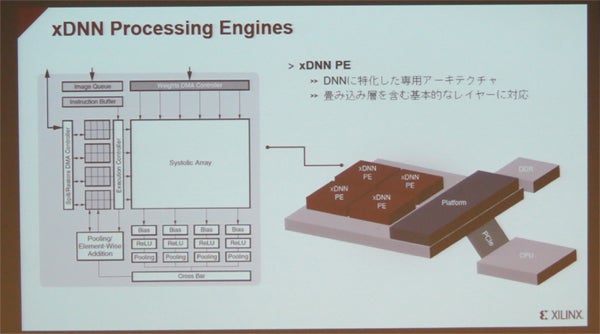
xDNNプロセッシングエンジン

また、実際に並列アーキテクチャを活用してハードウェア/ソフトウェア性能を発揮するためには、データ(配列)のサイズ、データ転送効率、FPGAカーネルの性能の3つの要因を検討する必要があるとするほか、これらを考慮しつつ、タスク間ならびにタスク内の粒度レベルの異なる2つの観点を備えた並列化が可能なアーキテクチャを考えることで、性能と消費電力の両面での優位性を発揮できるようになるとする。
-
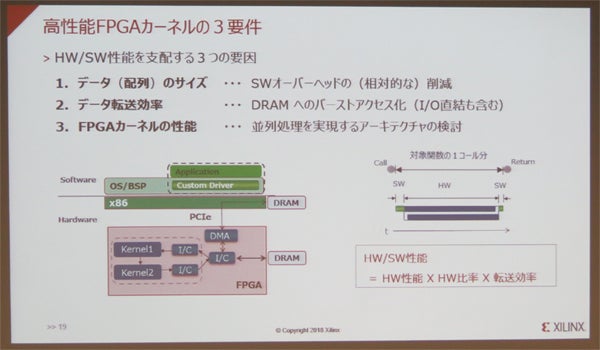
FPGAの性能を決定する3つの要因

例えば、FPGAからFPGAにタスクを順に渡していく場合、一度DRAMを介して行う以外にも、深いパイプラインを経由させることで、DRAMを介さずに行なうことも可能であったり、別々のDRAMを介して次のFPGAにデータを引き渡したり、といった工夫を施すことで、イタレーション間の依存性問題を回避することができるようになるという。
Xilinxでは、性能と消費電力を両立させるためには、単に演算器だけを並べても意味はなく、DRAMアクセス効率の最適化や、並列アーキテクチャの最適化などを考慮したコーディング作業が重要になってくると説明する一方で、実行したいアプリケーションの処理に対応するIPや汎用ライブラリをサードパーティ製のものを含めてラインアップの拡充を図っていることから、さまざまな機能を自身でスクラッチで開発する必要もなくなってきていることを強調。今後も、そうした周辺環境の整備などを推し進めていくことで、より平易にFPGAというデバイスを意識せずに、よりユーザーが実現したいことに対する手助けができればとしていた。

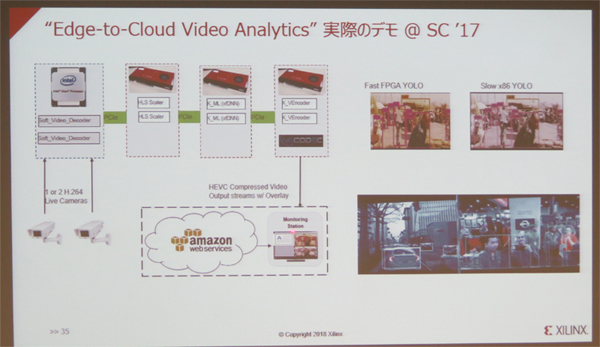
FFmpegのアクセラレータ化に向けたブロック図とSC17にて行なったFPGAを用いたデモの概要