今回もテキストから必要な部分を抜き出すcutコマンドです。前回は文字列から文字を抜き出しましたが、今回はファイルから文字列を抜き出します。

今回もこれまでのようにサンプルで利用するファイル・ディレクトリはデスクトップのsampleディレクトリとしています。デスクトップにsampleディレクトリがない場合は作成しておいてください。(コマンド入力ならmkdir ~/Desktop/sampleとして作成することができます)
また、カレントディレクトリも上記の場所になります。cd ~/Desktop/sampleのようにコマンドを入力してカレントディレクトリを変更しておけばよいでしょう。


ファイルから指定した文字数を抜き出す
まず、テキストファイル内から指定した文字数だけ抜き出してみましょう。この場合、cutコマンドは最後のパラメーターにファイルパスを指定します。
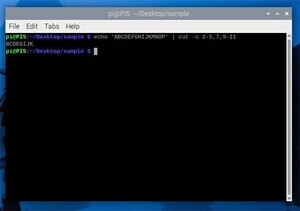
以下のように指定するとカレントディレクトリにある1.txtファイルの2文字目が表示されます。
1.txt
ABCDEFGHIJKMNOP

cut -c 2 1.txt


複数行ある場合は各行の2文字目が表示されます。Unicodeに対応している環境であれば日本語はもちろん絵文字も正しく表示されます。そうでない場合は正しい表示になりません。
2.txt
ABCDEFGHIJKMNOP
春はあけぼの
いろはにほへと
😀🐹⚽️🇯🇵

cut -c 2 2.txt


2文字目と4文字目を抜き出すこともできます。ここらへんは前回の指定方法と同じです。
cut -c 2,4 2.txt


範囲を指定して抜き出す場合は以下のようになります。これも前回の指定方法と同じです。
cut -c 1-3 2.txt


ファイルから1列だけ抜き出す
cutコマンドはファイルから特定の位置の文字を抜き出すだけでなくファイルの列単位で抜き出すこともできます。例えばエクセルから出力されたタブ区切りテキスト(CSVだと問題が発生することがあるのでコマンドで処理する場合はタブ区切りテキストの方が安全)から特定の列だけを抜き出して、まとめて1つのファイルにすることもできます。
まず、使用するタブ区切りテキストの内容は以下のようになっています。
3.txt
1 18.4 A1地点 北海道
2 18.9 B2地点 青森
3 16.0 C3地点 長野
4 9.2 A4地点 長崎
5 6.1 B5地点 山梨
6 -0.3 C6地点 香川
7 -6.5 D7地点 静岡
8 -1.2 E8地点 宮城
9 0.01 X9地点 鳥取
10 3.8 ZA地点 島根

まず先頭の列を抜き出してみます。列を指定するには以下のようになります。
cut -f 1 3.txt


2番目の列を抜き出す場合は以下のようになります。
cut -f 2 3.txt


タブ区切りテキストではなく,区切り(CSV形式)や任意の文字で区切られている場合は-dを指定し直後に区切り文字を指定します。
4.txt
1,18.4,A1地点,北海道
2,18.9,B2地点,青森
3,16.0,C3地点,長野
4,9.2,A4地点,長崎
5,6.1,B5地点,山梨
6,-0.3,C6地点,香川
7,-6.5,D7地点,静岡
8,-1.2,E8地点,宮城
9,0.01,X9地点,鳥取
10,3.8,ZA地点,島根

cut -f 2 -d , 4.txt


タブ区切り文字の場合は単純に指定するとエラーになるので以下のように指定します。
cut -f 2 -d $'\t' 3.txt


複数の列を抜き出す
cutコマンドは複数の列を抜き出すこともできます。例えば以下のようにすると1列目と3列目が抜き出されます。
cut -f 1,3 3.txt


2列目だけ不要で他の列を抜き出す場合は以下のようになります。
cut -f 1,3- 3.txt


ここで最後の列を抜き出したい場合は困ってしまいます。cutコマンドには最後の列を指定する方法がないためです。一番手軽なのはawkを使って最後の列を抜き出してしまう方法です。以下のようにすると3.txtの最後の列が抜き出されます。
awk '{print $NF}' 3.txt


最後の列ではなくて最後から2番目の列を抜き出したい場合は以下のように指定します。NF-1の1が最後からの列のカウント(最後から2番目)になります。ここを2にすると最後の列から3番目を示すことになります。
awk '{print $(NF-1)}' 3.txt


ここらへんは状況に応じて使い分ければよいでしょう。


列の順序を入れ替える
それでは次にcutコマンドを使って列の順序を入れ替えてみましょう。ここでは3.txtファイルの2列目と3列目を入れ替えたファイルを作成してみます。
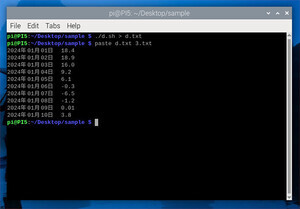
順番に処理していきましょう。まず、cutコマンドで1,2,3列目を抜き出して1t.txt,2t.txt,3t.txtという名前のファイルで保存します。
cut -f 1 3.txt > 1t.txt
cut -f 2 3.txt > 2t.txt
cut -f 3 3.txt > 3t.txt


次にpasteコマンドを使って1,3,2の列順にして結果をファイルに書き出します。ここではdata.txtというファイル名で書き出しています。
paste 1t.txt 3t.txt 2t.txt > data.txt


前回のprintfコマンドと組み合わせれば小数値を整数値に変換してから列を入れ替えたファイルを作成できます。
cat 2t.txt | xargs printf '%.f\n' > 2tt.txt
paste 1t.txt 3t.txt 2tt.txt > data.txt


列内のデータを処理せずに単純に順次を入れ替えるだけならもっと簡単な方法があります。awkを使えば以下のようになります。$1が元の1列目、$2が元の2列目、$3が元の3列目を示しています。printの後に書き出す列の順序を指定します。
awk '{print $1, $3, $2}' 3.txt


おまけ
最後におまけで少々。カレントディレクトリ内にあるテキストファイルの先頭5文字目までを抜き出して表示するには以下のように指定します。ファイルのイントロ部分だけ見たい場合に使えます。lessやmoreなどのページャコマンドと組み合わせてもいいでしょうし、ファイルに書き出してゆっくり確認するのもよいでしょう。
cut -c 1-5 `find . -name "*.txt"`


先ほど列の入れ替えをしましたが、場合によってはファイル内容の行を逆順にしたい場合があります。LinuxとmacOSでは使うコマンドが異なります。Linuxではtac(これはcatコマンドの文字を逆にしただけ)コマンドを使います。
tac 3.txt

macOSの場合はtailコマンドを使います。tailコマンドについては、またいつか説明します。
tail -r 3.txt

UNIXでのコマンドはシンプルなものが多くあります。これらを組み合わせることで様々な応用ができるのですが、実際にはこのような細かいコマンドの組み合わせは人によっては好まれないようです。初心者ほどボタン1発でできるようにしてくれ、などと言われます。ですが、ボタン1発でできるようにしていくと無限に処理するためのボタンが必要になってしまいます。以前、ワープロでほぼ全画面がボタンで埋め尽くされ文字を入力する部分が2行しかないという状態のパソコンを見たことがあります。
人には得手不得手があるのでコマンドを組み合わせて目的の処理を行うことが難しい場合があるかもしれません。それでも、いくつかのコマンドを使っていけば、ある日突然閃いて目的の処理ができるようになる可能性はあるかと思います。
では、また次回。
著者 仲村次郎
いろいろな事に手を出してみたものの結局身につかず、とりあえず目的の事ができればいいんじゃないかみたいな感じで生きております。