Grace Hopper氏にちなんで名づけられた2つのスーパーチップ
3月22日に開催されたGTC 2022で、NVIDIAは「Grace」と「Hopper」という2つのスーパーチップ(Superchip)を発表した。この名前は、米国の初期の計算機科学者でMark-Iのプログラミングなどに参加し、COBOLプログラム言語の開発などを行ったGrace Hopper氏にちなんで名づけられている。なお、Hopper氏は海軍に所属し、退役時には准将にまで昇進した。女性の海軍提督はこれまでに100人以上おられ、米国海軍ではそれほど珍しい存在ではない。
NVIDIAは以前からArm CPUを開発してきているが、本格的なデータセンタやスーパーコンピュータ(スパコン)用のCPUは作っておらず、今回のGrace Superchipが初めてである。NVIDIAが自社製のGrace CPUに一本化するのかどうかは発表されていないが、Amazonなどと同様に、少なくともデータセンタのCPUをIntelやAMDに依存する必要は無くなると思われる。
Grace CPUの概要
今回発表されたGraceは900GB/sの伝送速度の第4世代NVLinkを使用して複数のチップ、あるいはチップレットを接続するという造りになっている。第4世代NVLinkのバンド幅は通常のサーバの接続バンド幅の30倍であり、マルチチップのSuperchipの間の信号伝送の速度が速いことが特徴である。伝送速度が速くないとチップの能力が制限されてしまうので、この点は重要である。
Grace Superchipのシステムで特徴的なのは、メモリとしてLPDDR5x DRAMを使っている点である。LPDDR5xメモリはHBM3よりはメモリバンド幅は小さいが、メモリの個数を増やせばメモリバンド幅は増やせる。そして消費電力が小さく、ビット幅が広いので、エラー訂正のためのECCを付けるのも容易で、かつ、安価に実現できる。これは大きなメリットであると思われる。
LPDDR5xを使うメモリシステムは、DDR4と比較してバンド幅は2倍、エネルギー効率は10倍であり、1TB/sのメモリがCPUも含んで500Wの消費電力で実現できるという。
GraceのメモリシステムはシステムメモリとHBMメモリが同一のメモリ空間に存在するUnified cache coherence型になっており、プログラミングが容易であるというメリットがある。コヒーレンスをとるハードウェアが大変ということで、同一のメモリアドレスのメモリが複数できるタイプのメモリを作る例もしばしば見られるが、このようなメモリシステムは時間が経つと消えていっており、やはりUnified cache coherenceが良いようである。NVIDIAはこの点で王道を行ったと考えられる。
TSMCの4nmプロセスを採用
今回発表されたGrace Superchipは、TSMCの4nmプロセスである4Nプロセスを使用している。発売は2022年第3四半期とのことで、チップはほとんどできあがっているが、発売までには、いろいろなコーナーケースのテストをこなす必要があるという段階であると思われる。
Grace CPUは144個の高性能コアを搭載し、1TB/sのメモリを持つ。そしてサーバチップとしての性能とエネルギー効率は従来のサーバチップの2倍に改善しているという。
-

図1 Grace Superchipのイメージ。イメージから見てGrace Chipはアーチストの描画で写真ではないと思われる (提供:NVIDIA)

Grace CPUはArmのNeoverseアーキテクチャを採用したCPUで、AIインフラとHPC向けにフォーカスしたプロセサである。Grace CPU Superchipは最大8個のCPUが新しい高速、低レーテンシのリンクであるNVLink-C2Cでコヒーレントに接続されている。
CPUは144コアでSPECrate 2017_int_baseで推定740の性能を見込んでいる。これは現在のCPUでは16コアのシステムレベルの性能で、A100に使われているデュアルCPUと比べると2倍以上の性能である。
-

図2 NVIDIAのH100チップ。FP8をサポートし、4000TFlopsの性能を持つ。これもアーチストの描いたイメージで、写真ではないと思われる (これ以降の図はNVIDIA GTC基調講演のビデオキャプチャである)

FP8をサポートしたGPU「H100」
一方のHopperアーキテクチャベースのGPU「H100」は、A100の時代はサポートしていなかったFP8(8bit浮動小数点数)をサポートした。これはAI計算などではアルゴリズムの改善などにより、8bit精度でも役に立つ計算ができるケースが多く出てきたことによると考えられる。
H100チップのFP8による計算では計算性能は4000TFlopsで、A100の場合と比べると6倍の性能である。一方、FP16、TF32、FP64/FP32の性能は3倍である。

H100は最初のHopperベースのGPUで、TSMC 4Nプロセスの採用し、800億トランジスタ(80Bトランジスタ)を集積している。そして、PCIe Gen5、HBM3使用で768TB/sのメモリ帯域を実現している。
Grace Superchipの構成
Grace CPUはArm v9データセンタアーキテクチャのプロセサで、NVIDIAが使うかどうかは分からないが、富士通が富岳スパコンで採用したベクタ拡張命令も備えている。
-
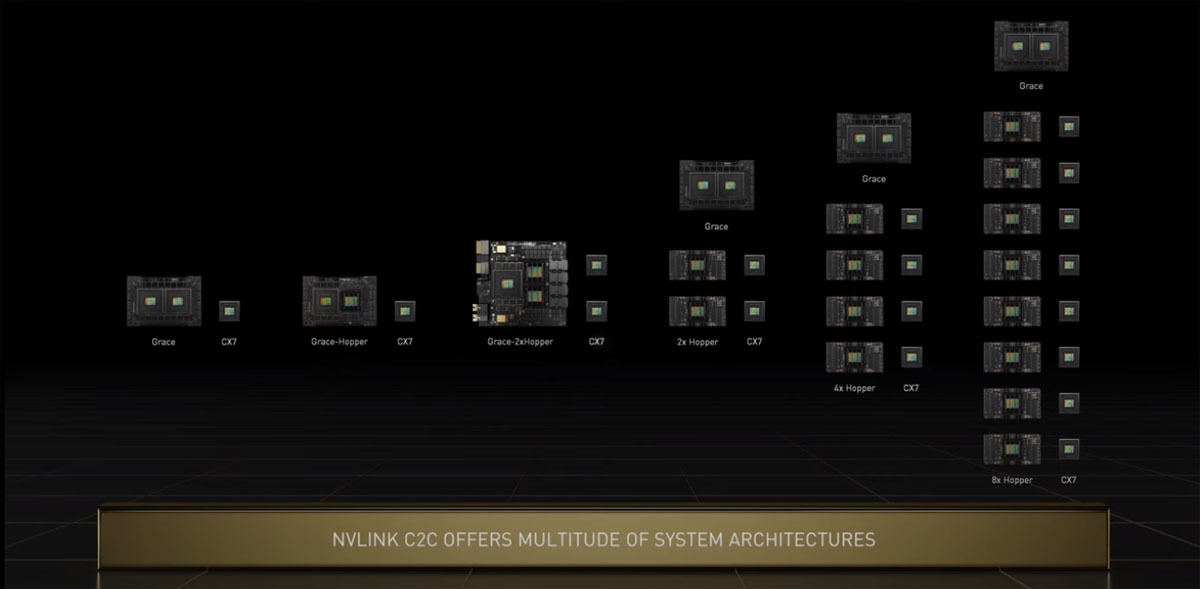
図3 Grace、HopperやCX-7 NICをNVLinkで接続すれば異なる構成のシステムが作れる。最大8個のHopperをつなげる

Grace SuperchipはGraceを1チップ、Hopperを1チップの合計2チップにCX-7を付けたCPUとNICというベーシックな構成とすることができる。また、GraceとHopper 2個にCX-7を2個、さらにGrace 2個、Hopper 2個、CX-7 2個という構成やGrace 2個にHopperとCX-7を各4個、Hopper 8個にCX-7を8個という構成にすることもできる。
Grace SuperchipはNVIDIAのComputing Software stackを実行できるのでCPUオンリーのサーバを作ることもできるし、Hopper GPUを付けてアクセラレーテッドサーバとすることもできる。
Grace SuperchipはHPC、AI、Data Analytic、Scientific ComputingやHyperscale Computingアプリケーションの実行にも優れている。構成の可変性が高いので、それらの実行に最大の性能を持ち、エネルギー効率が高い構成を作ることが可能である。
GraceとHopperはスイスのスパコンセンターであるCSCSの次期スパコンと米国のLos Alamos国立研究所の次期スパコンで採用される予定であり、GraceやHopperチップは2022年の前半に完成し、第3四半期から提供開始の予定である。
H100に搭載されたさまざまな新機能
DGX H100はH100チップを8基搭載するサーバである。DGX SuperPODは最大32台のDGX H100ノードがネットワーク接続される。SuperPODは8×32=256チップを搭載している。そして、NVIDIAのスパコンであるEOSは4608基のHopper GPUを搭載する576台のDGX H100システムで構成されることになる。
H100は前世代のA100のエンジンを改良し、前世代の6倍の高速化を達成し、結果として、FP8では4000TFlopsのピーク演算性能となっている。
また、H100はいろいろと新しい機能を搭載している。第2世代のSecure Multi-Instance GPU(MIG)テクノロジは単一のGPUを7つの独立のインスタンスに分割して使用できるようにする。そして、(それぞれのインスタンスの負荷に余裕がある場合は)7人のユーザにH100 GPUを使用できるようにする。
コンフィデンシャルコンピューティング機能は、処理中にAIモデルと顧客データを保護する機能で、マルチユーザの間の情報の漏洩を防ぐ。プライバシーに敏感な処理向けの機能である。
第4世代NVLinkは新しい外部スイッチと組み合わせるとサーバを超えたスケールアップネットワークとして使える。HDR Quantum Infinibandを使用する前世代製品と比べると、9倍の帯域幅で、最大256基のH100 GPUを接続する。
新しいDPX命令は、ルート最適化やゲノミクスを含む幅広いアルゴリズムで使用される動的計画法を、CPUと比較して最大40倍、前世代のGPUと比較して最大7倍高速化する。
H100の技術的革新は、AI推論とトレーニングにおけるNVIDIAのリーダーシップを拡張し、巨大なAIモデルを使用したリアルタイムのアプリケーションの実行を可能にする点である。
576台のDGX H100で構成されるスパコン「NVIDIA Eos」
576台のDGX H100システムで構成されるスーパーコンピュータ「NVIDIA Eos」は前世代と比較して、FP64では275PFlopsで3倍、In Network Computeは3.7PFlopsで36倍の性能となっている。また、AIではEOSは18.4EFLopsで、これも世界最大級であるという。
-

図4 NVIDIAの新スパコンのEOS。18.4 ExaFlopsのAI演算性能を持つEOSスパコンの外見。これも写真ではなく絵である

H100は、世界でもっとも強力なモノリシックTransformer言語モデルである530BパラメタのMegatronを使用したチャットボットを可能にし、リアルタイムの対話型AIに求められる1秒未満の遅延という制限を満たしながら、前世代のGPUの最大30倍のスループットを実現する。
NVIDIAは、この10年でGPUのAI処理性能を100万倍にしたという。175BパラメタのGPT-3のトレーニングはA100では5日かかったが、H100では19時間と6.3倍の性能になった。いろいろなエキスパートシステムの混合システムが、A100では学習に7日かかったがH100では20時間となり9倍の性能になった。Megatron 530Bパラメタのチャットボット2秒レーテンシのスループットが16倍、1.5秒レーテンシの場合は20倍のスループット、1秒の場合は30倍のスループットとなっており、レーテンシ制限値にもよるがH100ではA100の16倍~30倍の性能となっている。
-
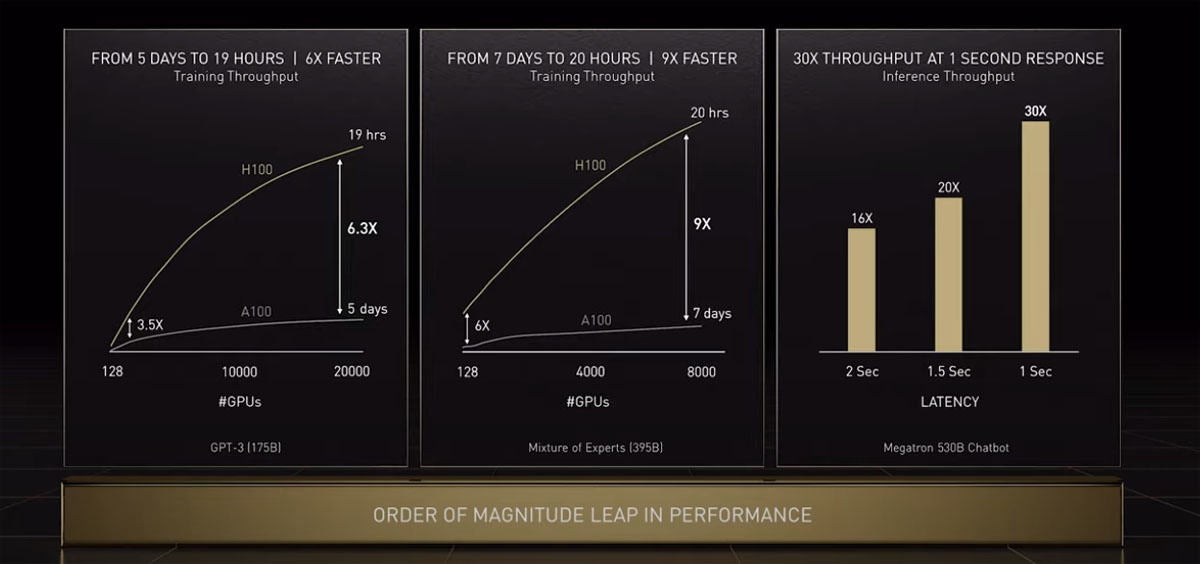
図5 GPT-3、各種エキスパートシステム、Megatronチャットボットの学習などのH100による高速化。A100と比べて、おおむね一桁程度の性能向上が得られている