


はじめに
本稿では、クラウド検索サービスであるAzure Searchを紹介します。検索サービスが提供する全文検索機能についての説明と、実際にAzure Search上に検索用データベースを構築してデータを検索できるようになるまでの手順について説明します。
Azure Searchとは
Azure Searchは全文検索機能を提供するPaaS(Platform as a Service)です。全文検索とはその名の通り全ての文を対象として検索を行うことで、RDBのwhere句のようにカラムを指定することなくデータを検索することが可能です。最も身近な全文検索の例としては、GoogleやBing等の検索エンジンサービスがあります。検索エンジンサービスでは検索キーワードをユーザが入力すると、そのキーワードがタイトルや本文中に含まれるWebサイトが検索結果として表示されます。全文検索では、このように各Webサイトの構造が全く異なるものであっても検索を可能とするために、検索対象データの保存方法と検索方法に工夫を施しています。


全文検索の機能
全文検索には、主に以下の表に挙げた機能が備わっています。
全文検索の機能
| 機能 | 説明 |
|---|---|
| フィルタリング | 特定の項目で検索対象データを絞り込む |
| インクリメンタルサーチ | 入力中の検索キーワードからリアルタイムに検索を行い、キーワードの予測をする |
| ヒット数のカウント | 検索結果として取得したデータの総数を取得する |
| ランキング | 検索結果を関連度の高い順に並び替える |
| ページング | 1ページでの検索結果の表示数を制限し、それ以降の結果を次のページで表示する |
| 検索ワードのハイライト | 検索時に使用したキーワードを検索結果上でハイライトする |
| 地理空間検索 | 緯度・経度を基にしたエリアの周辺情報の検索を行う |
ここで挙げた機能は、Azure Searchでもサポートしており、REST APIまたは.NET SDKを通じて使用することができます。 また、Azure Searchの機能のデモサイトでは、これらの機能が実際のWebサイト上でどのように使われているのかをガイダンス付きで紹介しているので、是非確認してみてください。
Azure Searchの特徴
Azure Searchは前述した全文検索の機能以外にも、いくつかの独自の機能や特徴をサポートしています。
・充実した自然言語解析
自然言語解析は、日本語のように人が用いる自然言語の文章を適切な単語に分割して全文検索で利用できるようにする処理です。Azure SearchではBingやOfficeといった他のMicrosoft製品でも使用され、実績のある自然言語解析ライブラリを使用することができます。
・完全マネージドな全文検索サービス
Azure Searchは、PaaSであることからインフラ部分の管理がAzureによって担保されているため、素早くサービスを開始することができます。
・他のAzureサービスとの統合
全文検索エンジンのデータストアにあたる「インデックス」の元データとしてSQL Database、Cosmos DBやBLOBストレージなどのAzureのデータベースサービスを選択することが可能です。これらのAzureのサービスをデータソースとして選択した場合は、Azure Searchからデータソースを自動でクロールしてインデックスにアップロードできます。クロールは、スケジュール指定での起動や、データソースの変更検知による起動から選択することができます。
・スケーラビリティ
Azure Searchのスケールには、検索に対するレスポンス性能のスケールと、データ容量に対するスケールの2種類のスケールがあります。
検索性能のスケールでは「レプリカ」と呼ばれるAzure Searchのインスタンスを増減させることで、多重の検索リクエストによる負荷の分散を行います。データ容量のスケールでは「パーティション」と呼ばれるAzure Searchのストレージの増減によって、インデックスに保存できるデータのサイズをスケールさせることができます。なお、レプリカとパーティションのスケールは、Azureポータルの画面上から簡単に行うことができます。
Azure Searchではこれらの機能や特徴によって、全文検索の専門的な知識なしでも比較的容易にな検索アプリの構築が可能となっています。またPaaSであるため、インフラ部分は完全マネージドのため運用管理コストも削減することができ、アプリ・サービス開発に集中できるようになっています。
全文検索の処理フロー(インデックス作成フロー)
次は、全文検索の処理フローを説明しながら、全文検索に用いられる用語の解説も行っていきます。 全文検索には、大きく2つのステップがあります。1つ目は全文検索の対象となるデータソースである「インデックス」の作成フロー、2つ目はユーザが検索キーワードを入力し実際に全文検索を行う検索フローです。
以下の図は、インデックス作成のフローです。
-

Azure Searchのインデックス作成フロー

(1)データソース
インデックスに保存するデータの元となるデータです。データソースはファイルやデータベースなど、様々なものを使用することができます。Azure SearchのインデックスにはJSON形式でデータを追加していくため、JSON形式に変換可能なデータであればデータソースとして使用することができます。
(2)インデクサー
データソースのデータは「インデクサー」にインポートします。インデクサーでは、データソースに含まれるテキストを「アナライザー」を使って加工し、インデックスに登録する単語に形式を整形する役割を持ちます。
Azure Searchの特徴でも触れたように、SQL DatabaseやCosmos DBなどの他のAzureサービスをデータソースとして選択した場合は、インデクサーは自動でこれらのデータソースからデータを取得するように設定することができます。このパターンを「プル型」と呼びます。一方でREST APIや.NET SDKを使ってプログラムから明示的にデータを追加する方法を「プッシュ型」と呼びます。プッシュ型の場合はデータソースの種類に制限はありません。
(3)アナライザー
「アナライザー」は前述の通りデータソースに含まれる文字列を単語の単位に分割したり、文字のゆらぎを正規化するなどしてインデックスに登録する形式にしていきます。アナライザーで処理された単語は一般的に「トークン」と呼ばれます。
なお、文字列を単語に分割する方法ですが、英語のようにスペースで単語を区切る文法の言語は簡単ですが、日本語のように単語同士が続いて文章となる文法の言語の場合は工夫が必要となります。Azure Searchでは、言語ごとの特徴に対応するために各言語に特化したアナライザーが用意されています。日本語の場合は「Luceneアナライザー」と「Microsoftアナライザー」の2種類からアナライザーを選択することができます。Luceneアナライザーは、Apache Luceneというオープンソースの全文検索ライブラリで使用されている日本語アナライザーです。Microsoftアナライザーはその名の通りMicrosoftが作成したアナライザーで、これはOffice製品やBingといった他のMicrosoft製品の中でも利用されています。
(4)インデックス
最後に「インデックス」ですが、インデックスはこれまでの説明の通りトークンを保存するためのAzure Search用のデータベースという位置づけです。全文検索のインデックスは「転置インデックス」と呼ばれるデータ構造でトークンを保存します。
転置インデックスは、キーにトークンが入り、値にそのトークンが含まれる文章やデータの宛先がリストで入っているデータ構造となっています。本の索引をイメージすると分かりやすいかと思います。転置インデックスは、あるキーワードが含まれるデータを探し出すことに特化しているため、全文検索のインデックスとして最適なデータ構造となっています。
また、Azure Searchのインデックスでは、検索した結果取得できるデータの最小単位を「ドキュメント」と呼びます。ドキュメントは複数のフィールドから構成されており、フィールドは名前や年齢などの項目で定義していきます。インデックスとドキュメント、フィールドは、RDBのテーブルと行、列とほぼ同じものと捉えることができます。
全文検索の処理フロー(検索フロー)
つづいて、ユーザーが検索を行う場合の処理フローを説明します。
-

Azure Searchの検索フロー

ユーザーが入力した検索キーワードは、「検索クエリ」と呼ばれるクエリ形式に整形してAzure Searchに渡します。検索クエリはまず「クエリパーサー」で処理されます。クエリパーサーは、クエリから取り出した検索キーワードをアナライザーに渡してトークン化し、Azure Search内部のクエリ形式である「クエリツリー」に変換して「検索エンジン」に渡します。 検索エンジンはクエリツリーを使ってインデックスからデータを取得します。検索エンジンは、データの取得後にデータを関連度順に並び替えするランキング処理を行い、ユーザに結果を返します。
AzureポータルからAzure Searchを操作しよう
ここからは、Azureポータル上でAzure Searchにインデックスを作成し、REST APIから検索ができるところまでの手順を説明します。今回はAzure Searchが用意しているサンプルデータをインデックスに取り込んでいきます。
Azure Searchサービスの作成
Azureポータルにログイン後、左側のメニューから「すべてのサービス」を選択し、検索フィールドに「search」と入力してAzure Searchを選択します。Searchサービスの画面に遷移後、追加ボタンから新たにSearchサービスを作成します。
-

「すべてのサービス」からAzure Searchを選択する

新規作成画面では、任意のURLとリソースグループを入力し、お手持ちのサブスクリプションを選択します。場所はSearchサービスのインスタンスの場所です。執筆時現在、日本では西日本のみ選択可能となっています。価格レベルは今回は無料の「Free」を選択します。価格レベルを変更することで、Searchサービスが利用できるインデックスの数、レプリカやパーティションの数も増減させることができます。
-

Searchサービスの新規作成画面

全ての項目を入力・選択後に「作成」ボタンでSearchサービスの新規作成を開始します。開始後しばらくすると作成が完了します。次はインデックスの作成です。インデックスはまず保存するドキュメントとそのフィールドの定義をし、その後で実際にデータをアップロードしていきます。
サンプルデータからインデックスを作成
作成したSearchサービスを選択し、Azure Searchのダッシュボード画面に移動します。ダッシュボードの上部にある「データのインポート」を選択します。
-

Azure Searchのダッシュボード画面

「データのインポート」からインデックスを作成する場合は、プル型でのインデックス作成方式となります。なおプッシュ型でインデックスを作成する場合は、「データのインポート」の左隣にある「インデックスの追加」からフィールド定義を行いインデックスを作成していきます。
「データのインポート」画面ではまずデータソースを選択します。「データソース」を選択すると接続可能なAzureのデータベースサービスが表示されます。今回はサンプルデータでインデックスを作成しますので、「サンプル」を選択し、「realestate-us-sample」というアメリカの物件情報のサンプルデータが入ったデータベースを選択します。
-

データソースからサンプルデータソースを選択

「選択」をクリックすると、「インデックス」の編集画面に移動します。ここの画面では、先ほど選択したデータソースからスキーマ情報を収集して、自動的にフィールド定義として表示してくれます。
-

インデックスのカスタマイズ画面

Cosmos DBのようにスキーマ定義を持たないデータソースを選択した場合は、表示されているフィールドに過不足が生じている可能性があるので、その場合は手動でフィールドの追加や削除を行って下さい。
フィールドでは、以下の項目を編集することができます。
フィールドに定義できる項目
| 項目名 | 説明 |
|---|---|
| 種類 | フィールドの型情報を選択する |
| 取得可能 | 検索結果データに含める場合にチェックを入れる |
| フィルター可能 | このフィールドで絞り込み検索をする場合にチェックを入れる |
| ソート可能 | このフィールドで並べ替えをする場合にチェックを入れる |
| ファセット可能 | ファセットナビゲーション(サイト側であらかじめ設定する、カテゴリー別、価格別、レビュー別等でフィルタリングした検索条件のナビゲーション)に含める場合にチェックを入れる |
| 検索可能 | ユーザからの検索時にヒットさせたいフィールドの場合にチェックを入れる |
また、フィールド定義の上部にある「アナライザー」にチェックを入れると、フィールドごとにアナライザーを変更することができるようになります。また「提案者」にチェックを入れてフィールドにもチェックを入れることで、そのフィールドをインクリメンタルサーチに対応させることができます。
今回はすべてデフォルトの状態で「OK」ボタンを選択します。「インデクサー」の作成画面に移動し、最後にインデクサーを作成します。必須項目のインデクサー名のみ入力して「OK」を選択します。今回は設定しませんが、任意項目の「スケジュール」では、このインデクサーの実行をスケジュール化し、定期的にインデックスを更新できるようにすることができます。また「詳細オプション」ではインデクサー実行時のエラーの許容回数などを指定することができます。
-

インデクサーの作成

インデクサーの作成後、「データのインポート」画面下部の「OK」ボタンを選択するとウィザードが終了し、Searchサービスのダッシュボード画面に戻ります。この間に、バックグラウンドではインデクサーが実行されてインデックスにデータが登録されています。インデクサーの実行履歴は、ダッシュボード画面の下部にある「インデクサー」から確認することができます。
-

インデクサーの実行履歴

ダッシュボード上のインデクサーを選択すると、インデクサーの実行結果画面に遷移します。
以下の図では実行結果がエラーとなっていますが、これはFreeプランでSearchサービスを作成した際の制約によるものです。Freeプランではインデクサー1回あたりの実行時間が1分に制限されてしまうため、データソースから全てのデータをインデックスにアップロードできずにエラーとして扱われてしまいました。
あくまでサンプルのインデックスであること、またサンプルデータソースにはデータが5000件含まれており、そのうちの数十件のみが取り込みに失敗しただけのため、今回はこのまま説明を続けます。Freeプランより上位のプランを使用すると、インデクサーは最大24時間稼働することができるので、本運用をされる場合はFree以外のプランを選択し、またエラーについては詳細を確認して対応されることをお薦めします。
-

インデクサーの実行結果

上記の通りプランの制約のため一部取り込めなかったデータもありますが、検索をするには十分の量のデータがインデックスにアップロードされました。
REST APIからAzure Searchを検索しよう
インデックスにデータを追加することができたのでREST APIを使って検索を行ってみましょう。Azureポータル上からREST APIの実行と結果の確認を行うことができます。Searchサービスのダッシュボードの上部にある「検索エクスプローラー」を選択すると簡易的な検索画面が表示されます。
-

検索エクスプローラー

「クエリ文字列」の部分に検索キーワードやクエリパラメータを入力して「検索」ボタンを選択すると検索が実行され、結果が画面下部の「結果」フィールドにJSON形式で出力されます。まず試しにクエリ文字列に「seattle」と入力して検索を実行してみましょう。
-
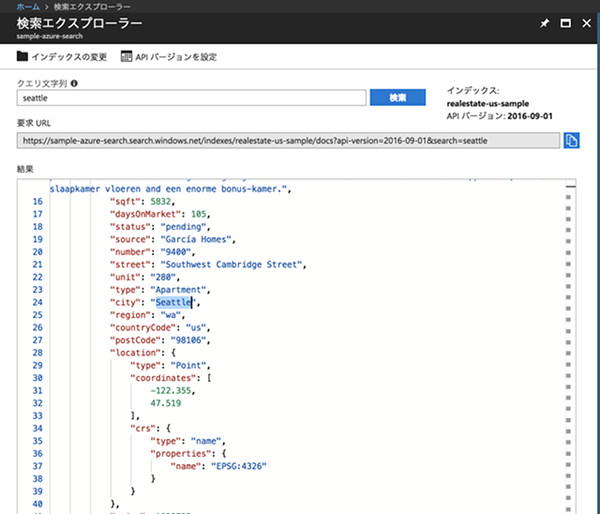
「seattle」での検索結果

実行するとJSONのデータが「結果」フィールドに表示されたかと思います。JSONデータを見ていくと、「city」のフィールドに「Seattle」という文字列があることが分かります。検索時にフィールドの指定はしていませんでしたが、都市がシアトルの物件情報を取得することができました。これが全文検索の特徴です。今回のサンプルデータでは「seattle」という文字列は全てcityフィールドに含まれていますが、仮にcity以外の検索可能なフィールドに「seattle」という文字列が入ったデータが存在する場合は、そのデータも取得することができたでしょう。
また、クエリ文字列に入力した文字は全て小文字の「seattle」であるのに対し、結果として取得されたデータ内の文字列は先頭が大文字の「Seattle」であることに注目して下さい。コンピュータからみるとこの2つの文字列は全く異なるものとなるため、そのまま検索をしてもヒットしません。この問題を解消しているのがアナライザーです。
アナライザーには処理の中で単語を小文字に変換する処理が含まれており、それをインデックスの作成時と検索時の双方で実施しているためAzure Searchの内部では全て小文字の「seattle」に統一されて検索が行われます。「sEAtTlE」のような大文字と小文字が混在した文字列で検索をした場合も同様の結果となることを確認してみましょう。取得されたデータの件数を確認できるクエリパラメータを付与し、「sEAtTlE&$count=true」という文字列で検索します。「@odata.count」というフィールドに取得件数が表示されますが、この件数が先ほどの全て小文字の場合の取得件数と同じになっているかと思います(全て小文字の場合の件数は「seattle&$count=true」で確認します)。
クエリ文字列にクエリパラメータを追加して、より細かい検索条件で検索を行ってみましょう。
「filter」を使用すると、指定した条件にマッチするデータのみ取得することができます。filterを使用する場合は対象のフィールドを指定する必要がある反面、比較演算子を使用することができるため絞り込みの条件を細かく調整する事が可能です。例えばベッドが2つ以上ある物件に絞り込んで検索する場合は、「$filter=beds ge 2」と入力します。比較演算子はシェルスクリプトで用いられる記法で記述します(geはgreater thanの意)。
取得するJSONデータを必要なフィールドのみに限定するには「select」を使用します。例えば物件の販売価格と外観写真のみを確認したい場合は、「$filter=beds ge 2&$select=price,thumbnail」と入力します。また価格の高い順に表示したい場合などのデータの並び替えには「orderby」を使用し、「$filter=beds ge 2&$select=price,thumbnail&$orderby=price desc」とクエリパラメータを追加していくことで対応することができます。
このように、必要に応じてクエリパラメータを付け足していくことで検索クエリを構築していきます。クエリパラメータの多くはSQLに近い文法や用途となっているため、SQLに馴染みのある方にとっては理解しやすいものとなっています。
まとめ
今回はAzure Searchを理解するための第一歩として、サンプルデータによるインデックスの作成とREST APIでのデータの検索を行いました。Azure Searchはクラウド検索サービスとして全文検索機能を使いやすく、また他のAzureサービスとの統合によって簡単に始められるように設計されたサービスであることが分かったかと思います。
次回はインメモリキャッシュであるRedisのクラウドサービスであるAzure Redis Cacheについて説明する予定です。
WINGSプロジェクト 秋葉龍一 著/山田祥寛監修
<WINGSプロジェクトについて>テクニカル執筆プロジェクト(代表山田祥寛)。海外記事の翻訳から、主にWeb開発分野の書籍・雑誌/Web記事の執筆、講演等を幅広く手がける。一緒に執筆をできる有志を募集中









